Балансировщик запросов DATA CLUSTER
- ОС: Windows, Linux
- СУБД: MS SQL Server, PostgreSQL
- Интенсивность запросов: 50 000+ запросов/сек.
- Может примененяться как в OLTP, так и в OLAP системах
- Свидетельство Роспатента № 2013618446 от 10.09.2013 г.
- Включён в Единый реестр российских программ для ЭВМ. Реестровая запись №3746 от 23.07.2017
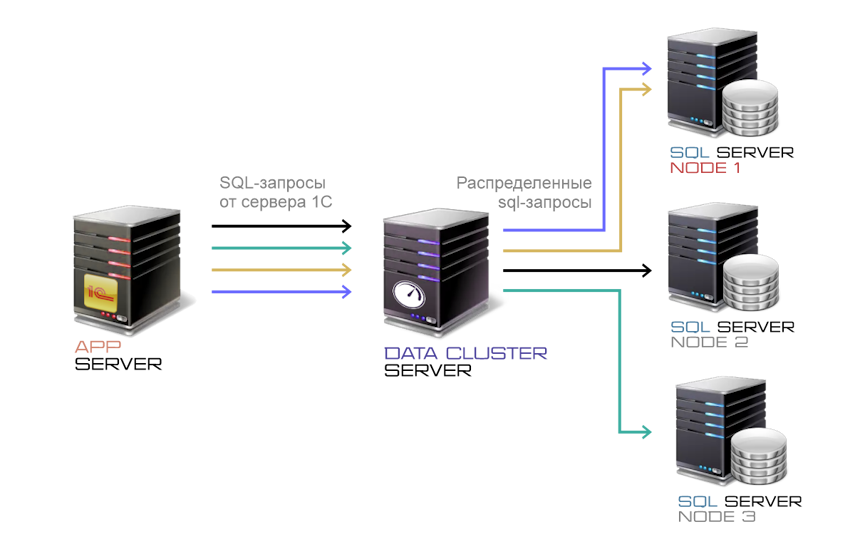
Data Cluster — это внешняя программа, представляет собой программный прокси-сервер , связывающий сервер приложений 1C:Предприятие и сервер баз данных. Выполняет потоковое сканирование трафика sql-запросов от сервера приложений и его балансировку между нодами кластера СУБД.
Для БД под управлением MS SQL Server требуется редакция Enterprise совместно с технологией AlwaysOn Availability Group.
Для БД под управлением PostgreSQL используется технология Streaming replication.
Применяется
- В системах с высокой конкуренцией за ресурсы сервера между группами «читающих» и «пишущих» sql-запросов, например, при формировании тяжёлых пользовательских отчётов.
- В системах со средней загрузкой CPU и памяти сервера баз данных выше 50%, что в период пиковой нагрузки (сезон продаж, формирование отчётности и др.) может приводить к простоям системы – сервер и база данных на время становятся не функциональны.
Позволяет
- Снять избыточную нагрузку с основной ноды кластера СУБД путем автоматического распределения части запросов на чтение между дополнительными экземплярами кластера СУБД в режиме реального времени.
- Перенаправлять отдельные пользовательские операции, связанные с запросами на чтение (например тяжелые отчеты, закрытие месяца и т.п.) на вторичную ноду, чтобы ускорить их выполнение и не создавать дополнительную нагрузку на основном сервере.
- Снизить затраты на аппаратную модернизацию севера баз данных – покупать более «мощный» сервер теперь не потребуется.
Безопасность
- DATA CLUSTER был создан для высоконагруженных систем и спокойно обрабатывает поток 80 тыс. запросов в секунду.
- Балансировку можно в любой момент отключить. В этом случае сервер SDC будет работать в прокси-режиме, пропуская все запросы только на основную ноду.
- Вы покупаете продукт только после того как совместно с нами успешно проведете испытание в продуктивной среде.
Архитектура
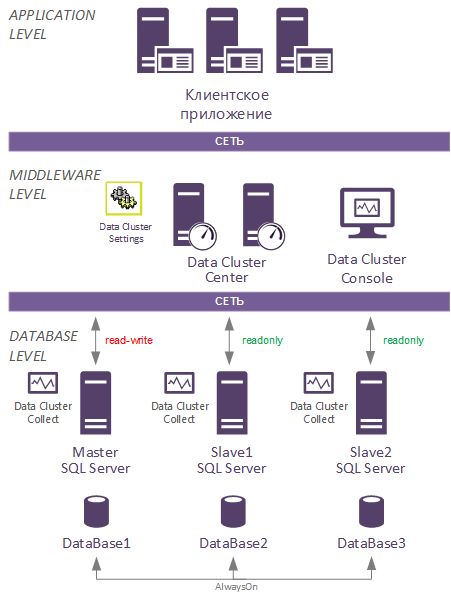
Состав компонент Data Cluster
DATA CLUSTER – служба, выполняющая интеллектуальную маршрутизацию SQL-запросов между экземплярами баз данных в кластере (Always On Availability Group).
Рекомендуется устанавливать на отдельный сервер.
1. DATA CLUSTER Center – служба, которая собирает информацию от всех агентов сбора данных DATA CLUSTER Collect и предоставляет её DATA CLUSTER. Рекомендуется устанавливать на том же сервере, где будет развернут DATA CLUSTER.
2. DATA CLUSTER Collect – служба, поставляющая служебную информацию о состоянии сервера баз данных в DATA CLUSTER Center. Устанавливается на серверные экземпляры баз данных кластера (Always On Availability Group).
3. DATA CLUSTER Settings — программа, позволяющая менять режимы работы DATA CLUSTER Center и проводить его тонкую настройку. Приложение устанавливается вместе с DATA CLUSTER Center.
4. DATA CLUSTER Console — программа, предоставляющая администратору сведения о состоянии всех процессов интеллектуальной маршрутизации SQL-запросов, в табличном и графическом виде, а также возможность управления некоторыми функциями DATA CLUSTER Center. Приложение устанавливается вместе с DATA CLUSTER Center, может запускаться с любого компьютера, у которого есть доступ по сети к DATA CLUSTER Center.
Принцип работы DATA CLUSTER
Функции службы мониторинга Softpoint Data Cluster (SDC:)
- Отслеживает потаблично синхронность данных в базах Master- и Slave-серверов кластера, время рассинхронизации;
- Контролирует доступность Master- и Slave-серверов кластера, анализирует загрузку ресурсов CPU и RAM.
Функции службы балансировщика:
- Сканирует весь трафик sql-запросов, выделяет из них целевую группу – на чтение данных вне транзакции;
- Распределяет часть запросов целевой группы по Slave-серверам кластера, при условии синхронности таблиц, по которым происходит обращение к данным;
- Запросы на изменение данных и любые запросы в транзакции отправляет исключительно на Master-сервер кластера.
Функции оптимизатора запросов (дополнительный модуль QProcessing, может поставляться как отдельный продукт исключительно для решения задач модификации запросов «на лету»):
- Сканирует весь трафик sql-запросов, выделяет из них те запросы, которые попадают под правила модификации.
- Изменяет текст отфильтрованных sql-запросов согласно правилам модификации и передает их для выполнения на сервер СУБД (нужную ноду).
Внедрение Data Cluster состоит из 3-х этапов.
Этап 1. Общая диагностика
- Общая диагностика производительности целевой базы данных и инфраструктуры
- Расчёт эффекта применения Data Cluster для целевой базы данных
- Формирование списка инфраструктурных изменений в системе.
По результатам диагностики заказчик получает аргументированное заключение и принимает взвешенное решение о переходе к следующему этапу.
Это необходимый этап внедрения, поскольку некоторые ИТ-системы могут быть не готовы к балансировке как в части аппаратной составляющей, так и в части особенностей работы приложения.
Этап 2. Внедрение и настройка
- Подготовка инфраструктуры для внедрения в соответствии с разработанными требованиями;
- Установка и настройка компонентов Data Cluster, перевод системы в режим работы Data Cluster.
Этап 3. Передача в эксплуатацию
- Комплексный мониторинг производительности целевой базы данных и инфраструктуры.
- Анализ производительности системы в режим работы Data Cluster – подтверждение расчётного эффекта.
- Обучение администрированию Data Cluster, передача на поддержку системным администраторам.
Важно!
Общая диагностика проводится в рамках предпродажной подготовки и не требует оплаты. Заявка на проведение оформляется анкетой, которую Вы можете скачать, заполнить и оправить на электронный адрес softpoint@softpoint.ru. В теме письма следует указать: "Data Cluster – заявка на общую диагностику".
Обращаем Ваше внимание, обезличенные заявки не рассматриваются.
Общая диагностика проводится дистанционно, но без доступа к инфраструктуре заказчика. Сбор требуемой статистики проводится при помощи Программы для ЭВМ PerfExpert – предоставляется лицензия на 14 календарных дней.
Для выполнения последующих этапов стороны подписывают рамочный лицензионный договор и согласуют спецификацию на закупку лицензий, оплата которых проводится после подтверждения расчётного эффекта внедрения Data Cluster.
DATA CLUSTER поставляется в редакциях Standard, Enterprise и Corporate.
Схема лицензирования учитывает количество подключаемых к балансировщику баз данных на сервере, а также количество одновременных sql-сессий (для MS SQL Server).
Лицензии Data Cluster для MS SQL Server под Windows

Standard
Базовая лицензия, позволяет подключить к DATA CLUSTER одну базу данных на сервере СУБД дляограниченного количества одновременных sql-сессий.
от 375 000 ₽/год
в зависимости от максимального количества одновременных sql-сессий
Enterprise
Основная лицензия, позволяет подключить к DATA CLUSTER весь сервер СУБД с неограниченным количеством баз на нем и с любым количеством одновременных sql-сессий.
1 080 000 ₽/год
Стоимость любого выбранного Вами тарифа включает использование модуля модификации запросов QProcessing. Внедрение модуля рассматривается как отдельная задача и согласовывается в индивидуальном порядке.
Для предварительно оценки количества sql-сессий к каждому серверу БД можно воспользоваться скриптом – выполнить его в SQL Server Management Studio, желательно в период максимальной активности на сервере. Для повышения точности оценки его можно выполнять несколько раз в течение дня.
select program_name, count(*)
from sys.sysprocesses
where spid > 50
group by program_nameЛицензии PerfExpert для PostgreSQL под Linux

Standard
Базовая лицензия, позволяет подключить к DATA CLUSTER одну базу данных и ее экземпляры в кластере серверов СУБД.
595 000 ₽/год
Corporate
Основная лицензия, позволяет подключить к DATA CLUSTER неограниченное количество баз данных на неограниченном количестве кластеров СУБД организации
1 490 000 ₽/год
Стоимость любого выбранного Вами тарифа включает использование модуля модификации запросов QProcessing. Внедрение модуля рассматривается как отдельная задача и согласовывается в индивидуальном порядке.
Кто уже активно пользуется DATA CLUSTER