
Записки оптимизатора 1С (часть 5). Ускорение RLS-запросов в 1С системах

Замахнемся сегодня на RLS. Обсуждать будем проблемы по нашему профилю, связанные с производительностью 1С:Предприятие. Но, в целом, этот материал может быть полезен и не только 1С-никам.
Немного о RLS
RLS (не РЛС) – это, напомню, ограничение доступа к данным на уровне записей – Row Level Security. То есть администратор открывает пользователю доступ к какому-либо объекту, но не ко всем его элементам (записям), а лишь к некоторым.
Если на уровне обычных ролей можно разрешить/запретить доступ ко всему объекту целиком, например, ко всем документам «Реализация товаров и услуг». То с механизмом RLS можно разрешить/запретить просматривать и изменять документы более тонко, например, только по определенным контрагентам, и только за определенный период. Вариаций бесконечное множество.
Инструмент призван решать как задачи безопасности данных – пользователь не сможет испортить данные, за которые он не отвечает, так и задачи конфиденциальности – пользователь не увидит то, что ему не положено видеть.
К сожалению, боли этот механизм доставляет очень много. И пользователям, и администраторам. Первые страдают от того, что у них все безбожно тормозит и работать иногда просто невозможно. А вторые пребывают в шоке от поддержки всего этого хозяйства разграничения прав на плаву и попыток как-то ускорить работу пользователей. Чем больше пользователей, объектов системы, тем больше требуется шаблонов для правильной раздачи прав. И растёт это как снежный ком. Шаблоны и роли в какой-то момент начинают накладываться друг на друга, конфликтовать. Один и тот же отчет у одних пользователей работает, у вторых работает медленнее на порядки, а у третьих вообще не работает, и поддержка RLS превращается в сущий кошмар.
Это проблематика в двух словах. Копать дальше в руду не будем. Просто знаем, что есть расширенные настройки ролей 1С с собственным языком запросов и конструктором для настройки шаблонов ограничений, которые затем платформа 1С трансформирует в довольно громоздкие sql-запросы.
Почему запросы с RLS очень часто такие долгие?
Основная причина одна – неоптимальный план выполнения запросов. А вот почему он неоптимальный давайте разбираться.
Первое, на что следует обратить – это неактуальная статистика. Про это написано много статей. Статистика предоставляет информацию о том, какой объем данных нужно будет обработать при выполнении запроса. Один и тот же запрос на разных объемах данных будет использовать разные планы запросов. На маленьких объёмах – обработка попроще, а на миллионах строк будет совсем другой способ. Соответственно, неактуальные статистики могут привести к неправильной стоимостной оценки операций в запросе и к неправильному плану выполнения запроса и, в том числе, к неправильно используемым индексам и видам соединений.
Поэтому важно иметь всегда актуальные статистики, а значит должен быть правильно настроен регламент по их пересчету. Качественное и своевременное обновление статистики – условие, в принципе, необходимое для работы базы данных, и часто помогает. Но в случае RLS, по нашему опыту, бывает редко.
Куда более важный аспект, на который стоит обратить внимание – это неверный план запроса из-за нехватки времени на его поиск. По нашему опыту это одна из основных причин увеличения длительности запросов с RLS.
Ограничения, накладываемые в шаблоне, приводят к огромному количеству соединений между таблицами. На уровне СУБД это выглядит примерно так:

Очень много левых соединений – внешних, внутренних, вложенных. Их может быть сотни и даже тысячи. Такие запросы могут стать просто монструозными и занимать тысячи строк кода. Мы в своей практике встречали запрос с текстом на 4 Мб(!). Выполнялся он крайне неторопливо.
Один и тот же запрос с RLS может выполняться в разное время по-разному. Иногда довольно быстро – за доли или единицы секунд, а иногда совсем приунывает, и выполняется минуты, десятки минут. Ситуация в таких громоздких запросах слабо предсказуемая и, как правило, связана с временем ожидания оптимизатора запроса SQL Server. Оптимизатор запросов выбирает план выполнения запроса с наименьшими затратами после создания и оценки нескольких планов запросов. Оптимизатор тратит на подбор подходящего плана ограниченное время, которое должно быть (и есть) сильно меньше длительности выполнения самого запроса. Оптимизатор перебирает различные комбинации выполнения частей запроса и должен выбрать самую оптимальную. Чем больше таблиц, и соединений между ними, тем больше комбинаций выполнения запроса будет в плане. Оптимизатор оперирует множеством факторов, среди которых:
- Использование индексов: кластеризованные, некластеризованные, просто таблицы.
- Метод поиска: Index Seek, Index Scan, Table Scan.
- Метод физического соединения: Nested Loops, Hash Join, Merge Join.
- Выполнение частей запроса параллельно или последовательно.
Соответственно, если оптимизатор не успевает перебрать все возможные комбинации, то выбранный план запроса может оказаться далеко не самым оптимальным. Именно этим и объясняется такой разброс по времени выполнении одного и того же запроса.
Посмотрите на рисунок ниже. На нем приведена трасса Reads из мониторинга Perfexpert (запросы с более 50 тыс. лог. чтений) по очень ненагруженной системе 1С, но в которой используется RLS.
Для примера возьмем запрос с хешем MD5 12391214314792349318. За четыре дня он попался в трассу 19 раз.

Это точно запрос с RLS. Вот его полный текст:
Текст запроса MD5 12391214314792349318
EXEC sp_executesql
N'SELECT CASE
WHEN T1.Q_001_F_000_TYPE = 0x08
THEN T1.Q_001_F_000_RTRef
END
,CASE
WHEN T1.Q_001_F_000_TYPE = 0x08
THEN T1.Q_001_F_000_RRRef
WHEN T1.Q_001_F_000_TYPE IN (0x08)
THEN 0x00000000000000000000000000000000
END
,0x03
,T1.Q_001_F_001_
,@P1
,T1.Q_001_F_002_
,CASE
WHEN T1.Q_001_F_003_TYPE = 0x08
AND T1.Q_001_F_003_RTRef = 0x000000DF
THEN T1.Q_001_F_003_RRRef
END
,CASE
WHEN T1.Q_001_F_004_TYPE = 0x08
AND T1.Q_001_F_004_RTRef = 0x000000A8
THEN T1.Q_001_F_004_RRRef
END
,CASE
WHEN T1.Q_001_F_005_TYPE = 0x08
AND T1.Q_001_F_005_RTRef = 0x000003AD
THEN T1.Q_001_F_005_RRRef
END
,CASE
WHEN T1.Q_001_F_006_TYPE IN (0x05)
THEN T1.Q_001_F_006_TYPE
WHEN T1.Q_001_F_006_TYPE = 0x08
AND T1.Q_001_F_006_RTRef = 0x0000012B
THEN 0x08
END
,CASE
WHEN T1.Q_001_F_006_TYPE = 0x05
THEN CAST(T1.Q_001_F_006_S AS NVARCHAR(150))
WHEN T1.Q_001_F_006_TYPE IN (0x08)
THEN @P2
END
,CASE
WHEN T1.Q_001_F_006_TYPE = 0x08
AND T1.Q_001_F_006_RTRef = 0x0000012B
THEN T1.Q_001_F_006_RRRef
WHEN T1.Q_001_F_006_TYPE IN (0x05)
THEN 0x00000000000000000000000000000000
END
,CASE
WHEN T1.Q_001_F_007_TYPE = 0x08
AND T1.Q_001_F_007_RTRef = 0x0000C54D
THEN T1.Q_001_F_007_RRRef
END
,CASE
WHEN T1.Q_001_F_008_TYPE = 0x08
AND T1.Q_001_F_008_RTRef = 0x0000C52D
THEN T1.Q_001_F_008_RRRef
END
,CASE
WHEN T1.Q_001_F_009_TYPE = 0x03
THEN T1.Q_001_F_009_N
END
,CASE
WHEN T1.Q_001_F_010_TYPE = 0x08
AND T1.Q_001_F_010_RTRef = 0x000000DF
THEN T1.Q_001_F_010_RRRef
END
,CASE
WHEN T1.Q_001_F_011_TYPE = 0x05
THEN CAST(T1.Q_001_F_011_S AS NVARCHAR(400))
END
,T1.Q_001_F_012_
,CAST(T1.Q_001_F_013_ AS NVARCHAR(52))
,CASE
WHEN T1.Q_001_F_014_TYPE IN (0x05)
THEN T1.Q_001_F_014_TYPE
WHEN T1.Q_001_F_014_TYPE = 0x08
AND T1.Q_001_F_014_RTRef = 0x0000BFFD
THEN 0x08
END
,CASE
WHEN T1.Q_001_F_014_TYPE = 0x05
THEN T1.Q_001_F_014_S
WHEN T1.Q_001_F_014_TYPE IN (0x08)
THEN @P3
END
,CASE
WHEN T1.Q_001_F_014_TYPE = 0x08
AND T1.Q_001_F_014_RTRef = 0x0000BFFD
THEN T1.Q_001_F_014_RRRef
WHEN T1.Q_001_F_014_TYPE IN (0x05)
THEN 0x00000000000000000000000000000000
END
,CASE
WHEN T1.Q_001_F_015_TYPE = 0x04
THEN T1.Q_001_F_015_T
END
FROM (
SELECT DISTINCT TOP 1000 CAST(NULL AS BINARY (1)) AS Q_001_F_000_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_000_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_000_N
,CAST(NULL AS DATETIME) AS Q_001_F_000_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_000_S
,CAST(NULL AS VARBINARY) AS Q_001_F_000_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_000_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_000_RRRef
,@P4 AS Q_001_F_001_
,@P5 AS Q_001_F_002_
,CAST(NULL AS BINARY (1)) AS Q_001_F_003_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_003_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_003_N
,CAST(NULL AS DATETIME) AS Q_001_F_003_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_003_S
,CAST(NULL AS VARBINARY) AS Q_001_F_003_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_003_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_003_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_004_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_004_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_004_N
,CAST(NULL AS DATETIME) AS Q_001_F_004_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_004_S
,CAST(NULL AS VARBINARY) AS Q_001_F_004_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_004_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_004_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_005_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_005_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_005_N
,CAST(NULL AS DATETIME) AS Q_001_F_005_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_005_S
,CAST(NULL AS VARBINARY) AS Q_001_F_005_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_005_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_005_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_006_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_006_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_006_N
,CAST(NULL AS DATETIME) AS Q_001_F_006_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_006_S
,CAST(NULL AS VARBINARY) AS Q_001_F_006_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_006_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_006_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_007_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_007_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_007_N
,CAST(NULL AS DATETIME) AS Q_001_F_007_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_007_S
,CAST(NULL AS VARBINARY) AS Q_001_F_007_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_007_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_007_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_008_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_008_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_008_N
,CAST(NULL AS DATETIME) AS Q_001_F_008_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_008_S
,CAST(NULL AS VARBINARY) AS Q_001_F_008_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_008_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_008_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_009_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_009_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_009_N
,CAST(NULL AS DATETIME) AS Q_001_F_009_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_009_S
,CAST(NULL AS VARBINARY) AS Q_001_F_009_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_009_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_009_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_010_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_010_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_010_N
,CAST(NULL AS DATETIME) AS Q_001_F_010_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_010_S
,CAST(NULL AS VARBINARY) AS Q_001_F_010_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_010_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_010_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_011_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_011_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_011_N
,CAST(NULL AS DATETIME) AS Q_001_F_011_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_011_S
,CAST(NULL AS VARBINARY) AS Q_001_F_011_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_011_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_011_RRRef
,0x00 AS Q_001_F_012_
,@P6 AS Q_001_F_013_
,CAST(NULL AS BINARY (1)) AS Q_001_F_014_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_014_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_014_N
,CAST(NULL AS DATETIME) AS Q_001_F_014_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_014_S
,CAST(NULL AS VARBINARY) AS Q_001_F_014_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_014_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_014_RRRef
,CAST(NULL AS BINARY (1)) AS Q_001_F_015_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_015_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_015_N
,CAST(NULL AS DATETIME) AS Q_001_F_015_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_015_S
,CAST(NULL AS VARBINARY) AS Q_001_F_015_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_015_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_015_RRRef
WHERE 1 = 0
ORDER BY 93
,94
,95
,96
,97
,98
,99
,100
) T1
UNION ALL
SELECT 0x0000D329
,T2.Q_001_F_000RRef
,0x05
,@P7
,T2.Q_001_F_001_
,T2.Q_001_F_002_
,T2.Q_001_F_003RRef
,T2.Q_001_F_004RRef
,T2.Q_001_F_005RRef
,0x08
,@P8
,T2.Q_001_F_006RRef
,T2.Q_001_F_007RRef
,T2.Q_001_F_008RRef
,T2.Q_001_F_009_
,T2.Q_001_F_010RRef
,T2.Q_001_F_011_
,T2.Q_001_F_012_
,CAST(T2.Q_001_F_013_ AS NVARCHAR(52))
,T2.Q_001_F_014_TYPE
,T2.Q_001_F_014_S
,T2.Q_001_F_014_RRRef
,T2.Q_001_F_015_
FROM (
SELECT TOP 1000 T3._IDRRef AS Q_001_F_000RRef
,T3._Number AS Q_001_F_001_
,T3._Date_Time AS Q_001_F_002_
,T3._Fld54077RRef AS Q_001_F_003RRef
,T3._Fld54074RRef AS Q_001_F_004RRef
,T3._Fld54082RRef AS Q_001_F_005RRef
,T3._Fld54083RRef AS Q_001_F_006RRef
,T4.Fld50826RRef AS Q_001_F_007RRef
,T4.Fld50828RRef AS Q_001_F_008RRef
,T4.Fld50827_ AS Q_001_F_009_
,T4.Fld50825RRef AS Q_001_F_010RRef
,T3._Fld54080 AS Q_001_F_011_
,CASE
WHEN (NOT (((T4.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P9 AS Q_001_F_013_
,CASE
WHEN T12._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T12._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T12._Q_001_F_001_TYPE IS NULL
THEN @P10
ELSE T12._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T12._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T12._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T3._Date_Time AS Q_001_F_015_
FROM dbo._Document54057X1 T3
LEFT OUTER JOIN (
SELECT T7._Fld50828RRef AS Fld50828RRef
,T7._Fld50826RRef AS Fld50826RRef
,T7._Fld56279RRef AS Fld56279RRef
,T7._Fld50824_TYPE AS Fld50824_TYPE
,T7._Fld50824_RTRef AS Fld50824_RTRef
,T7._Fld50824_RRRef AS Fld50824_RRRef
,T7._Fld50827 AS Fld50827_
,T7._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T6._Fld50824_TYPE AS Fld50824_TYPE
,T6._Fld50824_RTRef AS Fld50824_RTRef
,T6._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T6._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T6
GROUP BY T6._Fld50824_TYPE
,T6._Fld50824_RTRef
,T6._Fld50824_RRRef
) T5
INNER JOIN dbo._InfoRg50823X1 T7 ON T5.Fld50824_TYPE = T7._Fld50824_TYPE
AND T5.Fld50824_RTRef = T7._Fld50824_RTRef
AND T5.Fld50824_RRRef = T7._Fld50824_RRRef
AND T5.MAXPERIOD_ = T7._Period
) T4 ON (
0x08 = T4.Fld50824_TYPE
AND 0x0000D329 = T4.Fld50824_RTRef
AND T3._IDRRef = T4.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T11._Fld50704RRef AS Fld50704RRef
,T11._Fld50703_TYPE AS Fld50703_TYPE
,T11._Fld50703_RTRef AS Fld50703_RTRef
,T11._Fld50703_RRRef AS Fld50703_RRRef
,T11._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T10._Fld50703_TYPE AS Fld50703_TYPE
,T10._Fld50703_RTRef AS Fld50703_RTRef
,T10._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T10._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T10
GROUP BY T10._Fld50703_TYPE
,T10._Fld50703_RTRef
,T10._Fld50703_RRRef
) T9
INNER JOIN dbo._InfoRg50702X1 T11 ON T9.Fld50703_TYPE = T11._Fld50703_TYPE
AND T9.Fld50703_RTRef = T11._Fld50703_RTRef
AND T9.Fld50703_RRRef = T11._Fld50703_RRRef
AND T9.MAXPERIOD_ = T11._Period
) T8 ON (
0x08 = T8.Fld50703_TYPE
AND 0x0000D329 = T8.Fld50703_RTRef
AND T3._IDRRef = T8.Fld50703_RRRef
)
AND (T8.Fld50705RRef = @P11)
LEFT OUTER JOIN #tt59 T12 WITH (NOLOCK) ON (T3._Fld54083RRef
= T12._Q_001_F_000RRef)
AND (
(T3._Date_Time >= T12._Q_001_F_002)
AND (T3._Date_Time <= T12._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T13 ON T4.Fld50828RRef = T13._IDRRef
WHERE T3._Posted = 0x01
AND T4.Fld50828RRef IN (
SELECT T14._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T14 WITH (NOLOCK)
)
AND (
T4.Fld50828RRef IN (
SELECT T15._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T15 WITH (NOLOCK)
)
AND (T4.Fld50826RRef = @P12)
OR T13._ParentIDRRef IN (
SELECT T16._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T16 WITH (NOLOCK)
)
AND (T4.Fld50826RRef = @P13)
OR T4.Fld56279RRef IN (
SELECT T17._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T17 WITH (NOLOCK)
)
AND (T4.Fld50826RRef = @P14)
)
AND (
(T8.Fld50704RRef = @P15)
OR @P16 IN (
SELECT T18._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T18
WHERE (T18._Fld50691RRef = T4.Fld50828RRef)
AND (
T18._Fld50690_TYPE = 0x08
AND T18._Fld50690_RTRef = 0x0000D329
AND T18._Fld50690_RRRef = T3._IDRRef
)
)
AND (T4.Fld50826RRef = @P17)
OR @P18 IN (
SELECT T19._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T19
WHERE (
(T19._Fld50691RRef = T13._ParentIDRRef)
OR (T19._Fld50691RRef = T4.Fld56279RRef)
)
AND (
T19._Fld50690_TYPE = 0x08
AND T19._Fld50690_RTRef = 0x0000D329
AND T19._Fld50690_RRRef = T3._IDRRef
)
)
AND (T4.Fld50826RRef = @P19)
)
ORDER BY (T3._Date_Time)
) T2
UNION ALL
SELECT 0x0000CD06
,T20.Q_001_F_000RRef
,0x05
,@P20
,T20.Q_001_F_001_
,T20.Q_001_F_002_
,T20.Q_001_F_003RRef
,T20.Q_001_F_004RRef
,T20.Q_001_F_005RRef
,0x08
,@P21
,T20.Q_001_F_006RRef
,T20.Q_001_F_007RRef
,T20.Q_001_F_008RRef
,T20.Q_001_F_009_
,T20.Q_001_F_010RRef
,T20.Q_001_F_011_
,T20.Q_001_F_012_
,CAST(T20.Q_001_F_013_ AS NVARCHAR(52))
,T20.Q_001_F_014_TYPE
,T20.Q_001_F_014_S
,T20.Q_001_F_014_RRRef
,T20.Q_001_F_015_
FROM (
SELECT TOP 1000 T21._IDRRef AS Q_001_F_000RRef
,T21._Number AS Q_001_F_001_
,T21._Date_Time AS Q_001_F_002_
,T21._Fld52513RRef AS Q_001_F_003RRef
,T21._Fld52510RRef AS Q_001_F_004RRef
,T21._Fld52518RRef AS Q_001_F_005RRef
,T21._Fld52519RRef AS Q_001_F_006RRef
,T22.Fld50826RRef AS Q_001_F_007RRef
,T22.Fld50828RRef AS Q_001_F_008RRef
,T22.Fld50827_ AS Q_001_F_009_
,T22.Fld50825RRef AS Q_001_F_010RRef
,T21._Fld52516 AS Q_001_F_011_
,CASE
WHEN (NOT (((T22.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P22 AS Q_001_F_013_
,CASE
WHEN T30._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T30._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T30._Q_001_F_001_TYPE IS NULL
THEN @P23
ELSE T30._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T30._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T30._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T21._Date_Time AS Q_001_F_015_
FROM dbo._Document52486X1 T21
LEFT OUTER JOIN (
SELECT T25._Fld50828RRef AS Fld50828RRef
,T25._Fld50826RRef AS Fld50826RRef
,T25._Fld56279RRef AS Fld56279RRef
,T25._Fld50824_TYPE AS Fld50824_TYPE
,T25._Fld50824_RTRef AS Fld50824_RTRef
,T25._Fld50824_RRRef AS Fld50824_RRRef
,T25._Fld50827 AS Fld50827_
,T25._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T24._Fld50824_TYPE AS Fld50824_TYPE
,T24._Fld50824_RTRef AS Fld50824_RTRef
,T24._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T24._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T24
GROUP BY T24._Fld50824_TYPE
,T24._Fld50824_RTRef
,T24._Fld50824_RRRef
) T23
INNER JOIN dbo._InfoRg50823X1 T25 ON T23.Fld50824_TYPE = T25._Fld50824_TYPE
AND T23.Fld50824_RTRef = T25._Fld50824_RTRef
AND T23.Fld50824_RRRef = T25._Fld50824_RRRef
AND T23.MAXPERIOD_ = T25._Period
) T22 ON (
0x08 = T22.Fld50824_TYPE
AND 0x0000CD06 = T22.Fld50824_RTRef
AND T21._IDRRef = T22.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T29._Fld50704RRef AS Fld50704RRef
,T29._Fld50703_TYPE AS Fld50703_TYPE
,T29._Fld50703_RTRef AS Fld50703_RTRef
,T29._Fld50703_RRRef AS Fld50703_RRRef
,T29._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T28._Fld50703_TYPE AS Fld50703_TYPE
,T28._Fld50703_RTRef AS Fld50703_RTRef
,T28._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T28._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T28
GROUP BY T28._Fld50703_TYPE
,T28._Fld50703_RTRef
,T28._Fld50703_RRRef
) T27
INNER JOIN dbo._InfoRg50702X1 T29 ON T27.Fld50703_TYPE = T29._Fld50703_TYPE
AND T27.Fld50703_RTRef = T29._Fld50703_RTRef
AND T27.Fld50703_RRRef = T29._Fld50703_RRRef
AND T27.MAXPERIOD_ = T29._Period
) T26 ON (
0x08 = T26.Fld50703_TYPE
AND 0x0000CD06 = T26.Fld50703_RTRef
AND T21._IDRRef = T26.Fld50703_RRRef
)
AND (T26.Fld50705RRef = @P24)
LEFT OUTER JOIN #tt59 T30 WITH (NOLOCK) ON (T21._Fld52519RRef
= T30._Q_001_F_000RRef)
AND (
(T21._Date_Time >= T30._Q_001_F_002)
AND (T21._Date_Time <= T30._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T31 ON T22.Fld50828RRef = T31._IDRRef
WHERE T21._Posted = 0x01
AND T22.Fld50828RRef IN (
SELECT T32._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T32 WITH (NOLOCK)
)
AND (
T22.Fld50828RRef IN (
SELECT T33._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T33 WITH (NOLOCK)
)
AND (T22.Fld50826RRef = @P25)
OR T31._ParentIDRRef IN (
SELECT T34._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T34 WITH (NOLOCK)
)
AND (T22.Fld50826RRef = @P26)
OR T22.Fld56279RRef IN (
SELECT T35._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T35 WITH (NOLOCK)
)
AND (T22.Fld50826RRef = @P27)
)
AND (
(T26.Fld50704RRef = @P28)
OR @P29 IN (
SELECT T36._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T36
WHERE (T36._Fld50691RRef = T22.Fld50828RRef)
AND (
T36._Fld50690_TYPE = 0x08
AND T36._Fld50690_RTRef = 0x0000CD06
AND T36._Fld50690_RRRef = T21._IDRRef
)
)
AND (T22.Fld50826RRef = @P30)
OR @P31 IN (
SELECT T37._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T37
WHERE (
(T37._Fld50691RRef = T31._ParentIDRRef)
OR (T37._Fld50691RRef = T22.Fld56279RRef)
)
AND (
T37._Fld50690_TYPE = 0x08
AND T37._Fld50690_RTRef = 0x0000CD06
AND T37._Fld50690_RRRef = T21._IDRRef
)
)
AND (T22.Fld50826RRef = @P32)
)
ORDER BY (T21._Date_Time)
) T20
UNION ALL
SELECT 0x0000CD0F
,T38.Q_001_F_000RRef
,0x05
,@P33
,T38.Q_001_F_001_
,T38.Q_001_F_002_
,T38.Q_001_F_003RRef
,T38.Q_001_F_004RRef
,T38.Q_001_F_005RRef
,0x08
,@P34
,T38.Q_001_F_006RRef
,T38.Q_001_F_007RRef
,T38.Q_001_F_008RRef
,T38.Q_001_F_009_
,T38.Q_001_F_010RRef
,T38.Q_001_F_011_
,T38.Q_001_F_012_
,CAST(T38.Q_001_F_013_ AS NVARCHAR(52))
,T38.Q_001_F_014_TYPE
,T38.Q_001_F_014_S
,T38.Q_001_F_014_RRRef
,T38.Q_001_F_015_
FROM (
SELECT TOP 1000 T39._IDRRef AS Q_001_F_000RRef
,T39._Number AS Q_001_F_001_
,T39._Date_Time AS Q_001_F_002_
,T39._Fld52799RRef AS Q_001_F_003RRef
,T39._Fld52797RRef AS Q_001_F_004RRef
,T39._Fld52804RRef AS Q_001_F_005RRef
,T39._Fld52805RRef AS Q_001_F_006RRef
,T40.Fld50826RRef AS Q_001_F_007RRef
,T40.Fld50828RRef AS Q_001_F_008RRef
,T40.Fld50827_ AS Q_001_F_009_
,T40.Fld50825RRef AS Q_001_F_010RRef
,T39._Fld52802 AS Q_001_F_011_
,CASE
WHEN (NOT (((T40.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P35 AS Q_001_F_013_
,CASE
WHEN T48._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T48._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T48._Q_001_F_001_TYPE IS NULL
THEN @P36
ELSE T48._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T48._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T48._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T39._Date_Time AS Q_001_F_015_
FROM dbo._Document52495X1 T39
LEFT OUTER JOIN (
SELECT T43._Fld50828RRef AS Fld50828RRef
,T43._Fld50826RRef AS Fld50826RRef
,T43._Fld56279RRef AS Fld56279RRef
,T43._Fld50824_TYPE AS Fld50824_TYPE
,T43._Fld50824_RTRef AS Fld50824_RTRef
,T43._Fld50824_RRRef AS Fld50824_RRRef
,T43._Fld50827 AS Fld50827_
,T43._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T42._Fld50824_TYPE AS Fld50824_TYPE
,T42._Fld50824_RTRef AS Fld50824_RTRef
,T42._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T42._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T42
GROUP BY T42._Fld50824_TYPE
,T42._Fld50824_RTRef
,T42._Fld50824_RRRef
) T41
INNER JOIN dbo._InfoRg50823X1 T43 ON T41.Fld50824_TYPE = T43._Fld50824_TYPE
AND T41.Fld50824_RTRef = T43._Fld50824_RTRef
AND T41.Fld50824_RRRef = T43._Fld50824_RRRef
AND T41.MAXPERIOD_ = T43._Period
) T40 ON (
0x08 = T40.Fld50824_TYPE
AND 0x0000CD0F = T40.Fld50824_RTRef
AND T39._IDRRef = T40.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T47._Fld50703_TYPE AS Fld50703_TYPE
,T47._Fld50703_RTRef AS Fld50703_RTRef
,T47._Fld50703_RRRef AS Fld50703_RRRef
,T47._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T46._Fld50703_TYPE AS Fld50703_TYPE
,T46._Fld50703_RTRef AS Fld50703_RTRef
,T46._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T46._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T46
GROUP BY T46._Fld50703_TYPE
,T46._Fld50703_RTRef
,T46._Fld50703_RRRef
) T45
INNER JOIN dbo._InfoRg50702X1 T47 ON T45.Fld50703_TYPE = T47._Fld50703_TYPE
AND T45.Fld50703_RTRef = T47._Fld50703_RTRef
AND T45.Fld50703_RRRef = T47._Fld50703_RRRef
AND T45.MAXPERIOD_ = T47._Period
) T44 ON (
0x08 = T44.Fld50703_TYPE
AND 0x0000CD0F = T44.Fld50703_RTRef
AND T39._IDRRef = T44.Fld50703_RRRef
)
AND (T44.Fld50705RRef = @P37)
LEFT OUTER JOIN #tt59 T48 WITH (NOLOCK) ON (T39._Fld52805RRef
= T48._Q_001_F_000RRef)
AND (
(T39._Date_Time >= T48._Q_001_F_002)
AND (T39._Date_Time <= T48._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T49 ON T40.Fld50828RRef = T49._IDRRef
WHERE T39._Posted = 0x01
AND T40.Fld50828RRef IN (
SELECT T50._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T50 WITH (NOLOCK)
)
AND (
T40.Fld50828RRef IN (
SELECT T51._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T51 WITH (NOLOCK)
)
AND (T40.Fld50826RRef = @P38)
OR T49._ParentIDRRef IN (
SELECT T52._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T52 WITH (NOLOCK)
)
AND (T40.Fld50826RRef = @P39)
OR T40.Fld56279RRef IN (
SELECT T53._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T53 WITH (NOLOCK)
)
AND (T40.Fld50826RRef = @P40)
)
AND (
@P41 IN (
SELECT T54._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T54
WHERE (T54._Fld50691RRef = T40.Fld50828RRef)
AND (
T54._Fld50690_TYPE = 0x08
AND T54._Fld50690_RTRef = 0x0000CD0F
AND T54._Fld50690_RRRef = T39._IDRRef
)
)
AND (T40.Fld50826RRef = @P42)
OR @P43 IN (
SELECT T55._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T55
WHERE (
(T55._Fld50691RRef = T49._ParentIDRRef)
OR (T55._Fld50691RRef = T40.Fld56279RRef)
)
AND (
T55._Fld50690_TYPE = 0x08
AND T55._Fld50690_RTRef = 0x0000CD0F
AND T55._Fld50690_RRRef = T39._IDRRef
)
)
AND (T40.Fld50826RRef = @P44)
)
ORDER BY (T39._Date_Time)
) T38
UNION ALL
SELECT 0x0000C533
,T56.Q_001_F_000RRef
,0x05
,@P45
,CAST(T56.Q_001_F_001_ AS NVARCHAR(11))
,T56.Q_001_F_002_
,T56.Q_001_F_003RRef
,T56.Q_001_F_004RRef
,T56.Q_001_F_005RRef
,0x08
,@P46
,T56.Q_001_F_006RRef
,T56.Q_001_F_007RRef
,T56.Q_001_F_008RRef
,T56.Q_001_F_009_
,T56.Q_001_F_010RRef
,T56.Q_001_F_011_
,T56.Q_001_F_012_
,CAST(T56.Q_001_F_013_ AS NVARCHAR(52))
,T56.Q_001_F_014_TYPE
,T56.Q_001_F_014_S
,T56.Q_001_F_014_RRRef
,T56.Q_001_F_015_
FROM (
SELECT TOP 1000 T57._IDRRef AS Q_001_F_000RRef
,T57._Number AS Q_001_F_001_
,T57._Date_Time AS Q_001_F_002_
,T57._Fld51025RRef AS Q_001_F_003RRef
,T57._Fld51017RRef AS Q_001_F_004RRef
,T57._Fld51029RRef AS Q_001_F_005RRef
,T57._Fld51018RRef AS Q_001_F_006RRef
,T58.Fld50826RRef AS Q_001_F_007RRef
,T58.Fld50828RRef AS Q_001_F_008RRef
,T58.Fld50827_ AS Q_001_F_009_
,T58.Fld50825RRef AS Q_001_F_010RRef
,T57._Fld51030 AS Q_001_F_011_
,CASE
WHEN (NOT (((T58.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P47 AS Q_001_F_013_
,CASE
WHEN T66._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T66._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T66._Q_001_F_001_TYPE IS NULL
THEN @P48
ELSE T66._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T66._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T66._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T57._Date_Time AS Q_001_F_015_
FROM dbo._Document50483X1 T57
LEFT OUTER JOIN (
SELECT T61._Fld50828RRef AS Fld50828RRef
,T61._Fld50826RRef AS Fld50826RRef
,T61._Fld56279RRef AS Fld56279RRef
,T61._Fld50824_TYPE AS Fld50824_TYPE
,T61._Fld50824_RTRef AS Fld50824_RTRef
,T61._Fld50824_RRRef AS Fld50824_RRRef
,T61._Fld50827 AS Fld50827_
,T61._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T60._Fld50824_TYPE AS Fld50824_TYPE
,T60._Fld50824_RTRef AS Fld50824_RTRef
,T60._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T60._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T60
GROUP BY T60._Fld50824_TYPE
,T60._Fld50824_RTRef
,T60._Fld50824_RRRef
) T59
INNER JOIN dbo._InfoRg50823X1 T61 ON T59.Fld50824_TYPE = T61._Fld50824_TYPE
AND T59.Fld50824_RTRef = T61._Fld50824_RTRef
AND T59.Fld50824_RRRef = T61._Fld50824_RRRef
AND T59.MAXPERIOD_ = T61._Period
) T58 ON (
0x08 = T58.Fld50824_TYPE
AND 0x0000C533 = T58.Fld50824_RTRef
AND T57._IDRRef = T58.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T65._Fld50704RRef AS Fld50704RRef
,T65._Fld50703_TYPE AS Fld50703_TYPE
,T65._Fld50703_RTRef AS Fld50703_RTRef
,T65._Fld50703_RRRef AS Fld50703_RRRef
,T65._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T64._Fld50703_TYPE AS Fld50703_TYPE
,T64._Fld50703_RTRef AS Fld50703_RTRef
,T64._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T64._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T64
GROUP BY T64._Fld50703_TYPE
,T64._Fld50703_RTRef
,T64._Fld50703_RRRef
) T63
INNER JOIN dbo._InfoRg50702X1 T65 ON T63.Fld50703_TYPE = T65._Fld50703_TYPE
AND T63.Fld50703_RTRef = T65._Fld50703_RTRef
AND T63.Fld50703_RRRef = T65._Fld50703_RRRef
AND T63.MAXPERIOD_ = T65._Period
) T62 ON (
0x08 = T62.Fld50703_TYPE
AND 0x0000C533 = T62.Fld50703_RTRef
AND T57._IDRRef = T62.Fld50703_RRRef
)
AND (T62.Fld50705RRef = @P49)
LEFT OUTER JOIN #tt59 T66 WITH (NOLOCK) ON (T57._Fld51018RRef
= T66._Q_001_F_000RRef)
AND (
(T57._Date_Time >= T66._Q_001_F_002)
AND (T57._Date_Time <= T66._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T67 ON T58.Fld50828RRef = T67._IDRRef
WHERE T57._Posted = 0x01
AND T58.Fld50828RRef IN (
SELECT T68._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T68 WITH (NOLOCK)
)
AND (
T58.Fld50828RRef IN (
SELECT T69._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T69 WITH (NOLOCK)
)
AND (T58.Fld50826RRef = @P50)
OR T67._ParentIDRRef IN (
SELECT T70._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T70 WITH (NOLOCK)
)
AND (T58.Fld50826RRef = @P51)
OR T58.Fld56279RRef IN (
SELECT T71._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T71 WITH (NOLOCK)
)
AND (T58.Fld50826RRef = @P52)
)
AND (
(T62.Fld50704RRef = @P53)
OR @P54 IN (
SELECT T72._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T72
WHERE (T72._Fld50691RRef = T58.Fld50828RRef)
AND (
T72._Fld50690_TYPE = 0x08
AND T72._Fld50690_RTRef = 0x0000C533
AND T72._Fld50690_RRRef = T57._IDRRef
)
)
AND (T58.Fld50826RRef = @P55)
OR @P56 IN (
SELECT T73._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T73
WHERE (
(T73._Fld50691RRef = T67._ParentIDRRef)
OR (T73._Fld50691RRef = T58.Fld56279RRef)
)
AND (
T73._Fld50690_TYPE = 0x08
AND T73._Fld50690_RTRef = 0x0000C533
AND T73._Fld50690_RRRef = T57._IDRRef
)
)
AND (T58.Fld50826RRef = @P57)
)
ORDER BY (T57._Date_Time)
) T56
UNION ALL
SELECT 0x0000D305
,T74.Q_001_F_000RRef
,0x05
,@P58
,CAST(T74.Q_001_F_001_ AS NVARCHAR(11))
,T74.Q_001_F_002_
,T74.Q_001_F_003RRef
,T74.Q_001_F_004RRef
,T74.Q_001_F_005RRef
,0x05
,T74.Q_001_F_006_
,0x00000000000000000000000000000000
,T74.Q_001_F_007RRef
,T74.Q_001_F_008RRef
,T74.Q_001_F_009_
,T74.Q_001_F_010RRef
,T74.Q_001_F_011_
,T74.Q_001_F_012_
,CAST(T74.Q_001_F_013_ AS NVARCHAR(52))
,T74.Q_001_F_014_TYPE
,T74.Q_001_F_014_S
,T74.Q_001_F_014_RRRef
,T74.Q_001_F_015_
FROM (
SELECT TOP 1000 T75._IDRRef AS Q_001_F_000RRef
,T75._Number AS Q_001_F_001_
,T75._Date_Time AS Q_001_F_002_
,T75._Fld54031RRef AS Q_001_F_003RRef
,T75._Fld54030RRef AS Q_001_F_004RRef
,T75._Fld54035RRef AS Q_001_F_005RRef
,T75._Fld56446 AS Q_001_F_006_
,T76.Fld50826RRef AS Q_001_F_007RRef
,T76.Fld50828RRef AS Q_001_F_008RRef
,T76.Fld50827_ AS Q_001_F_009_
,T76.Fld50825RRef AS Q_001_F_010RRef
,T75._Fld54034 AS Q_001_F_011_
,CASE
WHEN (NOT (((T76.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P59 AS Q_001_F_013_
,CASE
WHEN T84._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T84._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T84._Q_001_F_001_TYPE IS NULL
THEN @P60
ELSE T84._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T84._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T84._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T75._Date_Time AS Q_001_F_015_
FROM dbo._Document54021X1 T75
LEFT OUTER JOIN (
SELECT T79._Fld50828RRef AS Fld50828RRef
,T79._Fld50826RRef AS Fld50826RRef
,T79._Fld56279RRef AS Fld56279RRef
,T79._Fld50824_TYPE AS Fld50824_TYPE
,T79._Fld50824_RTRef AS Fld50824_RTRef
,T79._Fld50824_RRRef AS Fld50824_RRRef
,T79._Fld50827 AS Fld50827_
,T79._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T78._Fld50824_TYPE AS Fld50824_TYPE
,T78._Fld50824_RTRef AS Fld50824_RTRef
,T78._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T78._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T78
GROUP BY T78._Fld50824_TYPE
,T78._Fld50824_RTRef
,T78._Fld50824_RRRef
) T77
INNER JOIN dbo._InfoRg50823X1 T79 ON T77.Fld50824_TYPE = T79._Fld50824_TYPE
AND T77.Fld50824_RTRef = T79._Fld50824_RTRef
AND T77.Fld50824_RRRef = T79._Fld50824_RRRef
AND T77.MAXPERIOD_ = T79._Period
) T76 ON (
0x08 = T76.Fld50824_TYPE
AND 0x0000D305 = T76.Fld50824_RTRef
AND T75._IDRRef = T76.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T83._Fld50704RRef AS Fld50704RRef
,T83._Fld50703_TYPE AS Fld50703_TYPE
,T83._Fld50703_RTRef AS Fld50703_RTRef
,T83._Fld50703_RRRef AS Fld50703_RRRef
,T83._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T82._Fld50703_TYPE AS Fld50703_TYPE
,T82._Fld50703_RTRef AS Fld50703_RTRef
,T82._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T82._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T82
GROUP BY T82._Fld50703_TYPE
,T82._Fld50703_RTRef
,T82._Fld50703_RRRef
) T81
INNER JOIN dbo._InfoRg50702X1 T83 ON T81.Fld50703_TYPE = T83._Fld50703_TYPE
AND T81.Fld50703_RTRef = T83._Fld50703_RTRef
AND T81.Fld50703_RRRef = T83._Fld50703_RRRef
AND T81.MAXPERIOD_ = T83._Period
) T80 ON (
0x08 = T80.Fld50703_TYPE
AND 0x0000D305 = T80.Fld50703_RTRef
AND T75._IDRRef = T80.Fld50703_RRRef
)
AND (T80.Fld50705RRef = @P61)
LEFT OUTER JOIN #tt59 T84 WITH (NOLOCK) ON (T75._Fld54036RRef
= T84._Q_001_F_000RRef)
AND (
(T75._Date_Time >= T84._Q_001_F_002)
AND (T75._Date_Time <= T84._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T85 ON T76.Fld50828RRef = T85._IDRRef
WHERE T75._Posted = 0x01
AND T76.Fld50828RRef IN (
SELECT T86._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T86 WITH (NOLOCK)
)
AND (
T76.Fld50828RRef IN (
SELECT T87._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T87 WITH (NOLOCK)
)
AND (T76.Fld50826RRef = @P62)
OR T85._ParentIDRRef IN (
SELECT T88._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T88 WITH (NOLOCK)
)
AND (T76.Fld50826RRef = @P63)
OR T76.Fld56279RRef IN (
SELECT T89._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T89 WITH (NOLOCK)
)
AND (T76.Fld50826RRef = @P64)
)
AND (
(T80.Fld50704RRef = @P65)
OR @P66 IN (
SELECT T90._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T90
WHERE (T90._Fld50691RRef = T76.Fld50828RRef)
AND (
T90._Fld50690_TYPE = 0x08
AND T90._Fld50690_RTRef = 0x0000D305
AND T90._Fld50690_RRRef = T75._IDRRef
)
)
AND (T76.Fld50826RRef = @P67)
OR @P68 IN (
SELECT T91._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T91
WHERE (
(T91._Fld50691RRef = T85._ParentIDRRef)
OR (T91._Fld50691RRef = T76.Fld56279RRef)
)
AND (
T91._Fld50690_TYPE = 0x08
AND T91._Fld50690_RTRef = 0x0000D305
AND T91._Fld50690_RRRef = T75._IDRRef
)
)
AND (T76.Fld50826RRef = @P69)
)
ORDER BY (T75._Date_Time)
) T74
UNION ALL
SELECT 0x0000CD0C
,T92.Q_001_F_000RRef
,0x05
,@P70
,CAST(T92.Q_001_F_001_ AS NVARCHAR(11))
,T92.Q_001_F_002_
,T92.Q_001_F_003RRef
,T92.Q_001_F_004RRef
,T92.Q_001_F_005RRef
,0x05
,CAST(T92.Q_001_F_006_ AS NVARCHAR(150))
,0x00000000000000000000000000000000
,T92.Q_001_F_007RRef
,T92.Q_001_F_008RRef
,T92.Q_001_F_009_
,T92.Q_001_F_010RRef
,T92.Q_001_F_011_
,T92.Q_001_F_012_
,CAST(T92.Q_001_F_013_ AS NVARCHAR(52))
,0x08
,@P71
,T92.Q_001_F_014RRef
,T92.Q_001_F_015_
FROM (
SELECT TOP 1000 T93._IDRRef AS Q_001_F_000RRef
,T93._Number AS Q_001_F_001_
,T93._Date_Time AS Q_001_F_002_
,T93._Fld52720RRef AS Q_001_F_003RRef
,T93._Fld52705RRef AS Q_001_F_004RRef
,T93._Fld52719RRef AS Q_001_F_005RRef
,T93._Fld52728 AS Q_001_F_006_
,T94.Fld50826RRef AS Q_001_F_007RRef
,T94.Fld50828RRef AS Q_001_F_008RRef
,T94.Fld50827_ AS Q_001_F_009_
,T94.Fld50825RRef AS Q_001_F_010RRef
,T93._Fld52718 AS Q_001_F_011_
,CASE
WHEN (NOT (((T94.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P72 AS Q_001_F_013_
,T93._Fld52706RRef AS Q_001_F_014RRef
,T93._Date_Time AS Q_001_F_015_
FROM dbo._Document52492X1 T93
LEFT OUTER JOIN (
SELECT T97._Fld50828RRef AS Fld50828RRef
,T97._Fld50826RRef AS Fld50826RRef
,T97._Fld56279RRef AS Fld56279RRef
,T97._Fld50824_TYPE AS Fld50824_TYPE
,T97._Fld50824_RTRef AS Fld50824_RTRef
,T97._Fld50824_RRRef AS Fld50824_RRRef
,T97._Fld50827 AS Fld50827_
,T97._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T96._Fld50824_TYPE AS Fld50824_TYPE
,T96._Fld50824_RTRef AS Fld50824_RTRef
,T96._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T96._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T96
GROUP BY T96._Fld50824_TYPE
,T96._Fld50824_RTRef
,T96._Fld50824_RRRef
) T95
INNER JOIN dbo._InfoRg50823X1 T97 ON T95.Fld50824_TYPE = T97._Fld50824_TYPE
AND T95.Fld50824_RTRef = T97._Fld50824_RTRef
AND T95.Fld50824_RRRef = T97._Fld50824_RRRef
AND T95.MAXPERIOD_ = T97._Period
) T94 ON (
0x08 = T94.Fld50824_TYPE
AND 0x0000CD0C = T94.Fld50824_RTRef
AND T93._IDRRef = T94.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T101._Fld50704RRef AS Fld50704RRef
,T101._Fld50703_TYPE AS Fld50703_TYPE
,T101._Fld50703_RTRef AS Fld50703_RTRef
,T101._Fld50703_RRRef AS Fld50703_RRRef
,T101._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T100._Fld50703_TYPE AS Fld50703_TYPE
,T100._Fld50703_RTRef AS Fld50703_RTRef
,T100._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T100._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T100
GROUP BY T100._Fld50703_TYPE
,T100._Fld50703_RTRef
,T100._Fld50703_RRRef
) T99
INNER JOIN dbo._InfoRg50702X1 T101 ON T99.Fld50703_TYPE = T101._Fld50703_TYPE
AND T99.Fld50703_RTRef = T101._Fld50703_RTRef
AND T99.Fld50703_RRRef = T101._Fld50703_RRRef
AND T99.MAXPERIOD_ = T101._Period
) T98 ON (
0x08 = T98.Fld50703_TYPE
AND 0x0000CD0C = T98.Fld50703_RTRef
AND T93._IDRRef = T98.Fld50703_RRRef
)
AND (T98.Fld50705RRef = @P73)
LEFT OUTER JOIN dbo._Reference50477X1 T102 ON T94.Fld50828RRef = T102._IDRRef
WHERE T93._Posted = 0x01
AND T94.Fld50828RRef IN (
SELECT T103._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T103 WITH (NOLOCK)
)
AND (
T94.Fld50828RRef IN (
SELECT T104._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T104 WITH (NOLOCK)
)
AND (T94.Fld50826RRef = @P74)
OR T102._ParentIDRRef IN (
SELECT T105._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T105 WITH (NOLOCK)
)
AND (T94.Fld50826RRef = @P75)
OR T94.Fld56279RRef IN (
SELECT T106._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T106 WITH (NOLOCK)
)
AND (T94.Fld50826RRef = @P76)
)
AND (
(T98.Fld50704RRef = @P77)
OR @P78 IN (
SELECT T107._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T107
WHERE (T107._Fld50691RRef = T94.Fld50828RRef)
AND (
T107._Fld50690_TYPE = 0x08
AND T107._Fld50690_RTRef = 0x0000CD0C
AND T107._Fld50690_RRRef = T93._IDRRef
)
)
AND (T94.Fld50826RRef = @P79)
OR @P80 IN (
SELECT T108._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T108
WHERE (
(T108._Fld50691RRef = T102._ParentIDRRef)
OR (T108._Fld50691RRef = T94.Fld56279RRef)
)
AND (
T108._Fld50690_TYPE = 0x08
AND T108._Fld50690_RTRef = 0x0000CD0C
AND T108._Fld50690_RRRef = T93._IDRRef
)
)
AND (T94.Fld50826RRef = @P81)
)
ORDER BY (T93._Date_Time)
) T92
UNION ALL
SELECT 0x0000CD0B
,T109.Q_001_F_000RRef
,0x05
,@P82
,CAST(T109.Q_001_F_001_ AS NVARCHAR(11))
,T109.Q_001_F_002_
,T109.Q_001_F_003RRef
,T109.Q_001_F_004RRef
,T109.Q_001_F_005RRef
,0x05
,CAST(T109.Q_001_F_006_ AS NVARCHAR(150))
,0x00000000000000000000000000000000
,T109.Q_001_F_007RRef
,T109.Q_001_F_008RRef
,T109.Q_001_F_009_
,T109.Q_001_F_010RRef
,T109.Q_001_F_011_
,T109.Q_001_F_012_
,CAST(T109.Q_001_F_013_ AS NVARCHAR(52))
,0x08
,@P83
,T109.Q_001_F_014RRef
,T109.Q_001_F_015_
FROM (
SELECT TOP 1000 T110._IDRRef AS Q_001_F_000RRef
,T110._Number AS Q_001_F_001_
,T110._Date_Time AS Q_001_F_002_
,T110._Fld52683RRef AS Q_001_F_003RRef
,T110._Fld52668RRef AS Q_001_F_004RRef
,T110._Fld52682RRef AS Q_001_F_005RRef
,T110._Fld52691 AS Q_001_F_006_
,T111.Fld50826RRef AS Q_001_F_007RRef
,T111.Fld50828RRef AS Q_001_F_008RRef
,T111.Fld50827_ AS Q_001_F_009_
,T111.Fld50825RRef AS Q_001_F_010RRef
,T110._Fld52681 AS Q_001_F_011_
,CASE
WHEN (NOT (((T111.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P84 AS Q_001_F_013_
,T110._Fld52669RRef AS Q_001_F_014RRef
,T110._Date_Time AS Q_001_F_015_
FROM dbo._Document52491X1 T110
LEFT OUTER JOIN (
SELECT T114._Fld50828RRef AS Fld50828RRef
,T114._Fld50826RRef AS Fld50826RRef
,T114._Fld56279RRef AS Fld56279RRef
,T114._Fld50824_TYPE AS Fld50824_TYPE
,T114._Fld50824_RTRef AS Fld50824_RTRef
,T114._Fld50824_RRRef AS Fld50824_RRRef
,T114._Fld50827 AS Fld50827_
,T114._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T113._Fld50824_TYPE AS Fld50824_TYPE
,T113._Fld50824_RTRef AS Fld50824_RTRef
,T113._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T113._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T113
GROUP BY T113._Fld50824_TYPE
,T113._Fld50824_RTRef
,T113._Fld50824_RRRef
) T112
INNER JOIN dbo._InfoRg50823X1 T114 ON T112.Fld50824_TYPE = T114._Fld50824_TYPE
AND T112.Fld50824_RTRef = T114._Fld50824_RTRef
AND T112.Fld50824_RRRef = T114._Fld50824_RRRef
AND T112.MAXPERIOD_ = T114._Period
) T111 ON (
0x08 = T111.Fld50824_TYPE
AND 0x0000CD0B = T111.Fld50824_RTRef
AND T110._IDRRef = T111.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T118._Fld50704RRef AS Fld50704RRef
,T118._Fld50703_TYPE AS Fld50703_TYPE
,T118._Fld50703_RTRef AS Fld50703_RTRef
,T118._Fld50703_RRRef AS Fld50703_RRRef
,T118._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T117._Fld50703_TYPE AS Fld50703_TYPE
,T117._Fld50703_RTRef AS Fld50703_RTRef
,T117._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T117._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T117
GROUP BY T117._Fld50703_TYPE
,T117._Fld50703_RTRef
,T117._Fld50703_RRRef
) T116
INNER JOIN dbo._InfoRg50702X1 T118 ON T116.Fld50703_TYPE = T118._Fld50703_TYPE
AND T116.Fld50703_RTRef = T118._Fld50703_RTRef
AND T116.Fld50703_RRRef = T118._Fld50703_RRRef
AND T116.MAXPERIOD_ = T118._Period
) T115 ON (
0x08 = T115.Fld50703_TYPE
AND 0x0000CD0B = T115.Fld50703_RTRef
AND T110._IDRRef = T115.Fld50703_RRRef
)
AND (T115.Fld50705RRef = @P85)
LEFT OUTER JOIN dbo._Reference50477X1 T119 ON T111.Fld50828RRef = T119._IDRRef
WHERE T110._Posted = 0x01
AND T111.Fld50828RRef IN (
SELECT T120._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T120 WITH (NOLOCK)
)
AND (
T111.Fld50828RRef IN (
SELECT T121._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T121 WITH (NOLOCK)
)
AND (T111.Fld50826RRef = @P86)
OR T119._ParentIDRRef IN (
SELECT T122._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T122 WITH (NOLOCK)
)
AND (T111.Fld50826RRef = @P87)
OR T111.Fld56279RRef IN (
SELECT T123._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T123 WITH (NOLOCK)
)
AND (T111.Fld50826RRef = @P88)
)
AND (
(T115.Fld50704RRef = @P89)
OR @P90 IN (
SELECT T124._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T124
WHERE (T124._Fld50691RRef = T111.Fld50828RRef)
AND (
T124._Fld50690_TYPE = 0x08
AND T124._Fld50690_RTRef = 0x0000CD0B
AND T124._Fld50690_RRRef = T110._IDRRef
)
)
AND (T111.Fld50826RRef = @P91)
OR @P92 IN (
SELECT T125._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T125
WHERE (
(T125._Fld50691RRef = T119._ParentIDRRef)
OR (T125._Fld50691RRef = T111.Fld56279RRef)
)
AND (
T125._Fld50690_TYPE = 0x08
AND T125._Fld50690_RTRef = 0x0000CD0B
AND T125._Fld50690_RRRef = T110._IDRRef
)
)
AND (T111.Fld50826RRef = @P93)
)
ORDER BY (T110._Date_Time)
) T109
UNION ALL
SELECT 0x0000CD08
,T126.Q_001_F_000RRef
,0x05
,@P94
,T126.Q_001_F_001_
,T126.Q_001_F_002_
,T126.Q_001_F_003RRef
,T126.Q_001_F_004RRef
,T126.Q_001_F_005RRef
,0x08
,@P95
,T126.Q_001_F_006RRef
,T126.Q_001_F_007RRef
,T126.Q_001_F_008RRef
,T126.Q_001_F_009_
,T126.Q_001_F_010RRef
,T126.Q_001_F_011_
,T126.Q_001_F_012_
,CAST(T126.Q_001_F_013_ AS NVARCHAR(52))
,T126.Q_001_F_014_TYPE
,T126.Q_001_F_014_S
,T126.Q_001_F_014_RRRef
,T126.Q_001_F_015_
FROM (
SELECT TOP 1000 T127._IDRRef AS Q_001_F_000RRef
,T127._Number AS Q_001_F_001_
,T127._Date_Time AS Q_001_F_002_
,T127._Fld52574RRef AS Q_001_F_003RRef
,T127._Fld52572RRef AS Q_001_F_004RRef
,T127._Fld52579RRef AS Q_001_F_005RRef
,T127._Fld52580RRef AS Q_001_F_006RRef
,T128.Fld50826RRef AS Q_001_F_007RRef
,T128.Fld50828RRef AS Q_001_F_008RRef
,T128.Fld50827_ AS Q_001_F_009_
,T128.Fld50825RRef AS Q_001_F_010RRef
,T127._Fld52577 AS Q_001_F_011_
,CASE
WHEN (NOT (((T128.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P96 AS Q_001_F_013_
,CASE
WHEN T136._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T136._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T136._Q_001_F_001_TYPE IS NULL
THEN @P97
ELSE T136._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T136._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T136._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T127._Date_Time AS Q_001_F_015_
FROM dbo._Document52488X1 T127
LEFT OUTER JOIN (
SELECT T131._Fld50828RRef AS Fld50828RRef
,T131._Fld50826RRef AS Fld50826RRef
,T131._Fld56279RRef AS Fld56279RRef
,T131._Fld50824_TYPE AS Fld50824_TYPE
,T131._Fld50824_RTRef AS Fld50824_RTRef
,T131._Fld50824_RRRef AS Fld50824_RRRef
,T131._Fld50827 AS Fld50827_
,T131._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T130._Fld50824_TYPE AS Fld50824_TYPE
,T130._Fld50824_RTRef AS Fld50824_RTRef
,T130._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T130._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T130
GROUP BY T130._Fld50824_TYPE
,T130._Fld50824_RTRef
,T130._Fld50824_RRRef
) T129
INNER JOIN dbo._InfoRg50823X1 T131 ON T129.Fld50824_TYPE = T131._Fld50824_TYPE
AND T129.Fld50824_RTRef = T131._Fld50824_RTRef
AND T129.Fld50824_RRRef = T131._Fld50824_RRRef
AND T129.MAXPERIOD_ = T131._Period
) T128 ON (
0x08 = T128.Fld50824_TYPE
AND 0x0000CD08 = T128.Fld50824_RTRef
AND T127._IDRRef = T128.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T135._Fld50704RRef AS Fld50704RRef
,T135._Fld50703_TYPE AS Fld50703_TYPE
,T135._Fld50703_RTRef AS Fld50703_RTRef
,T135._Fld50703_RRRef AS Fld50703_RRRef
,T135._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T134._Fld50703_TYPE AS Fld50703_TYPE
,T134._Fld50703_RTRef AS Fld50703_RTRef
,T134._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T134._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T134
GROUP BY T134._Fld50703_TYPE
,T134._Fld50703_RTRef
,T134._Fld50703_RRRef
) T133
INNER JOIN dbo._InfoRg50702X1 T135 ON T133.Fld50703_TYPE = T135._Fld50703_TYPE
AND T133.Fld50703_RTRef = T135._Fld50703_RTRef
AND T133.Fld50703_RRRef = T135._Fld50703_RRRef
AND T133.MAXPERIOD_ = T135._Period
) T132 ON (
0x08 = T132.Fld50703_TYPE
AND 0x0000CD08 = T132.Fld50703_RTRef
AND T127._IDRRef = T132.Fld50703_RRRef
)
AND (T132.Fld50705RRef = @P98)
LEFT OUTER JOIN #tt59 T136 WITH (NOLOCK) ON (T127._Fld52580RRef
= T136._Q_001_F_000RRef)
AND (
(T127._Date_Time >= T136._Q_001_F_002)
AND (T127._Date_Time <= T136._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T137 ON T128.Fld50828RRef = T137._IDRRef
WHERE T127._Posted = 0x01
AND T128.Fld50828RRef IN (
SELECT T138._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T138 WITH (NOLOCK)
)
AND (
T128.Fld50828RRef IN (
SELECT T139._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T139 WITH (NOLOCK)
)
AND (T128.Fld50826RRef = @P99)
OR T137._ParentIDRRef IN (
SELECT T140._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T140 WITH (NOLOCK)
)
AND (T128.Fld50826RRef = @P100)
OR T128.Fld56279RRef IN (
SELECT T141._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T141 WITH (NOLOCK)
)
AND (T128.Fld50826RRef = @P101)
)
AND (
(T132.Fld50704RRef = @P102)
OR @P103 IN (
SELECT T142._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T142
WHERE (T142._Fld50691RRef = T128.Fld50828RRef)
AND (
T142._Fld50690_TYPE = 0x08
AND T142._Fld50690_RTRef = 0x0000CD08
AND T142._Fld50690_RRRef = T127._IDRRef
)
)
AND (T128.Fld50826RRef = @P104)
OR @P105 IN (
SELECT T143._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T143
WHERE (
(T143._Fld50691RRef = T137._ParentIDRRef)
OR (T143._Fld50691RRef = T128.Fld56279RRef)
)
AND (
T143._Fld50690_TYPE = 0x08
AND T143._Fld50690_RTRef = 0x0000CD08
AND T143._Fld50690_RRRef = T127._IDRRef
)
)
AND (T128.Fld50826RRef = @P106)
)
ORDER BY (T127._Date_Time)
) T126
UNION ALL
SELECT 0x0000C535
,T144.Q_001_F_000RRef
,0x05
,@P107
,T144.Q_001_F_001_
,T144.Q_001_F_002_
,T144.Q_001_F_003RRef
,T144.Q_001_F_004RRef
,T144.Q_001_F_005RRef
,0x08
,@P108
,T144.Q_001_F_006RRef
,T144.Q_001_F_007RRef
,T144.Q_001_F_008RRef
,T144.Q_001_F_009_
,T144.Q_001_F_010RRef
,T144.Q_001_F_011_
,T144.Q_001_F_012_
,CAST(T144.Q_001_F_013_ AS NVARCHAR(52))
,T144.Q_001_F_014_TYPE
,T144.Q_001_F_014_S
,T144.Q_001_F_014_RRRef
,T144.Q_001_F_015_
FROM (
SELECT TOP 1000 T145._IDRRef AS Q_001_F_000RRef
,T145._Number AS Q_001_F_001_
,T145._Date_Time AS Q_001_F_002_
,T145._Fld51088RRef AS Q_001_F_003RRef
,T145._Fld51087RRef AS Q_001_F_004RRef
,T145._Fld51093RRef AS Q_001_F_005RRef
,T145._Fld54253RRef AS Q_001_F_006RRef
,T146.Fld50826RRef AS Q_001_F_007RRef
,T146.Fld50828RRef AS Q_001_F_008RRef
,T146.Fld50827_ AS Q_001_F_009_
,T146.Fld50825RRef AS Q_001_F_010RRef
,T145._Fld51092 AS Q_001_F_011_
,CASE
WHEN (NOT (((T146.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P109 AS Q_001_F_013_
,CASE
WHEN T154._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T154._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T154._Q_001_F_001_TYPE IS NULL
THEN @P110
ELSE T154._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T154._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T154._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T145._Date_Time AS Q_001_F_015_
FROM dbo._Document50485X1 T145
LEFT OUTER JOIN (
SELECT T149._Fld50828RRef AS Fld50828RRef
,T149._Fld50826RRef AS Fld50826RRef
,T149._Fld56279RRef AS Fld56279RRef
,T149._Fld50824_TYPE AS Fld50824_TYPE
,T149._Fld50824_RTRef AS Fld50824_RTRef
,T149._Fld50824_RRRef AS Fld50824_RRRef
,T149._Fld50827 AS Fld50827_
,T149._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T148._Fld50824_TYPE AS Fld50824_TYPE
,T148._Fld50824_RTRef AS Fld50824_RTRef
,T148._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T148._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T148
GROUP BY T148._Fld50824_TYPE
,T148._Fld50824_RTRef
,T148._Fld50824_RRRef
) T147
INNER JOIN dbo._InfoRg50823X1 T149 ON T147.Fld50824_TYPE = T149._Fld50824_TYPE
AND T147.Fld50824_RTRef = T149._Fld50824_RTRef
AND T147.Fld50824_RRRef = T149._Fld50824_RRRef
AND T147.MAXPERIOD_ = T149._Period
) T146 ON (
0x08 = T146.Fld50824_TYPE
AND 0x0000C535 = T146.Fld50824_RTRef
AND T145._IDRRef = T146.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T153._Fld50704RRef AS Fld50704RRef
,T153._Fld50703_TYPE AS Fld50703_TYPE
,T153._Fld50703_RTRef AS Fld50703_RTRef
,T153._Fld50703_RRRef AS Fld50703_RRRef
,T153._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T152._Fld50703_TYPE AS Fld50703_TYPE
,T152._Fld50703_RTRef AS Fld50703_RTRef
,T152._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T152._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T152
GROUP BY T152._Fld50703_TYPE
,T152._Fld50703_RTRef
,T152._Fld50703_RRRef
) T151
INNER JOIN dbo._InfoRg50702X1 T153 ON T151.Fld50703_TYPE = T153._Fld50703_TYPE
AND T151.Fld50703_RTRef = T153._Fld50703_RTRef
AND T151.Fld50703_RRRef = T153._Fld50703_RRRef
AND T151.MAXPERIOD_ = T153._Period
) T150 ON (
0x08 = T150.Fld50703_TYPE
AND 0x0000C535 = T150.Fld50703_RTRef
AND T145._IDRRef = T150.Fld50703_RRRef
)
AND (T150.Fld50705RRef = @P111)
LEFT OUTER JOIN #tt59 T154 WITH (NOLOCK) ON (T145._Fld54253RRef
= T154._Q_001_F_000RRef)
AND (
(T145._Date_Time >= T154._Q_001_F_002)
AND (T145._Date_Time <= T154._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T155 ON T146.Fld50828RRef = T155._IDRRef
WHERE T145._Posted = 0x01
AND T146.Fld50828RRef IN (
SELECT T156._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T156 WITH (NOLOCK)
)
AND (
T146.Fld50828RRef IN (
SELECT T157._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T157 WITH (NOLOCK)
)
AND (T146.Fld50826RRef = @P112)
OR T155._ParentIDRRef IN (
SELECT T158._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T158 WITH (NOLOCK)
)
AND (T146.Fld50826RRef = @P113)
OR T146.Fld56279RRef IN (
SELECT T159._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T159 WITH (NOLOCK)
)
AND (T146.Fld50826RRef = @P114)
)
AND (
(T150.Fld50704RRef = @P115)
OR @P116 IN (
SELECT T160._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T160
WHERE (T160._Fld50691RRef = T146.Fld50828RRef)
AND (
T160._Fld50690_TYPE = 0x08
AND T160._Fld50690_RTRef = 0x0000C535
AND T160._Fld50690_RRRef = T145._IDRRef
)
)
AND (T146.Fld50826RRef = @P117)
OR @P118 IN (
SELECT T161._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T161
WHERE (
(T161._Fld50691RRef = T155._ParentIDRRef)
OR (T161._Fld50691RRef = T146.Fld56279RRef)
)
AND (
T161._Fld50690_TYPE = 0x08
AND T161._Fld50690_RTRef = 0x0000C535
AND T161._Fld50690_RRRef = T145._IDRRef
)
)
AND (T146.Fld50826RRef = @P119)
)
ORDER BY (T145._Date_Time)
) T144
UNION ALL
SELECT 0x0000CD07
,T162.Q_001_F_000RRef
,0x05
,@P120
,T162.Q_001_F_001_
,T162.Q_001_F_002_
,T162.Q_001_F_003RRef
,T162.Q_001_F_004RRef
,T162.Q_001_F_005RRef
,0x05
,T162.Q_001_F_006_
,0x00000000000000000000000000000000
,T162.Q_001_F_007RRef
,T162.Q_001_F_008RRef
,T162.Q_001_F_009_
,T162.Q_001_F_010RRef
,T162.Q_001_F_011_
,T162.Q_001_F_012_
,CAST(T162.Q_001_F_013_ AS NVARCHAR(52))
,T162.Q_001_F_014_TYPE
,T162.Q_001_F_014_S
,T162.Q_001_F_014_RRRef
,T162.Q_001_F_015_
FROM (
SELECT TOP 1000 T163._IDRRef AS Q_001_F_000RRef
,T163._Number AS Q_001_F_001_
,T163._Date_Time AS Q_001_F_002_
,T163._Fld52526RRef AS Q_001_F_003RRef
,T163._Fld52546RRef AS Q_001_F_004RRef
,T163._Fld52550RRef AS Q_001_F_005RRef
,T163._Fld56447 AS Q_001_F_006_
,T164.Fld50826RRef AS Q_001_F_007RRef
,T164.Fld50828RRef AS Q_001_F_008RRef
,T164.Fld50827_ AS Q_001_F_009_
,T164.Fld50825RRef AS Q_001_F_010RRef
,T163._Fld52549 AS Q_001_F_011_
,CASE
WHEN (NOT (((T164.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P121 AS Q_001_F_013_
,CASE
WHEN T172._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T172._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T172._Q_001_F_001_TYPE IS NULL
THEN @P122
ELSE T172._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T172._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T172._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T163._Date_Time AS Q_001_F_015_
FROM dbo._Document52487X1 T163
LEFT OUTER JOIN (
SELECT T167._Fld50828RRef AS Fld50828RRef
,T167._Fld50826RRef AS Fld50826RRef
,T167._Fld56279RRef AS Fld56279RRef
,T167._Fld50824_TYPE AS Fld50824_TYPE
,T167._Fld50824_RTRef AS Fld50824_RTRef
,T167._Fld50824_RRRef AS Fld50824_RRRef
,T167._Fld50827 AS Fld50827_
,T167._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T166._Fld50824_TYPE AS Fld50824_TYPE
,T166._Fld50824_RTRef AS Fld50824_RTRef
,T166._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T166._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T166
GROUP BY T166._Fld50824_TYPE
,T166._Fld50824_RTRef
,T166._Fld50824_RRRef
) T165
INNER JOIN dbo._InfoRg50823X1 T167 ON T165.Fld50824_TYPE = T167._Fld50824_TYPE
AND T165.Fld50824_RTRef = T167._Fld50824_RTRef
AND T165.Fld50824_RRRef = T167._Fld50824_RRRef
AND T165.MAXPERIOD_ = T167._Period
) T164 ON (
0x08 = T164.Fld50824_TYPE
AND 0x0000CD07 = T164.Fld50824_RTRef
AND T163._IDRRef = T164.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T171._Fld50704RRef AS Fld50704RRef
,T171._Fld50703_TYPE AS Fld50703_TYPE
,T171._Fld50703_RTRef AS Fld50703_RTRef
,T171._Fld50703_RRRef AS Fld50703_RRRef
,T171._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T170._Fld50703_TYPE AS Fld50703_TYPE
,T170._Fld50703_RTRef AS Fld50703_RTRef
,T170._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T170._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T170
GROUP BY T170._Fld50703_TYPE
,T170._Fld50703_RTRef
,T170._Fld50703_RRRef
) T169
INNER JOIN dbo._InfoRg50702X1 T171 ON T169.Fld50703_TYPE = T171._Fld50703_TYPE
AND T169.Fld50703_RTRef = T171._Fld50703_RTRef
AND T169.Fld50703_RRRef = T171._Fld50703_RRRef
AND T169.MAXPERIOD_ = T171._Period
) T168 ON (
0x08 = T168.Fld50703_TYPE
AND 0x0000CD07 = T168.Fld50703_RTRef
AND T163._IDRRef = T168.Fld50703_RRRef
)
AND (T168.Fld50705RRef = @P123)
LEFT OUTER JOIN #tt59 T172 WITH (NOLOCK) ON (T163._Fld52523RRef
= T172._Q_001_F_000RRef)
AND (
(T163._Date_Time >= T172._Q_001_F_002)
AND (T163._Date_Time <= T172._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T173 ON T164.Fld50828RRef = T173._IDRRef
WHERE T163._Posted = 0x01
AND T164.Fld50828RRef IN (
SELECT T174._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T174 WITH (NOLOCK)
)
AND (
T164.Fld50828RRef IN (
SELECT T175._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T175 WITH (NOLOCK)
)
AND (T164.Fld50826RRef = @P124)
OR T173._ParentIDRRef IN (
SELECT T176._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T176 WITH (NOLOCK)
)
AND (T164.Fld50826RRef = @P125)
OR T164.Fld56279RRef IN (
SELECT T177._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T177 WITH (NOLOCK)
)
AND (T164.Fld50826RRef = @P126)
)
AND (
(T168.Fld50704RRef = @P127)
OR @P128 IN (
SELECT T178._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T178
WHERE (T178._Fld50691RRef = T164.Fld50828RRef)
AND (
T178._Fld50690_TYPE = 0x08
AND T178._Fld50690_RTRef = 0x0000CD07
AND T178._Fld50690_RRRef = T163._IDRRef
)
)
AND (T164.Fld50826RRef = @P129)
OR @P130 IN (
SELECT T179._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T179
WHERE (
(T179._Fld50691RRef = T173._ParentIDRRef)
OR (T179._Fld50691RRef = T164.Fld56279RRef)
)
AND (
T179._Fld50690_TYPE = 0x08
AND T179._Fld50690_RTRef = 0x0000CD07
AND T179._Fld50690_RRRef = T163._IDRRef
)
)
AND (T164.Fld50826RRef = @P131)
)
ORDER BY (T163._Date_Time)
) T162
UNION ALL
SELECT 0x0000C537
,T180.Q_001_F_000RRef
,0x05
,@P132
,T180.Q_001_F_001_
,T180.Q_001_F_002_
,T180.Q_001_F_003RRef
,T180.Q_001_F_004RRef
,T180.Q_001_F_005RRef
,0x08
,@P133
,T180.Q_001_F_006RRef
,T180.Q_001_F_007RRef
,T180.Q_001_F_008RRef
,T180.Q_001_F_009_
,T180.Q_001_F_010RRef
,T180.Q_001_F_011_
,T180.Q_001_F_012_
,CAST(T180.Q_001_F_013_ AS NVARCHAR(52))
,T180.Q_001_F_014_TYPE
,T180.Q_001_F_014_S
,T180.Q_001_F_014_RRRef
,T180.Q_001_F_015_
FROM (
SELECT TOP 1000 T181._IDRRef AS Q_001_F_000RRef
,T181._Number AS Q_001_F_001_
,T181._Date_Time AS Q_001_F_002_
,T181._Fld51154RRef AS Q_001_F_003RRef
,T181._Fld51132RRef AS Q_001_F_004RRef
,T181._Fld51164RRef AS Q_001_F_005RRef
,T181._Fld51134RRef AS Q_001_F_006RRef
,T182.Fld50826RRef AS Q_001_F_007RRef
,T182.Fld50828RRef AS Q_001_F_008RRef
,T182.Fld50827_ AS Q_001_F_009_
,T182.Fld50825RRef AS Q_001_F_010RRef
,T181._Fld51165 AS Q_001_F_011_
,CASE
WHEN (NOT (((T182.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P134 AS Q_001_F_013_
,CASE
WHEN T190._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T190._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T190._Q_001_F_001_TYPE IS NULL
THEN @P135
ELSE T190._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T190._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T190._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T181._Date_Time AS Q_001_F_015_
FROM dbo._Document50487X1 T181
LEFT OUTER JOIN (
SELECT T185._Fld50828RRef AS Fld50828RRef
,T185._Fld50826RRef AS Fld50826RRef
,T185._Fld56279RRef AS Fld56279RRef
,T185._Fld50824_TYPE AS Fld50824_TYPE
,T185._Fld50824_RTRef AS Fld50824_RTRef
,T185._Fld50824_RRRef AS Fld50824_RRRef
,T185._Fld50827 AS Fld50827_
,T185._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T184._Fld50824_TYPE AS Fld50824_TYPE
,T184._Fld50824_RTRef AS Fld50824_RTRef
,T184._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T184._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T184
GROUP BY T184._Fld50824_TYPE
,T184._Fld50824_RTRef
,T184._Fld50824_RRRef
) T183
INNER JOIN dbo._InfoRg50823X1 T185 ON T183.Fld50824_TYPE = T185._Fld50824_TYPE
AND T183.Fld50824_RTRef = T185._Fld50824_RTRef
AND T183.Fld50824_RRRef = T185._Fld50824_RRRef
AND T183.MAXPERIOD_ = T185._Period
) T182 ON (
0x08 = T182.Fld50824_TYPE
AND 0x0000C537 = T182.Fld50824_RTRef
AND T181._IDRRef = T182.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T189._Fld50704RRef AS Fld50704RRef
,T189._Fld50703_TYPE AS Fld50703_TYPE
,T189._Fld50703_RTRef AS Fld50703_RTRef
,T189._Fld50703_RRRef AS Fld50703_RRRef
,T189._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T188._Fld50703_TYPE AS Fld50703_TYPE
,T188._Fld50703_RTRef AS Fld50703_RTRef
,T188._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T188._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T188
GROUP BY T188._Fld50703_TYPE
,T188._Fld50703_RTRef
,T188._Fld50703_RRRef
) T187
INNER JOIN dbo._InfoRg50702X1 T189 ON T187.Fld50703_TYPE = T189._Fld50703_TYPE
AND T187.Fld50703_RTRef = T189._Fld50703_RTRef
AND T187.Fld50703_RRRef = T189._Fld50703_RRRef
AND T187.MAXPERIOD_ = T189._Period
) T186 ON (
0x08 = T186.Fld50703_TYPE
AND 0x0000C537 = T186.Fld50703_RTRef
AND T181._IDRRef = T186.Fld50703_RRRef
)
AND (T186.Fld50705RRef = @P136)
LEFT OUTER JOIN #tt59 T190 WITH (NOLOCK) ON (T181._Fld51134RRef
= T190._Q_001_F_000RRef)
AND (
(T181._Date_Time >= T190._Q_001_F_002)
AND (T181._Date_Time <= T190._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T191 ON T182.Fld50828RRef = T191._IDRRef
WHERE T181._Posted = 0x01
AND T182.Fld50828RRef IN (
SELECT T192._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T192 WITH (NOLOCK)
)
AND (
T182.Fld50828RRef IN (
SELECT T193._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T193 WITH (NOLOCK)
)
AND (T182.Fld50826RRef = @P137)
OR T191._ParentIDRRef IN (
SELECT T194._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T194 WITH (NOLOCK)
)
AND (T182.Fld50826RRef = @P138)
OR T182.Fld56279RRef IN (
SELECT T195._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T195 WITH (NOLOCK)
)
AND (T182.Fld50826RRef = @P139)
)
AND (
(T186.Fld50704RRef = @P140)
OR @P141 IN (
SELECT T196._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T196
WHERE (T196._Fld50691RRef = T182.Fld50828RRef)
AND (
T196._Fld50690_TYPE = 0x08
AND T196._Fld50690_RTRef = 0x0000C537
AND T196._Fld50690_RRRef = T181._IDRRef
)
)
AND (T182.Fld50826RRef = @P142)
OR @P143 IN (
SELECT T197._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T197
WHERE (
(T197._Fld50691RRef = T191._ParentIDRRef)
OR (T197._Fld50691RRef = T182.Fld56279RRef)
)
AND (
T197._Fld50690_TYPE = 0x08
AND T197._Fld50690_RTRef = 0x0000C537
AND T197._Fld50690_RRRef = T181._IDRRef
)
)
AND (T182.Fld50826RRef = @P144)
)
ORDER BY (T181._Date_Time)
) T180
UNION ALL
SELECT 0x0000C538
,T198.Q_001_F_000RRef
,0x05
,@P145
,T198.Q_001_F_001_
,T198.Q_001_F_002_
,T198.Q_001_F_003RRef
,T198.Q_001_F_004RRef
,T198.Q_001_F_005RRef
,0x08
,@P146
,T198.Q_001_F_006RRef
,T198.Q_001_F_007RRef
,T198.Q_001_F_008RRef
,T198.Q_001_F_009_
,T198.Q_001_F_010RRef
,T198.Q_001_F_011_
,T198.Q_001_F_012_
,CAST(T198.Q_001_F_013_ AS NVARCHAR(52))
,T198.Q_001_F_014_TYPE
,T198.Q_001_F_014_S
,T198.Q_001_F_014_RRRef
,T198.Q_001_F_015_
FROM (
SELECT TOP 1000 T199._IDRRef AS Q_001_F_000RRef
,T199._Number AS Q_001_F_001_
,T199._Date_Time AS Q_001_F_002_
,T199._Fld51181RRef AS Q_001_F_003RRef
,T199._Fld51180RRef AS Q_001_F_004RRef
,T199._Fld51185RRef AS Q_001_F_005RRef
,T199._Fld51186RRef AS Q_001_F_006RRef
,T200.Fld50826RRef AS Q_001_F_007RRef
,T200.Fld50828RRef AS Q_001_F_008RRef
,T200.Fld50827_ AS Q_001_F_009_
,T200.Fld50825RRef AS Q_001_F_010RRef
,T199._Fld51184 AS Q_001_F_011_
,CASE
WHEN (NOT (((T200.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P147 AS Q_001_F_013_
,CASE
WHEN T208._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T208._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T208._Q_001_F_001_TYPE IS NULL
THEN @P148
ELSE T208._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T208._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T208._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T199._Date_Time AS Q_001_F_015_
FROM dbo._Document50488X1 T199
LEFT OUTER JOIN (
SELECT T203._Fld50828RRef AS Fld50828RRef
,T203._Fld50826RRef AS Fld50826RRef
,T203._Fld56279RRef AS Fld56279RRef
,T203._Fld50824_TYPE AS Fld50824_TYPE
,T203._Fld50824_RTRef AS Fld50824_RTRef
,T203._Fld50824_RRRef AS Fld50824_RRRef
,T203._Fld50827 AS Fld50827_
,T203._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T202._Fld50824_TYPE AS Fld50824_TYPE
,T202._Fld50824_RTRef AS Fld50824_RTRef
,T202._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T202._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T202
GROUP BY T202._Fld50824_TYPE
,T202._Fld50824_RTRef
,T202._Fld50824_RRRef
) T201
INNER JOIN dbo._InfoRg50823X1 T203 ON T201.Fld50824_TYPE = T203._Fld50824_TYPE
AND T201.Fld50824_RTRef = T203._Fld50824_RTRef
AND T201.Fld50824_RRRef = T203._Fld50824_RRRef
AND T201.MAXPERIOD_ = T203._Period
) T200 ON (
0x08 = T200.Fld50824_TYPE
AND 0x0000C538 = T200.Fld50824_RTRef
AND T199._IDRRef = T200.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T207._Fld50704RRef AS Fld50704RRef
,T207._Fld50703_TYPE AS Fld50703_TYPE
,T207._Fld50703_RTRef AS Fld50703_RTRef
,T207._Fld50703_RRRef AS Fld50703_RRRef
,T207._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T206._Fld50703_TYPE AS Fld50703_TYPE
,T206._Fld50703_RTRef AS Fld50703_RTRef
,T206._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T206._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T206
GROUP BY T206._Fld50703_TYPE
,T206._Fld50703_RTRef
,T206._Fld50703_RRRef
) T205
INNER JOIN dbo._InfoRg50702X1 T207 ON T205.Fld50703_TYPE = T207._Fld50703_TYPE
AND T205.Fld50703_RTRef = T207._Fld50703_RTRef
AND T205.Fld50703_RRRef = T207._Fld50703_RRRef
AND T205.MAXPERIOD_ = T207._Period
) T204 ON (
0x08 = T204.Fld50703_TYPE
AND 0x0000C538 = T204.Fld50703_RTRef
AND T199._IDRRef = T204.Fld50703_RRRef
)
AND (T204.Fld50705RRef = @P149)
LEFT OUTER JOIN #tt59 T208 WITH (NOLOCK) ON (T199._Fld51186RRef
= T208._Q_001_F_000RRef)
AND (
(T199._Date_Time >= T208._Q_001_F_002)
AND (T199._Date_Time <= T208._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T209 ON T200.Fld50828RRef = T209._IDRRef
WHERE T199._Posted = 0x01
AND T200.Fld50828RRef IN (
SELECT T210._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T210 WITH (NOLOCK)
)
AND (
T200.Fld50828RRef IN (
SELECT T211._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T211 WITH (NOLOCK)
)
AND (T200.Fld50826RRef = @P150)
OR T209._ParentIDRRef IN (
SELECT T212._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T212 WITH (NOLOCK)
)
AND (T200.Fld50826RRef = @P151)
OR T200.Fld56279RRef IN (
SELECT T213._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T213 WITH (NOLOCK)
)
AND (T200.Fld50826RRef = @P152)
)
AND (
(T204.Fld50704RRef = @P153)
OR @P154 IN (
SELECT T214._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T214
WHERE (T214._Fld50691RRef = T200.Fld50828RRef)
AND (
T214._Fld50690_TYPE = 0x08
AND T214._Fld50690_RTRef = 0x0000C538
AND T214._Fld50690_RRRef = T199._IDRRef
)
)
AND (T200.Fld50826RRef = @P155)
OR @P156 IN (
SELECT T215._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T215
WHERE (
(T215._Fld50691RRef = T209._ParentIDRRef)
OR (T215._Fld50691RRef = T200.Fld56279RRef)
)
AND (
T215._Fld50690_TYPE = 0x08
AND T215._Fld50690_RTRef = 0x0000C538
AND T215._Fld50690_RRRef = T199._IDRRef
)
)
AND (T200.Fld50826RRef = @P157)
)
ORDER BY (T199._Date_Time)
) T198
UNION ALL
SELECT 0x0000C539
,T216.Q_001_F_000RRef
,0x05
,@P158
,T216.Q_001_F_001_
,T216.Q_001_F_002_
,T216.Q_001_F_003RRef
,T216.Q_001_F_004RRef
,T216.Q_001_F_005RRef
,0x08
,@P159
,T216.Q_001_F_006RRef
,T216.Q_001_F_007RRef
,T216.Q_001_F_008RRef
,T216.Q_001_F_009_
,T216.Q_001_F_010RRef
,T216.Q_001_F_011_
,T216.Q_001_F_012_
,CAST(T216.Q_001_F_013_ AS NVARCHAR(52))
,T216.Q_001_F_014_TYPE
,T216.Q_001_F_014_S
,T216.Q_001_F_014_RRRef
,T216.Q_001_F_015_
FROM (
SELECT TOP 1000 T217._IDRRef AS Q_001_F_000RRef
,T217._Number AS Q_001_F_001_
,T217._Date_Time AS Q_001_F_002_
,T217._Fld51243RRef AS Q_001_F_003RRef
,T217._Fld51242RRef AS Q_001_F_004RRef
,T217._Fld51247RRef AS Q_001_F_005RRef
,T217._Fld51248RRef AS Q_001_F_006RRef
,T218.Fld50826RRef AS Q_001_F_007RRef
,T218.Fld50828RRef AS Q_001_F_008RRef
,T218.Fld50827_ AS Q_001_F_009_
,T218.Fld50825RRef AS Q_001_F_010RRef
,T217._Fld51246 AS Q_001_F_011_
,CASE
WHEN (NOT (((T218.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P160 AS Q_001_F_013_
,CASE
WHEN T226._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T226._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T226._Q_001_F_001_TYPE IS NULL
THEN @P161
ELSE T226._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T226._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T226._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T217._Date_Time AS Q_001_F_015_
FROM dbo._Document50489X1 T217
LEFT OUTER JOIN (
SELECT T221._Fld50828RRef AS Fld50828RRef
,T221._Fld50826RRef AS Fld50826RRef
,T221._Fld56279RRef AS Fld56279RRef
,T221._Fld50824_TYPE AS Fld50824_TYPE
,T221._Fld50824_RTRef AS Fld50824_RTRef
,T221._Fld50824_RRRef AS Fld50824_RRRef
,T221._Fld50827 AS Fld50827_
,T221._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T220._Fld50824_TYPE AS Fld50824_TYPE
,T220._Fld50824_RTRef AS Fld50824_RTRef
,T220._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T220._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T220
GROUP BY T220._Fld50824_TYPE
,T220._Fld50824_RTRef
,T220._Fld50824_RRRef
) T219
INNER JOIN dbo._InfoRg50823X1 T221 ON T219.Fld50824_TYPE = T221._Fld50824_TYPE
AND T219.Fld50824_RTRef = T221._Fld50824_RTRef
AND T219.Fld50824_RRRef = T221._Fld50824_RRRef
AND T219.MAXPERIOD_ = T221._Period
) T218 ON (
0x08 = T218.Fld50824_TYPE
AND 0x0000C539 = T218.Fld50824_RTRef
AND T217._IDRRef = T218.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T225._Fld50704RRef AS Fld50704RRef
,T225._Fld50703_TYPE AS Fld50703_TYPE
,T225._Fld50703_RTRef AS Fld50703_RTRef
,T225._Fld50703_RRRef AS Fld50703_RRRef
,T225._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T224._Fld50703_TYPE AS Fld50703_TYPE
,T224._Fld50703_RTRef AS Fld50703_RTRef
,T224._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T224._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T224
GROUP BY T224._Fld50703_TYPE
,T224._Fld50703_RTRef
,T224._Fld50703_RRRef
) T223
INNER JOIN dbo._InfoRg50702X1 T225 ON T223.Fld50703_TYPE = T225._Fld50703_TYPE
AND T223.Fld50703_RTRef = T225._Fld50703_RTRef
AND T223.Fld50703_RRRef = T225._Fld50703_RRRef
AND T223.MAXPERIOD_ = T225._Period
) T222 ON (
0x08 = T222.Fld50703_TYPE
AND 0x0000C539 = T222.Fld50703_RTRef
AND T217._IDRRef = T222.Fld50703_RRRef
)
AND (T222.Fld50705RRef = @P162)
LEFT OUTER JOIN #tt59 T226 WITH (NOLOCK) ON (T217._Fld51248RRef
= T226._Q_001_F_000RRef)
AND (
(T217._Date_Time >= T226._Q_001_F_002)
AND (T217._Date_Time <= T226._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T227 ON T218.Fld50828RRef = T227._IDRRef
WHERE T217._Posted = 0x01
AND T218.Fld50828RRef IN (
SELECT T228._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T228 WITH (NOLOCK)
)
AND (
T218.Fld50828RRef IN (
SELECT T229._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T229 WITH (NOLOCK)
)
AND (T218.Fld50826RRef = @P163)
OR T227._ParentIDRRef IN (
SELECT T230._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T230 WITH (NOLOCK)
)
AND (T218.Fld50826RRef = @P164)
OR T218.Fld56279RRef IN (
SELECT T231._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T231 WITH (NOLOCK)
)
AND (T218.Fld50826RRef = @P165)
)
AND (
(T222.Fld50704RRef = @P166)
OR @P167 IN (
SELECT T232._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T232
WHERE (T232._Fld50691RRef = T218.Fld50828RRef)
AND (
T232._Fld50690_TYPE = 0x08
AND T232._Fld50690_RTRef = 0x0000C539
AND T232._Fld50690_RRRef = T217._IDRRef
)
)
AND (T218.Fld50826RRef = @P168)
OR @P169 IN (
SELECT T233._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T233
WHERE (
(T233._Fld50691RRef = T227._ParentIDRRef)
OR (T233._Fld50691RRef = T218.Fld56279RRef)
)
AND (
T233._Fld50690_TYPE = 0x08
AND T233._Fld50690_RTRef = 0x0000C539
AND T233._Fld50690_RRRef = T217._IDRRef
)
)
AND (T218.Fld50826RRef = @P170)
)
ORDER BY (T217._Date_Time)
) T216
UNION ALL
SELECT 0x0000CD0D
,T234.Q_001_F_000RRef
,0x05
,@P171
,CAST(T234.Q_001_F_001_ AS NVARCHAR(11))
,T234.Q_001_F_002_
,T234.Q_001_F_003RRef
,T234.Q_001_F_004RRef
,T234.Q_001_F_005RRef
,0x05
,CAST(T234.Q_001_F_006_ AS NVARCHAR(150))
,0x00000000000000000000000000000000
,T234.Q_001_F_007RRef
,T234.Q_001_F_008RRef
,T234.Q_001_F_009_
,T234.Q_001_F_010RRef
,T234.Q_001_F_011_
,T234.Q_001_F_012_
,CAST(T234.Q_001_F_013_ AS NVARCHAR(52))
,0x08
,@P172
,T234.Q_001_F_014RRef
,T234.Q_001_F_015_
FROM (
SELECT TOP 1000 T235._IDRRef AS Q_001_F_000RRef
,T235._Number AS Q_001_F_001_
,T235._Date_Time AS Q_001_F_002_
,T235._Fld52746RRef AS Q_001_F_003RRef
,T235._Fld52730RRef AS Q_001_F_004RRef
,T235._Fld52745RRef AS Q_001_F_005RRef
,T235._Fld52754 AS Q_001_F_006_
,T236.Fld50826RRef AS Q_001_F_007RRef
,T236.Fld50828RRef AS Q_001_F_008RRef
,T236.Fld50827_ AS Q_001_F_009_
,T236.Fld50825RRef AS Q_001_F_010RRef
,T235._Fld52744 AS Q_001_F_011_
,CASE
WHEN (NOT (((T236.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P173 AS Q_001_F_013_
,T235._Fld52731RRef AS Q_001_F_014RRef
,T235._Date_Time AS Q_001_F_015_
FROM dbo._Document52493X1 T235
LEFT OUTER JOIN (
SELECT T239._Fld50828RRef AS Fld50828RRef
,T239._Fld50826RRef AS Fld50826RRef
,T239._Fld56279RRef AS Fld56279RRef
,T239._Fld50824_TYPE AS Fld50824_TYPE
,T239._Fld50824_RTRef AS Fld50824_RTRef
,T239._Fld50824_RRRef AS Fld50824_RRRef
,T239._Fld50827 AS Fld50827_
,T239._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T238._Fld50824_TYPE AS Fld50824_TYPE
,T238._Fld50824_RTRef AS Fld50824_RTRef
,T238._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T238._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T238
GROUP BY T238._Fld50824_TYPE
,T238._Fld50824_RTRef
,T238._Fld50824_RRRef
) T237
INNER JOIN dbo._InfoRg50823X1 T239 ON T237.Fld50824_TYPE = T239._Fld50824_TYPE
AND T237.Fld50824_RTRef = T239._Fld50824_RTRef
AND T237.Fld50824_RRRef = T239._Fld50824_RRRef
AND T237.MAXPERIOD_ = T239._Period
) T236 ON (
0x08 = T236.Fld50824_TYPE
AND 0x0000CD0D = T236.Fld50824_RTRef
AND T235._IDRRef = T236.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T243._Fld50704RRef AS Fld50704RRef
,T243._Fld50703_TYPE AS Fld50703_TYPE
,T243._Fld50703_RTRef AS Fld50703_RTRef
,T243._Fld50703_RRRef AS Fld50703_RRRef
,T243._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T242._Fld50703_TYPE AS Fld50703_TYPE
,T242._Fld50703_RTRef AS Fld50703_RTRef
,T242._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T242._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T242
GROUP BY T242._Fld50703_TYPE
,T242._Fld50703_RTRef
,T242._Fld50703_RRRef
) T241
INNER JOIN dbo._InfoRg50702X1 T243 ON T241.Fld50703_TYPE = T243._Fld50703_TYPE
AND T241.Fld50703_RTRef = T243._Fld50703_RTRef
AND T241.Fld50703_RRRef = T243._Fld50703_RRRef
AND T241.MAXPERIOD_ = T243._Period
) T240 ON (
0x08 = T240.Fld50703_TYPE
AND 0x0000CD0D = T240.Fld50703_RTRef
AND T235._IDRRef = T240.Fld50703_RRRef
)
AND (T240.Fld50705RRef = @P174)
LEFT OUTER JOIN dbo._Reference50477X1 T244 ON T236.Fld50828RRef = T244._IDRRef
WHERE T235._Posted = 0x01
AND T236.Fld50828RRef IN (
SELECT T245._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T245 WITH (NOLOCK)
)
AND (
T236.Fld50828RRef IN (
SELECT T246._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T246 WITH (NOLOCK)
)
AND (T236.Fld50826RRef = @P175)
OR T244._ParentIDRRef IN (
SELECT T247._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T247 WITH (NOLOCK)
)
AND (T236.Fld50826RRef = @P176)
OR T236.Fld56279RRef IN (
SELECT T248._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T248 WITH (NOLOCK)
)
AND (T236.Fld50826RRef = @P177)
)
AND (
(T240.Fld50704RRef = @P178)
OR @P179 IN (
SELECT T249._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T249
WHERE (T249._Fld50691RRef = T236.Fld50828RRef)
AND (
T249._Fld50690_TYPE = 0x08
AND T249._Fld50690_RTRef = 0x0000CD0D
AND T249._Fld50690_RRRef = T235._IDRRef
)
)
AND (T236.Fld50826RRef = @P180)
OR @P181 IN (
SELECT T250._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T250
WHERE (
(T250._Fld50691RRef = T244._ParentIDRRef)
OR (T250._Fld50691RRef = T236.Fld56279RRef)
)
AND (
T250._Fld50690_TYPE = 0x08
AND T250._Fld50690_RTRef = 0x0000CD0D
AND T250._Fld50690_RRRef = T235._IDRRef
)
)
AND (T236.Fld50826RRef = @P182)
)
ORDER BY (T235._Date_Time)
) T234
UNION ALL
SELECT 0x0000D079
,T251.Q_001_F_000RRef
,0x05
,@P183
,CAST(T251.Q_001_F_001_ AS NVARCHAR(11))
,T251.Q_001_F_002_
,T251.Q_001_F_003RRef
,T251.Q_001_F_004RRef
,T251.Q_001_F_005RRef
,0x08
,@P184
,T251.Q_001_F_006RRef
,T251.Q_001_F_007RRef
,T251.Q_001_F_008RRef
,T251.Q_001_F_009_
,T251.Q_001_F_010RRef
,T251.Q_001_F_011_
,T251.Q_001_F_012_
,CAST(T251.Q_001_F_013_ AS NVARCHAR(52))
,T251.Q_001_F_014_TYPE
,T251.Q_001_F_014_S
,T251.Q_001_F_014_RRRef
,T251.Q_001_F_015_
FROM (
SELECT TOP 1000 T252._IDRRef AS Q_001_F_000RRef
,T252._Number AS Q_001_F_001_
,T252._Date_Time AS Q_001_F_002_
,T252._Fld53377RRef AS Q_001_F_003RRef
,T252._Fld53376RRef AS Q_001_F_004RRef
,T252._Fld53381RRef AS Q_001_F_005RRef
,T252._Fld53382RRef AS Q_001_F_006RRef
,T253.Fld50826RRef AS Q_001_F_007RRef
,T253.Fld50828RRef AS Q_001_F_008RRef
,T253.Fld50827_ AS Q_001_F_009_
,T253.Fld50825RRef AS Q_001_F_010RRef
,T252._Fld53380 AS Q_001_F_011_
,CASE
WHEN (NOT (((T253.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P185 AS Q_001_F_013_
,CASE
WHEN T261._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T261._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T261._Q_001_F_001_TYPE IS NULL
THEN @P186
ELSE T261._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T261._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T261._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T252._Date_Time AS Q_001_F_015_
FROM dbo._Document53369X1 T252
LEFT OUTER JOIN (
SELECT T256._Fld50828RRef AS Fld50828RRef
,T256._Fld50826RRef AS Fld50826RRef
,T256._Fld56279RRef AS Fld56279RRef
,T256._Fld50824_TYPE AS Fld50824_TYPE
,T256._Fld50824_RTRef AS Fld50824_RTRef
,T256._Fld50824_RRRef AS Fld50824_RRRef
,T256._Fld50827 AS Fld50827_
,T256._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T255._Fld50824_TYPE AS Fld50824_TYPE
,T255._Fld50824_RTRef AS Fld50824_RTRef
,T255._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T255._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T255
GROUP BY T255._Fld50824_TYPE
,T255._Fld50824_RTRef
,T255._Fld50824_RRRef
) T254
INNER JOIN dbo._InfoRg50823X1 T256 ON T254.Fld50824_TYPE = T256._Fld50824_TYPE
AND T254.Fld50824_RTRef = T256._Fld50824_RTRef
AND T254.Fld50824_RRRef = T256._Fld50824_RRRef
AND T254.MAXPERIOD_ = T256._Period
) T253 ON (
0x08 = T253.Fld50824_TYPE
AND 0x0000D079 = T253.Fld50824_RTRef
AND T252._IDRRef = T253.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T260._Fld50704RRef AS Fld50704RRef
,T260._Fld50703_TYPE AS Fld50703_TYPE
,T260._Fld50703_RTRef AS Fld50703_RTRef
,T260._Fld50703_RRRef AS Fld50703_RRRef
,T260._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T259._Fld50703_TYPE AS Fld50703_TYPE
,T259._Fld50703_RTRef AS Fld50703_RTRef
,T259._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T259._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T259
GROUP BY T259._Fld50703_TYPE
,T259._Fld50703_RTRef
,T259._Fld50703_RRRef
) T258
INNER JOIN dbo._InfoRg50702X1 T260 ON T258.Fld50703_TYPE = T260._Fld50703_TYPE
AND T258.Fld50703_RTRef = T260._Fld50703_RTRef
AND T258.Fld50703_RRRef = T260._Fld50703_RRRef
AND T258.MAXPERIOD_ = T260._Period
) T257 ON (
0x08 = T257.Fld50703_TYPE
AND 0x0000D079 = T257.Fld50703_RTRef
AND T252._IDRRef = T257.Fld50703_RRRef
)
AND (T257.Fld50705RRef = @P187)
LEFT OUTER JOIN #tt59 T261 WITH (NOLOCK) ON (T252._Fld53382RRef
= T261._Q_001_F_000RRef)
AND (
(T252._Date_Time >= T261._Q_001_F_002)
AND (T252._Date_Time <= T261._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T262 ON T253.Fld50828RRef = T262._IDRRef
WHERE T252._Posted = 0x01
AND T253.Fld50828RRef IN (
SELECT T263._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T263 WITH (NOLOCK)
)
AND (
T253.Fld50828RRef IN (
SELECT T264._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T264 WITH (NOLOCK)
)
AND (T253.Fld50826RRef = @P188)
OR T262._ParentIDRRef IN (
SELECT T265._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T265 WITH (NOLOCK)
)
AND (T253.Fld50826RRef = @P189)
OR T253.Fld56279RRef IN (
SELECT T266._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T266 WITH (NOLOCK)
)
AND (T253.Fld50826RRef = @P190)
)
AND (
(T257.Fld50704RRef = @P191)
OR @P192 IN (
SELECT T267._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T267
WHERE (T267._Fld50691RRef = T253.Fld50828RRef)
AND (
T267._Fld50690_TYPE = 0x08
AND T267._Fld50690_RTRef = 0x0000D079
AND T267._Fld50690_RRRef = T252._IDRRef
)
)
AND (T253.Fld50826RRef = @P193)
OR @P194 IN (
SELECT T268._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T268
WHERE (
(T268._Fld50691RRef = T262._ParentIDRRef)
OR (T268._Fld50691RRef = T253.Fld56279RRef)
)
AND (
T268._Fld50690_TYPE = 0x08
AND T268._Fld50690_RTRef = 0x0000D079
AND T268._Fld50690_RRRef = T252._IDRRef
)
)
AND (T253.Fld50826RRef = @P195)
)
ORDER BY (T252._Date_Time)
) T251
UNION ALL
SELECT 0x0000C53A
,T269.Q_001_F_000RRef
,0x05
,@P196
,T269.Q_001_F_001_
,T269.Q_001_F_002_
,T269.Q_001_F_003RRef
,T269.Q_001_F_004RRef
,T269.Q_001_F_005RRef
,0x05
,CAST(T269.Q_001_F_006_ AS NVARCHAR(150))
,0x00000000000000000000000000000000
,T269.Q_001_F_007RRef
,T269.Q_001_F_008RRef
,T269.Q_001_F_009_
,T269.Q_001_F_010RRef
,T269.Q_001_F_011_
,T269.Q_001_F_012_
,CAST(T269.Q_001_F_013_ AS NVARCHAR(52))
,CASE
WHEN T269.Q_001_F_014_TYPE IN (0x05)
THEN T269.Q_001_F_014_TYPE
WHEN T269.Q_001_F_014_TYPE = 0x08
AND T269.Q_001_F_014_RTRef = 0x0000BFFD
THEN 0x08
END
,CASE
WHEN T269.Q_001_F_014_TYPE = 0x05
THEN T269.Q_001_F_014_S
WHEN T269.Q_001_F_014_TYPE IN (0x08)
THEN @P197
END
,CASE
WHEN T269.Q_001_F_014_TYPE = 0x08
AND T269.Q_001_F_014_RTRef = 0x0000BFFD
THEN T269.Q_001_F_014_RRRef
WHEN T269.Q_001_F_014_TYPE IN (0x05)
THEN 0x00000000000000000000000000000000
END
,T269.Q_001_F_015_
FROM (
SELECT TOP 1000 T270._IDRRef AS Q_001_F_000RRef
,T270._Number AS Q_001_F_001_
,T270._Date_Time AS Q_001_F_002_
,T270._Fld51273RRef AS Q_001_F_003RRef
,T270._Fld51261RRef AS Q_001_F_004RRef
,T270._Fld51277RRef AS Q_001_F_005RRef
,T270._Fld51262 AS Q_001_F_006_
,T271.Fld50826RRef AS Q_001_F_007RRef
,T271.Fld50828RRef AS Q_001_F_008RRef
,T271.Fld50827_ AS Q_001_F_009_
,T271.Fld50825RRef AS Q_001_F_010RRef
,T270._Fld51278 AS Q_001_F_011_
,CASE
WHEN (NOT (((T271.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P198 AS Q_001_F_013_
,CAST(NULL AS BINARY (1)) AS Q_001_F_014_TYPE
,CAST(NULL AS BINARY (1)) AS Q_001_F_014_L
,CAST(NULL AS NUMERIC(38, 8)) AS Q_001_F_014_N
,CAST(NULL AS DATETIME) AS Q_001_F_014_T
,CAST(NULL AS NVARCHAR) AS Q_001_F_014_S
,CAST(NULL AS VARBINARY) AS Q_001_F_014_B
,CAST(NULL AS BINARY (4)) AS Q_001_F_014_RTRef
,CAST(NULL AS BINARY (16)) AS Q_001_F_014_RRRef
,T270._Date_Time AS Q_001_F_015_
FROM dbo._Document50490X1 T270
LEFT OUTER JOIN (
SELECT T274._Fld50828RRef AS Fld50828RRef
,T274._Fld50826RRef AS Fld50826RRef
,T274._Fld56279RRef AS Fld56279RRef
,T274._Fld50824_TYPE AS Fld50824_TYPE
,T274._Fld50824_RTRef AS Fld50824_RTRef
,T274._Fld50824_RRRef AS Fld50824_RRRef
,T274._Fld50827 AS Fld50827_
,T274._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T273._Fld50824_TYPE AS Fld50824_TYPE
,T273._Fld50824_RTRef AS Fld50824_RTRef
,T273._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T273._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T273
GROUP BY T273._Fld50824_TYPE
,T273._Fld50824_RTRef
,T273._Fld50824_RRRef
) T272
INNER JOIN dbo._InfoRg50823X1 T274 ON T272.Fld50824_TYPE = T274._Fld50824_TYPE
AND T272.Fld50824_RTRef = T274._Fld50824_RTRef
AND T272.Fld50824_RRRef = T274._Fld50824_RRRef
AND T272.MAXPERIOD_ = T274._Period
) T271 ON (
0x08 = T271.Fld50824_TYPE
AND 0x0000C53A = T271.Fld50824_RTRef
AND T270._IDRRef = T271.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T278._Fld50704RRef AS Fld50704RRef
,T278._Fld50703_TYPE AS Fld50703_TYPE
,T278._Fld50703_RTRef AS Fld50703_RTRef
,T278._Fld50703_RRRef AS Fld50703_RRRef
,T278._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T277._Fld50703_TYPE AS Fld50703_TYPE
,T277._Fld50703_RTRef AS Fld50703_RTRef
,T277._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T277._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T277
GROUP BY T277._Fld50703_TYPE
,T277._Fld50703_RTRef
,T277._Fld50703_RRRef
) T276
INNER JOIN dbo._InfoRg50702X1 T278 ON T276.Fld50703_TYPE = T278._Fld50703_TYPE
AND T276.Fld50703_RTRef = T278._Fld50703_RTRef
AND T276.Fld50703_RRRef = T278._Fld50703_RRRef
AND T276.MAXPERIOD_ = T278._Period
) T275 ON (
0x08 = T275.Fld50703_TYPE
AND 0x0000C53A = T275.Fld50703_RTRef
AND T270._IDRRef = T275.Fld50703_RRRef
)
AND (T275.Fld50705RRef = @P199)
LEFT OUTER JOIN dbo._Reference50477X1 T279 ON T271.Fld50828RRef = T279._IDRRef
WHERE T270._Posted = 0x01
AND T271.Fld50828RRef IN (
SELECT T280._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T280 WITH (NOLOCK)
)
AND (
T271.Fld50828RRef IN (
SELECT T281._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T281 WITH (NOLOCK)
)
AND (T271.Fld50826RRef = @P200)
OR T279._ParentIDRRef IN (
SELECT T282._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T282 WITH (NOLOCK)
)
AND (T271.Fld50826RRef = @P201)
OR T271.Fld56279RRef IN (
SELECT T283._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T283 WITH (NOLOCK)
)
AND (T271.Fld50826RRef = @P202)
)
AND (
(T275.Fld50704RRef = @P203)
OR @P204 IN (
SELECT T284._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T284
WHERE (T284._Fld50691RRef = T271.Fld50828RRef)
AND (
T284._Fld50690_TYPE = 0x08
AND T284._Fld50690_RTRef = 0x0000C53A
AND T284._Fld50690_RRRef = T270._IDRRef
)
)
AND (T271.Fld50826RRef = @P205)
OR @P206 IN (
SELECT T285._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T285
WHERE (
(T285._Fld50691RRef = T279._ParentIDRRef)
OR (T285._Fld50691RRef = T271.Fld56279RRef)
)
AND (
T285._Fld50690_TYPE = 0x08
AND T285._Fld50690_RTRef = 0x0000C53A
AND T285._Fld50690_RRRef = T270._IDRRef
)
)
AND (T271.Fld50826RRef = @P207)
)
ORDER BY (T270._Date_Time)
) T269
UNION ALL
SELECT 0x0000CD0A
,T286.Q_001_F_000RRef
,0x05
,@P208
,CAST(T286.Q_001_F_001_ AS NVARCHAR(11))
,T286.Q_001_F_002_
,T286.Q_001_F_003RRef
,T286.Q_001_F_004RRef
,T286.Q_001_F_005RRef
,0x05
,CAST(T286.Q_001_F_006_ AS NVARCHAR(150))
,0x00000000000000000000000000000000
,T286.Q_001_F_007RRef
,T286.Q_001_F_008RRef
,T286.Q_001_F_009_
,T286.Q_001_F_010RRef
,T286.Q_001_F_011_
,T286.Q_001_F_012_
,CAST(T286.Q_001_F_013_ AS NVARCHAR(52))
,0x08
,@P209
,T286.Q_001_F_014RRef
,T286.Q_001_F_015_
FROM (
SELECT TOP 1000 T287._IDRRef AS Q_001_F_000RRef
,T287._Number AS Q_001_F_001_
,T287._Date_Time AS Q_001_F_002_
,T287._Fld52644RRef AS Q_001_F_003RRef
,T287._Fld52628RRef AS Q_001_F_004RRef
,T287._Fld52643RRef AS Q_001_F_005RRef
,T287._Fld52652 AS Q_001_F_006_
,T288.Fld50826RRef AS Q_001_F_007RRef
,T288.Fld50828RRef AS Q_001_F_008RRef
,T288.Fld50827_ AS Q_001_F_009_
,T288.Fld50825RRef AS Q_001_F_010RRef
,T287._Fld52642 AS Q_001_F_011_
,CASE
WHEN (NOT (((T288.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P210 AS Q_001_F_013_
,T287._Fld52629RRef AS Q_001_F_014RRef
,T287._Date_Time AS Q_001_F_015_
FROM dbo._Document52490X1 T287
LEFT OUTER JOIN (
SELECT T291._Fld50828RRef AS Fld50828RRef
,T291._Fld50826RRef AS Fld50826RRef
,T291._Fld56279RRef AS Fld56279RRef
,T291._Fld50824_TYPE AS Fld50824_TYPE
,T291._Fld50824_RTRef AS Fld50824_RTRef
,T291._Fld50824_RRRef AS Fld50824_RRRef
,T291._Fld50827 AS Fld50827_
,T291._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T290._Fld50824_TYPE AS Fld50824_TYPE
,T290._Fld50824_RTRef AS Fld50824_RTRef
,T290._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T290._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T290
GROUP BY T290._Fld50824_TYPE
,T290._Fld50824_RTRef
,T290._Fld50824_RRRef
) T289
INNER JOIN dbo._InfoRg50823X1 T291 ON T289.Fld50824_TYPE = T291._Fld50824_TYPE
AND T289.Fld50824_RTRef = T291._Fld50824_RTRef
AND T289.Fld50824_RRRef = T291._Fld50824_RRRef
AND T289.MAXPERIOD_ = T291._Period
) T288 ON (
0x08 = T288.Fld50824_TYPE
AND 0x0000CD0A = T288.Fld50824_RTRef
AND T287._IDRRef = T288.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T295._Fld50704RRef AS Fld50704RRef
,T295._Fld50703_TYPE AS Fld50703_TYPE
,T295._Fld50703_RTRef AS Fld50703_RTRef
,T295._Fld50703_RRRef AS Fld50703_RRRef
,T295._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T294._Fld50703_TYPE AS Fld50703_TYPE
,T294._Fld50703_RTRef AS Fld50703_RTRef
,T294._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T294._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T294
GROUP BY T294._Fld50703_TYPE
,T294._Fld50703_RTRef
,T294._Fld50703_RRRef
) T293
INNER JOIN dbo._InfoRg50702X1 T295 ON T293.Fld50703_TYPE = T295._Fld50703_TYPE
AND T293.Fld50703_RTRef = T295._Fld50703_RTRef
AND T293.Fld50703_RRRef = T295._Fld50703_RRRef
AND T293.MAXPERIOD_ = T295._Period
) T292 ON (
0x08 = T292.Fld50703_TYPE
AND 0x0000CD0A = T292.Fld50703_RTRef
AND T287._IDRRef = T292.Fld50703_RRRef
)
AND (T292.Fld50705RRef = @P211)
LEFT OUTER JOIN dbo._Reference50477X1 T296 ON T288.Fld50828RRef = T296._IDRRef
WHERE T287._Posted = 0x01
AND T288.Fld50828RRef IN (
SELECT T297._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T297 WITH (NOLOCK)
)
AND (
T288.Fld50828RRef IN (
SELECT T298._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T298 WITH (NOLOCK)
)
AND (T288.Fld50826RRef = @P212)
OR T296._ParentIDRRef IN (
SELECT T299._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T299 WITH (NOLOCK)
)
AND (T288.Fld50826RRef = @P213)
OR T288.Fld56279RRef IN (
SELECT T300._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T300 WITH (NOLOCK)
)
AND (T288.Fld50826RRef = @P214)
)
AND (
(T292.Fld50704RRef = @P215)
OR @P216 IN (
SELECT T301._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T301
WHERE (T301._Fld50691RRef = T288.Fld50828RRef)
AND (
T301._Fld50690_TYPE = 0x08
AND T301._Fld50690_RTRef = 0x0000CD0A
AND T301._Fld50690_RRRef = T287._IDRRef
)
)
AND (T288.Fld50826RRef = @P217)
OR @P218 IN (
SELECT T302._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T302
WHERE (
(T302._Fld50691RRef = T296._ParentIDRRef)
OR (T302._Fld50691RRef = T288.Fld56279RRef)
)
AND (
T302._Fld50690_TYPE = 0x08
AND T302._Fld50690_RTRef = 0x0000CD0A
AND T302._Fld50690_RRRef = T287._IDRRef
)
)
AND (T288.Fld50826RRef = @P219)
)
ORDER BY (T287._Date_Time)
) T286
UNION ALL
SELECT 0x0000CD09
,T303.Q_001_F_000RRef
,0x05
,@P220
,CAST(T303.Q_001_F_001_ AS NVARCHAR(11))
,T303.Q_001_F_002_
,T303.Q_001_F_003RRef
,T303.Q_001_F_004RRef
,T303.Q_001_F_005RRef
,0x05
,CAST(T303.Q_001_F_006_ AS NVARCHAR(150))
,0x00000000000000000000000000000000
,T303.Q_001_F_007RRef
,T303.Q_001_F_008RRef
,T303.Q_001_F_009_
,T303.Q_001_F_010RRef
,T303.Q_001_F_011_
,T303.Q_001_F_012_
,T303.Q_001_F_013_
,0x08
,@P221
,T303.Q_001_F_014RRef
,T303.Q_001_F_015_
FROM (
SELECT TOP 1000 T304._IDRRef AS Q_001_F_000RRef
,T304._Number AS Q_001_F_001_
,T304._Date_Time AS Q_001_F_002_
,T304._Fld52607RRef AS Q_001_F_003RRef
,T304._Fld52591RRef AS Q_001_F_004RRef
,T304._Fld52606RRef AS Q_001_F_005RRef
,T304._Fld52615 AS Q_001_F_006_
,T305.Fld50826RRef AS Q_001_F_007RRef
,T305.Fld50828RRef AS Q_001_F_008RRef
,T305.Fld50827_ AS Q_001_F_009_
,T305.Fld50825RRef AS Q_001_F_010RRef
,T304._Fld52605 AS Q_001_F_011_
,CASE
WHEN (NOT (((T305.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P222 AS Q_001_F_013_
,T304._Fld52592RRef AS Q_001_F_014RRef
,T304._Date_Time AS Q_001_F_015_
FROM dbo._Document52489X1 T304
LEFT OUTER JOIN (
SELECT T308._Fld50828RRef AS Fld50828RRef
,T308._Fld50826RRef AS Fld50826RRef
,T308._Fld56279RRef AS Fld56279RRef
,T308._Fld50824_TYPE AS Fld50824_TYPE
,T308._Fld50824_RTRef AS Fld50824_RTRef
,T308._Fld50824_RRRef AS Fld50824_RRRef
,T308._Fld50827 AS Fld50827_
,T308._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T307._Fld50824_TYPE AS Fld50824_TYPE
,T307._Fld50824_RTRef AS Fld50824_RTRef
,T307._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T307._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T307
GROUP BY T307._Fld50824_TYPE
,T307._Fld50824_RTRef
,T307._Fld50824_RRRef
) T306
INNER JOIN dbo._InfoRg50823X1 T308 ON T306.Fld50824_TYPE = T308._Fld50824_TYPE
AND T306.Fld50824_RTRef = T308._Fld50824_RTRef
AND T306.Fld50824_RRRef = T308._Fld50824_RRRef
AND T306.MAXPERIOD_ = T308._Period
) T305 ON (
0x08 = T305.Fld50824_TYPE
AND 0x0000CD09 = T305.Fld50824_RTRef
AND T304._IDRRef = T305.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T312._Fld50704RRef AS Fld50704RRef
,T312._Fld50703_TYPE AS Fld50703_TYPE
,T312._Fld50703_RTRef AS Fld50703_RTRef
,T312._Fld50703_RRRef AS Fld50703_RRRef
,T312._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T311._Fld50703_TYPE AS Fld50703_TYPE
,T311._Fld50703_RTRef AS Fld50703_RTRef
,T311._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T311._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T311
GROUP BY T311._Fld50703_TYPE
,T311._Fld50703_RTRef
,T311._Fld50703_RRRef
) T310
INNER JOIN dbo._InfoRg50702X1 T312 ON T310.Fld50703_TYPE = T312._Fld50703_TYPE
AND T310.Fld50703_RTRef = T312._Fld50703_RTRef
AND T310.Fld50703_RRRef = T312._Fld50703_RRRef
AND T310.MAXPERIOD_ = T312._Period
) T309 ON (
0x08 = T309.Fld50703_TYPE
AND 0x0000CD09 = T309.Fld50703_RTRef
AND T304._IDRRef = T309.Fld50703_RRRef
)
AND (T309.Fld50705RRef = @P223)
LEFT OUTER JOIN dbo._Reference50477X1 T313 ON T305.Fld50828RRef = T313._IDRRef
WHERE T304._Posted = 0x01
AND T305.Fld50828RRef IN (
SELECT T314._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T314 WITH (NOLOCK)
)
AND (
T305.Fld50828RRef IN (
SELECT T315._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T315 WITH (NOLOCK)
)
AND (T305.Fld50826RRef = @P224)
OR T313._ParentIDRRef IN (
SELECT T316._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T316 WITH (NOLOCK)
)
AND (T305.Fld50826RRef = @P225)
OR T305.Fld56279RRef IN (
SELECT T317._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T317 WITH (NOLOCK)
)
AND (T305.Fld50826RRef = @P226)
)
AND (
(T309.Fld50704RRef = @P227)
OR @P228 IN (
SELECT T318._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T318
WHERE (T318._Fld50691RRef = T305.Fld50828RRef)
AND (
T318._Fld50690_TYPE = 0x08
AND T318._Fld50690_RTRef = 0x0000CD09
AND T318._Fld50690_RRRef = T304._IDRRef
)
)
AND (T305.Fld50826RRef = @P229)
OR @P230 IN (
SELECT T319._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T319
WHERE (
(T319._Fld50691RRef = T313._ParentIDRRef)
OR (T319._Fld50691RRef = T305.Fld56279RRef)
)
AND (
T319._Fld50690_TYPE = 0x08
AND T319._Fld50690_RTRef = 0x0000CD09
AND T319._Fld50690_RRRef = T304._IDRRef
)
)
AND (T305.Fld50826RRef = @P231)
)
ORDER BY (T304._Date_Time)
) T303
UNION ALL
SELECT 0x0000C53D
,T320.Q_001_F_000RRef
,0x05
,@P232
,T320.Q_001_F_001_
,T320.Q_001_F_002_
,T320.Q_001_F_003RRef
,T320.Q_001_F_004RRef
,T320.Q_001_F_005RRef
,0x08
,@P233
,T320.Q_001_F_006RRef
,T320.Q_001_F_007RRef
,T320.Q_001_F_008RRef
,T320.Q_001_F_009_
,T320.Q_001_F_010RRef
,T320.Q_001_F_011_
,T320.Q_001_F_012_
,CAST(T320.Q_001_F_013_ AS NVARCHAR(52))
,T320.Q_001_F_014_TYPE
,T320.Q_001_F_014_S
,T320.Q_001_F_014_RRRef
,T320.Q_001_F_015_
FROM (
SELECT TOP 1000 T321._IDRRef AS Q_001_F_000RRef
,T321._Number AS Q_001_F_001_
,T321._Date_Time AS Q_001_F_002_
,T321._Fld51378RRef AS Q_001_F_003RRef
,T321._Fld51377RRef AS Q_001_F_004RRef
,T321._Fld51382RRef AS Q_001_F_005RRef
,T321._Fld51383RRef AS Q_001_F_006RRef
,T322.Fld50826RRef AS Q_001_F_007RRef
,T322.Fld50828RRef AS Q_001_F_008RRef
,T322.Fld50827_ AS Q_001_F_009_
,T322.Fld50825RRef AS Q_001_F_010RRef
,T321._Fld51381 AS Q_001_F_011_
,CASE
WHEN (NOT (((T322.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P234 AS Q_001_F_013_
,CASE
WHEN T330._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T330._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T330._Q_001_F_001_TYPE IS NULL
THEN @P235
ELSE T330._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T330._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T330._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T321._Date_Time AS Q_001_F_015_
FROM dbo._Document50493X1 T321
LEFT OUTER JOIN (
SELECT T325._Fld50828RRef AS Fld50828RRef
,T325._Fld50826RRef AS Fld50826RRef
,T325._Fld56279RRef AS Fld56279RRef
,T325._Fld50824_TYPE AS Fld50824_TYPE
,T325._Fld50824_RTRef AS Fld50824_RTRef
,T325._Fld50824_RRRef AS Fld50824_RRRef
,T325._Fld50827 AS Fld50827_
,T325._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T324._Fld50824_TYPE AS Fld50824_TYPE
,T324._Fld50824_RTRef AS Fld50824_RTRef
,T324._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T324._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T324
GROUP BY T324._Fld50824_TYPE
,T324._Fld50824_RTRef
,T324._Fld50824_RRRef
) T323
INNER JOIN dbo._InfoRg50823X1 T325 ON T323.Fld50824_TYPE = T325._Fld50824_TYPE
AND T323.Fld50824_RTRef = T325._Fld50824_RTRef
AND T323.Fld50824_RRRef = T325._Fld50824_RRRef
AND T323.MAXPERIOD_ = T325._Period
) T322 ON (
0x08 = T322.Fld50824_TYPE
AND 0x0000C53D = T322.Fld50824_RTRef
AND T321._IDRRef = T322.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T329._Fld50704RRef AS Fld50704RRef
,T329._Fld50703_TYPE AS Fld50703_TYPE
,T329._Fld50703_RTRef AS Fld50703_RTRef
,T329._Fld50703_RRRef AS Fld50703_RRRef
,T329._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T328._Fld50703_TYPE AS Fld50703_TYPE
,T328._Fld50703_RTRef AS Fld50703_RTRef
,T328._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T328._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T328
GROUP BY T328._Fld50703_TYPE
,T328._Fld50703_RTRef
,T328._Fld50703_RRRef
) T327
INNER JOIN dbo._InfoRg50702X1 T329 ON T327.Fld50703_TYPE = T329._Fld50703_TYPE
AND T327.Fld50703_RTRef = T329._Fld50703_RTRef
AND T327.Fld50703_RRRef = T329._Fld50703_RRRef
AND T327.MAXPERIOD_ = T329._Period
) T326 ON (
0x08 = T326.Fld50703_TYPE
AND 0x0000C53D = T326.Fld50703_RTRef
AND T321._IDRRef = T326.Fld50703_RRRef
)
AND (T326.Fld50705RRef = @P236)
LEFT OUTER JOIN #tt59 T330 WITH (NOLOCK) ON (T321._Fld51383RRef
= T330._Q_001_F_000RRef)
AND (
(T321._Date_Time >= T330._Q_001_F_002)
AND (T321._Date_Time <= T330._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T331 ON T322.Fld50828RRef = T331._IDRRef
WHERE T321._Posted = 0x01
AND T322.Fld50828RRef IN (
SELECT T332._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T332 WITH (NOLOCK)
)
AND (
T322.Fld50828RRef IN (
SELECT T333._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T333 WITH (NOLOCK)
)
AND (T322.Fld50826RRef = @P237)
OR T331._ParentIDRRef IN (
SELECT T334._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T334 WITH (NOLOCK)
)
AND (T322.Fld50826RRef = @P238)
OR T322.Fld56279RRef IN (
SELECT T335._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T335 WITH (NOLOCK)
)
AND (T322.Fld50826RRef = @P239)
)
AND (
(T326.Fld50704RRef = @P240)
OR @P241 IN (
SELECT T336._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T336
WHERE (T336._Fld50691RRef = T322.Fld50828RRef)
AND (
T336._Fld50690_TYPE = 0x08
AND T336._Fld50690_RTRef = 0x0000C53D
AND T336._Fld50690_RRRef = T321._IDRRef
)
)
AND (T322.Fld50826RRef = @P242)
OR @P243 IN (
SELECT T337._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T337
WHERE (
(T337._Fld50691RRef = T331._ParentIDRRef)
OR (T337._Fld50691RRef = T322.Fld56279RRef)
)
AND (
T337._Fld50690_TYPE = 0x08
AND T337._Fld50690_RTRef = 0x0000C53D
AND T337._Fld50690_RRRef = T321._IDRRef
)
)
AND (T322.Fld50826RRef = @P244)
)
ORDER BY (T321._Date_Time)
) T320
UNION ALL
SELECT 0x0000CD0E
,T338.Q_001_F_000RRef
,0x05
,@P245
,T338.Q_001_F_001_
,T338.Q_001_F_002_
,T338.Q_001_F_003RRef
,T338.Q_001_F_004RRef
,T338.Q_001_F_005RRef
,0x08
,@P246
,T338.Q_001_F_006RRef
,T338.Q_001_F_007RRef
,T338.Q_001_F_008RRef
,T338.Q_001_F_009_
,T338.Q_001_F_010RRef
,T338.Q_001_F_011_
,T338.Q_001_F_012_
,CAST(T338.Q_001_F_013_ AS NVARCHAR(52))
,T338.Q_001_F_014_TYPE
,T338.Q_001_F_014_S
,T338.Q_001_F_014_RRRef
,T338.Q_001_F_015_
FROM (
SELECT TOP 1000 T339._IDRRef AS Q_001_F_000RRef
,T339._Number AS Q_001_F_001_
,T339._Date_Time AS Q_001_F_002_
,T339._Fld52771RRef AS Q_001_F_003RRef
,T339._Fld52769RRef AS Q_001_F_004RRef
,T339._Fld52776RRef AS Q_001_F_005RRef
,T339._Fld52777RRef AS Q_001_F_006RRef
,T340.Fld50826RRef AS Q_001_F_007RRef
,T340.Fld50828RRef AS Q_001_F_008RRef
,T340.Fld50827_ AS Q_001_F_009_
,T340.Fld50825RRef AS Q_001_F_010RRef
,T339._Fld52774 AS Q_001_F_011_
,CASE
WHEN (NOT (((T340.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P247 AS Q_001_F_013_
,CASE
WHEN T348._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T348._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T348._Q_001_F_001_TYPE IS NULL
THEN @P248
ELSE T348._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T348._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T348._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T339._Date_Time AS Q_001_F_015_
FROM dbo._Document52494X1 T339
LEFT OUTER JOIN (
SELECT T343._Fld50828RRef AS Fld50828RRef
,T343._Fld50826RRef AS Fld50826RRef
,T343._Fld56279RRef AS Fld56279RRef
,T343._Fld50824_TYPE AS Fld50824_TYPE
,T343._Fld50824_RTRef AS Fld50824_RTRef
,T343._Fld50824_RRRef AS Fld50824_RRRef
,T343._Fld50827 AS Fld50827_
,T343._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T342._Fld50824_TYPE AS Fld50824_TYPE
,T342._Fld50824_RTRef AS Fld50824_RTRef
,T342._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T342._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T342
GROUP BY T342._Fld50824_TYPE
,T342._Fld50824_RTRef
,T342._Fld50824_RRRef
) T341
INNER JOIN dbo._InfoRg50823X1 T343 ON T341.Fld50824_TYPE = T343._Fld50824_TYPE
AND T341.Fld50824_RTRef = T343._Fld50824_RTRef
AND T341.Fld50824_RRRef = T343._Fld50824_RRRef
AND T341.MAXPERIOD_ = T343._Period
) T340 ON (
0x08 = T340.Fld50824_TYPE
AND 0x0000CD0E = T340.Fld50824_RTRef
AND T339._IDRRef = T340.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T347._Fld50704RRef AS Fld50704RRef
,T347._Fld50703_TYPE AS Fld50703_TYPE
,T347._Fld50703_RTRef AS Fld50703_RTRef
,T347._Fld50703_RRRef AS Fld50703_RRRef
,T347._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T346._Fld50703_TYPE AS Fld50703_TYPE
,T346._Fld50703_RTRef AS Fld50703_RTRef
,T346._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T346._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T346
GROUP BY T346._Fld50703_TYPE
,T346._Fld50703_RTRef
,T346._Fld50703_RRRef
) T345
INNER JOIN dbo._InfoRg50702X1 T347 ON T345.Fld50703_TYPE = T347._Fld50703_TYPE
AND T345.Fld50703_RTRef = T347._Fld50703_RTRef
AND T345.Fld50703_RRRef = T347._Fld50703_RRRef
AND T345.MAXPERIOD_ = T347._Period
) T344 ON (
0x08 = T344.Fld50703_TYPE
AND 0x0000CD0E = T344.Fld50703_RTRef
AND T339._IDRRef = T344.Fld50703_RRRef
)
AND (T344.Fld50705RRef = @P249)
LEFT OUTER JOIN #tt59 T348 WITH (NOLOCK) ON (T339._Fld52777RRef
= T348._Q_001_F_000RRef)
AND (
(T339._Date_Time >= T348._Q_001_F_002)
AND (T339._Date_Time <= T348._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T349 ON T340.Fld50828RRef = T349._IDRRef
WHERE T339._Posted = 0x01
AND T340.Fld50828RRef IN (
SELECT T350._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T350 WITH (NOLOCK)
)
AND (
T340.Fld50828RRef IN (
SELECT T351._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T351 WITH (NOLOCK)
)
AND (T340.Fld50826RRef = @P250)
OR T349._ParentIDRRef IN (
SELECT T352._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T352 WITH (NOLOCK)
)
AND (T340.Fld50826RRef = @P251)
OR T340.Fld56279RRef IN (
SELECT T353._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T353 WITH (NOLOCK)
)
AND (T340.Fld50826RRef = @P252)
)
AND (
(T344.Fld50704RRef = @P253)
OR @P254 IN (
SELECT T354._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T354
WHERE (T354._Fld50691RRef = T340.Fld50828RRef)
AND (
T354._Fld50690_TYPE = 0x08
AND T354._Fld50690_RTRef = 0x0000CD0E
AND T354._Fld50690_RRRef = T339._IDRRef
)
)
AND (T340.Fld50826RRef = @P255)
OR @P256 IN (
SELECT T355._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T355
WHERE (
(T355._Fld50691RRef = T349._ParentIDRRef)
OR (T355._Fld50691RRef = T340.Fld56279RRef)
)
AND (
T355._Fld50690_TYPE = 0x08
AND T355._Fld50690_RTRef = 0x0000CD0E
AND T355._Fld50690_RRRef = T339._IDRRef
)
)
AND (T340.Fld50826RRef = @P257)
)
ORDER BY (T339._Date_Time)
) T338
UNION ALL
SELECT 0x0000C534
,T356.Q_001_F_000RRef
,0x05
,@P258
,CAST(T356.Q_001_F_001_ AS NVARCHAR(11))
,T356.Q_001_F_002_
,T356.Q_001_F_003RRef
,T356.Q_001_F_004RRef
,T356.Q_001_F_005RRef
,0x08
,@P259
,T356.Q_001_F_006RRef
,T356.Q_001_F_007RRef
,T356.Q_001_F_008RRef
,T356.Q_001_F_009_
,T356.Q_001_F_010RRef
,T356.Q_001_F_011_
,T356.Q_001_F_012_
,CAST(T356.Q_001_F_013_ AS NVARCHAR(52))
,T356.Q_001_F_014_TYPE
,T356.Q_001_F_014_S
,T356.Q_001_F_014_RRRef
,T356.Q_001_F_015_
FROM (
SELECT TOP 1000 T357._IDRRef AS Q_001_F_000RRef
,T357._Number AS Q_001_F_001_
,T357._Date_Time AS Q_001_F_002_
,T357._Fld54051RRef AS Q_001_F_003RRef
,T357._Fld51067RRef AS Q_001_F_004RRef
,T357._Fld54095RRef AS Q_001_F_005RRef
,T357._Fld51068RRef AS Q_001_F_006RRef
,T358.Fld50826RRef AS Q_001_F_007RRef
,T358.Fld50828RRef AS Q_001_F_008RRef
,T358.Fld50827_ AS Q_001_F_009_
,T358.Fld50825RRef AS Q_001_F_010RRef
,T357._Fld51075 AS Q_001_F_011_
,CASE
WHEN (NOT (((T358.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P260 AS Q_001_F_013_
,CASE
WHEN T366._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T366._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T366._Q_001_F_001_TYPE IS NULL
THEN @P261
ELSE T366._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T366._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T366._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T357._Date_Time AS Q_001_F_015_
FROM dbo._Document50484X1 T357
LEFT OUTER JOIN (
SELECT T361._Fld50828RRef AS Fld50828RRef
,T361._Fld50826RRef AS Fld50826RRef
,T361._Fld56279RRef AS Fld56279RRef
,T361._Fld50824_TYPE AS Fld50824_TYPE
,T361._Fld50824_RTRef AS Fld50824_RTRef
,T361._Fld50824_RRRef AS Fld50824_RRRef
,T361._Fld50827 AS Fld50827_
,T361._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T360._Fld50824_TYPE AS Fld50824_TYPE
,T360._Fld50824_RTRef AS Fld50824_RTRef
,T360._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T360._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T360
GROUP BY T360._Fld50824_TYPE
,T360._Fld50824_RTRef
,T360._Fld50824_RRRef
) T359
INNER JOIN dbo._InfoRg50823X1 T361 ON T359.Fld50824_TYPE = T361._Fld50824_TYPE
AND T359.Fld50824_RTRef = T361._Fld50824_RTRef
AND T359.Fld50824_RRRef = T361._Fld50824_RRRef
AND T359.MAXPERIOD_ = T361._Period
) T358 ON (
0x08 = T358.Fld50824_TYPE
AND 0x0000C534 = T358.Fld50824_RTRef
AND T357._IDRRef = T358.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T365._Fld50704RRef AS Fld50704RRef
,T365._Fld50703_TYPE AS Fld50703_TYPE
,T365._Fld50703_RTRef AS Fld50703_RTRef
,T365._Fld50703_RRRef AS Fld50703_RRRef
,T365._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T364._Fld50703_TYPE AS Fld50703_TYPE
,T364._Fld50703_RTRef AS Fld50703_RTRef
,T364._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T364._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T364
GROUP BY T364._Fld50703_TYPE
,T364._Fld50703_RTRef
,T364._Fld50703_RRRef
) T363
INNER JOIN dbo._InfoRg50702X1 T365 ON T363.Fld50703_TYPE = T365._Fld50703_TYPE
AND T363.Fld50703_RTRef = T365._Fld50703_RTRef
AND T363.Fld50703_RRRef = T365._Fld50703_RRRef
AND T363.MAXPERIOD_ = T365._Period
) T362 ON (
0x08 = T362.Fld50703_TYPE
AND 0x0000C534 = T362.Fld50703_RTRef
AND T357._IDRRef = T362.Fld50703_RRRef
)
AND (T362.Fld50705RRef = @P262)
LEFT OUTER JOIN #tt59 T366 WITH (NOLOCK) ON (T357._Fld51068RRef
= T366._Q_001_F_000RRef)
AND (
(T357._Date_Time >= T366._Q_001_F_002)
AND (T357._Date_Time <= T366._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T367 ON T358.Fld50828RRef = T367._IDRRef
WHERE T357._Posted = 0x01
AND T358.Fld50828RRef IN (
SELECT T368._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T368 WITH (NOLOCK)
)
AND (
T358.Fld50828RRef IN (
SELECT T369._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T369 WITH (NOLOCK)
)
AND (T358.Fld50826RRef = @P263)
OR T367._ParentIDRRef IN (
SELECT T370._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T370 WITH (NOLOCK)
)
AND (T358.Fld50826RRef = @P264)
OR T358.Fld56279RRef IN (
SELECT T371._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T371 WITH (NOLOCK)
)
AND (T358.Fld50826RRef = @P265)
)
AND (
(T362.Fld50704RRef = @P266)
OR @P267 IN (
SELECT T372._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T372
WHERE (T372._Fld50691RRef = T358.Fld50828RRef)
AND (
T372._Fld50690_TYPE = 0x08
AND T372._Fld50690_RTRef = 0x0000C534
AND T372._Fld50690_RRRef = T357._IDRRef
)
)
AND (T358.Fld50826RRef = @P268)
OR @P269 IN (
SELECT T373._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T373
WHERE (
(T373._Fld50691RRef = T367._ParentIDRRef)
OR (T373._Fld50691RRef = T358.Fld56279RRef)
)
AND (
T373._Fld50690_TYPE = 0x08
AND T373._Fld50690_RTRef = 0x0000C534
AND T373._Fld50690_RRRef = T357._IDRRef
)
)
AND (T358.Fld50826RRef = @P270)
)
ORDER BY (T357._Date_Time)
) T356
UNION ALL
SELECT 0x0000D036
,T374.Q_001_F_000RRef
,0x05
,@P271
,T374.Q_001_F_001_
,T374.Q_001_F_002_
,T374.Q_001_F_003RRef
,T374.Q_001_F_004RRef
,T374.Q_001_F_005RRef
,0x08
,@P272
,T374.Q_001_F_006RRef
,T374.Q_001_F_007RRef
,T374.Q_001_F_008RRef
,T374.Q_001_F_009_
,T374.Q_001_F_010RRef
,T374.Q_001_F_011_
,T374.Q_001_F_012_
,CAST(T374.Q_001_F_013_ AS NVARCHAR(52))
,T374.Q_001_F_014_TYPE
,T374.Q_001_F_014_S
,T374.Q_001_F_014_RRRef
,T374.Q_001_F_015_
FROM (
SELECT TOP 1000 T375._IDRRef AS Q_001_F_000RRef
,T375._Number AS Q_001_F_001_
,T375._Date_Time AS Q_001_F_002_
,T375._Fld53315RRef AS Q_001_F_003RRef
,T375._Fld53314RRef AS Q_001_F_004RRef
,T375._Fld53320RRef AS Q_001_F_005RRef
,T375._Fld53323RRef AS Q_001_F_006RRef
,T376.Fld50826RRef AS Q_001_F_007RRef
,T376.Fld50828RRef AS Q_001_F_008RRef
,T376.Fld50827_ AS Q_001_F_009_
,T376.Fld50825RRef AS Q_001_F_010RRef
,T375._Fld53319 AS Q_001_F_011_
,CASE
WHEN (NOT (((T376.Fld50826RRef IS NULL))))
THEN 0x01
ELSE 0x00
END AS Q_001_F_012_
,@P273 AS Q_001_F_013_
,CASE
WHEN T384._Q_001_F_001_TYPE IS NULL
THEN 0x05
ELSE T384._Q_001_F_001_TYPE
END AS Q_001_F_014_TYPE
,CASE
WHEN T384._Q_001_F_001_TYPE IS NULL
THEN @P274
ELSE T384._Q_001_F_001_S
END AS Q_001_F_014_S
,CASE
WHEN T384._Q_001_F_001_TYPE IS NULL
THEN 0x00000000000000000000000000000000
ELSE T384._Q_001_F_001_RRRef
END AS Q_001_F_014_RRRef
,T375._Date_Time AS Q_001_F_015_
FROM dbo._Document53302X1 T375
LEFT OUTER JOIN (
SELECT T379._Fld50828RRef AS Fld50828RRef
,T379._Fld50826RRef AS Fld50826RRef
,T379._Fld56279RRef AS Fld56279RRef
,T379._Fld50824_TYPE AS Fld50824_TYPE
,T379._Fld50824_RTRef AS Fld50824_RTRef
,T379._Fld50824_RRRef AS Fld50824_RRRef
,T379._Fld50827 AS Fld50827_
,T379._Fld50825RRef AS Fld50825RRef
FROM (
SELECT T378._Fld50824_TYPE AS Fld50824_TYPE
,T378._Fld50824_RTRef AS Fld50824_RTRef
,T378._Fld50824_RRRef AS Fld50824_RRRef
,MAX(T378._Period) AS MAXPERIOD_
FROM dbo._InfoRg50823X1 T378
GROUP BY T378._Fld50824_TYPE
,T378._Fld50824_RTRef
,T378._Fld50824_RRRef
) T377
INNER JOIN dbo._InfoRg50823X1 T379 ON T377.Fld50824_TYPE = T379._Fld50824_TYPE
AND T377.Fld50824_RTRef = T379._Fld50824_RTRef
AND T377.Fld50824_RRRef = T379._Fld50824_RRRef
AND T377.MAXPERIOD_ = T379._Period
) T376 ON (
0x08 = T376.Fld50824_TYPE
AND 0x0000D036 = T376.Fld50824_RTRef
AND T375._IDRRef = T376.Fld50824_RRRef
)
LEFT OUTER JOIN (
SELECT T383._Fld50704RRef AS Fld50704RRef
,T383._Fld50703_TYPE AS Fld50703_TYPE
,T383._Fld50703_RTRef AS Fld50703_RTRef
,T383._Fld50703_RRRef AS Fld50703_RRRef
,T383._Fld50705RRef AS Fld50705RRef
FROM (
SELECT T382._Fld50703_TYPE AS Fld50703_TYPE
,T382._Fld50703_RTRef AS Fld50703_RTRef
,T382._Fld50703_RRRef AS Fld50703_RRRef
,MAX(T382._Period) AS MAXPERIOD_
FROM dbo._InfoRg50702X1 T382
GROUP BY T382._Fld50703_TYPE
,T382._Fld50703_RTRef
,T382._Fld50703_RRRef
) T381
INNER JOIN dbo._InfoRg50702X1 T383 ON T381.Fld50703_TYPE = T383._Fld50703_TYPE
AND T381.Fld50703_RTRef = T383._Fld50703_RTRef
AND T381.Fld50703_RRRef = T383._Fld50703_RRRef
AND T381.MAXPERIOD_ = T383._Period
) T380 ON (
0x08 = T380.Fld50703_TYPE
AND 0x0000D036 = T380.Fld50703_RTRef
AND T375._IDRRef = T380.Fld50703_RRRef
)
AND (T380.Fld50705RRef = @P275)
LEFT OUTER JOIN #tt59 T384 WITH (NOLOCK) ON (T375._Fld53323RRef
= T384._Q_001_F_000RRef)
AND (
(T375._Date_Time >= T384._Q_001_F_002)
AND (T375._Date_Time <= T384._Q_001_F_003)
)
LEFT OUTER JOIN dbo._Reference50477X1 T385 ON T376.Fld50828RRef = T385._IDRRef
WHERE T375._Posted = 0x01
AND T376.Fld50828RRef IN (
SELECT T386._Q_001_F_000RRef AS Q_002_F_000RRef
FROM #tt114 T386 WITH (NOLOCK)
)
AND (
T376.Fld50828RRef IN (
SELECT T387._Q_001_F_000RRef AS Q_003_F_000RRef
FROM #tt338 T387 WITH (NOLOCK)
)
AND (T376.Fld50826RRef = @P276)
OR T385._ParentIDRRef IN (
SELECT T388._Q_001_F_000RRef AS Q_004_F_000RRef
FROM #tt338 T388 WITH (NOLOCK)
)
AND (T376.Fld50826RRef = @P277)
OR T376.Fld56279RRef IN (
SELECT T389._Q_001_F_000RRef AS Q_005_F_000RRef
FROM #tt338 T389 WITH (NOLOCK)
)
AND (T376.Fld50826RRef = @P278)
)
AND (
(T380.Fld50704RRef = @P279)
OR @P280 IN (
SELECT T390._Fld50692RRef AS Q_006_F_000RRef
FROM dbo._InfoRg50689X1 T390
WHERE (T390._Fld50691RRef = T376.Fld50828RRef)
AND (
T390._Fld50690_TYPE = 0x08
AND T390._Fld50690_RTRef = 0x0000D036
AND T390._Fld50690_RRRef = T375._IDRRef
)
)
AND (T376.Fld50826RRef = @P281)
OR @P282 IN (
SELECT T391._Fld50692RRef AS Q_007_F_000RRef
FROM dbo._InfoRg50689X1 T391
WHERE (
(T391._Fld50691RRef = T385._ParentIDRRef)
OR (T391._Fld50691RRef = T376.Fld56279RRef)
)
AND (
T391._Fld50690_TYPE = 0x08
AND T391._Fld50690_RTRef = 0x0000D036
AND T391._Fld50690_RRRef = T375._IDRRef
)
)
AND (T376.Fld50826RRef = @P283)
)
ORDER BY (T375._Date_Time)
) T374
ORDER BY 23
'
,
N'@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 nvarchar(4000),@P4 numeric(10),
@P5 datetime2(3),@P6 nvarchar(4000),@P7 numeric(10),@P8 nvarchar(4000),
@P9 nvarchar(4000),@P10 nvarchar(4000),@P11 varbinary(16),@P12 varbinary(16),
@P13 varbinary(16),@P14 varbinary(16),@P15 varbinary(16),@P16 varbinary(16),
@P17 varbinary(16),@P18 varbinary(16),@P19 varbinary(16),@P20 numeric(10),
@P21 nvarchar(4000),@P22 nvarchar(4000),@P23 nvarchar(4000),@P24 varbinary(16),
@P25 varbinary(16),@P26 varbinary(16),@P27 varbinary(16),@P28 varbinary(16),
@P29 varbinary(16),@P30 varbinary(16),@P31 varbinary(16),@P32 varbinary(16),
@P33 numeric(10),@P34 nvarchar(4000),@P35 nvarchar(4000),@P36 nvarchar(4000),
@P37 varbinary(16),@P38 varbinary(16),@P39 varbinary(16),@P40 varbinary(16),
@P41 varbinary(16),@P42 varbinary(16),@P43 varbinary(16),@P44 varbinary(16),
@P45 numeric(10),@P46 nvarchar(4000),@P47 nvarchar(4000),@P48 nvarchar(4000),
@P49 varbinary(16),@P50 varbinary(16),@P51 varbinary(16),@P52 varbinary(16),
@P53 varbinary(16),@P54 varbinary(16),@P55 varbinary(16),@P56 varbinary(16),
@P57 varbinary(16),@P58 numeric(10),@P59 nvarchar(4000),@P60 nvarchar(4000),
@P61 varbinary(16),@P62 varbinary(16),@P63 varbinary(16),@P64 varbinary(16),
@P65 varbinary(16),@P66 varbinary(16),@P67 varbinary(16),@P68 varbinary(16),
@P69 varbinary(16),@P70 numeric(10),@P71 nvarchar(4000),@P72 nvarchar(4000),
@P73 varbinary(16),@P74 varbinary(16),@P75 varbinary(16),@P76 varbinary(16),
@P77 varbinary(16),@P78 varbinary(16),@P79 varbinary(16),@P80 varbinary(16),
@P81 varbinary(16),@P82 numeric(10),@P83 nvarchar(4000),@P84 nvarchar(4000),
@P85 varbinary(16),@P86 varbinary(16),@P87 varbinary(16),@P88 varbinary(16),
@P89 varbinary(16),@P90 varbinary(16),@P91 varbinary(16),@P92 varbinary(16),
@P93 varbinary(16),@P94 numeric(10),@P95 nvarchar(4000),@P96 nvarchar(4000),
@P97 nvarchar(4000),@P98 varbinary(16),@P99 varbinary(16),@P100 varbinary(16),
@P101 varbinary(16),@P102 varbinary(16),@P103 varbinary(16),@P104 varbinary(16),
@P105 varbinary(16),@P106 varbinary(16),@P107 numeric(10),@P108 nvarchar(4000),
@P109 nvarchar(4000),@P110 nvarchar(4000),@P111 varbinary(16),
@P112 varbinary(16),@P113 varbinary(16),@P114 varbinary(16),@P115 varbinary(16),
@P116 varbinary(16),@P117 varbinary(16),@P118 varbinary(16),@P119 varbinary(16),
@P120 numeric(10),@P121 nvarchar(4000),@P122 nvarchar(4000),@P123 varbinary(16),
@P124 varbinary(16),@P125 varbinary(16),@P126 varbinary(16),@P127 varbinary(16),
@P128 varbinary(16),@P129 varbinary(16),@P130 varbinary(16),@P131 varbinary(16),
@P132 numeric(10),@P133 nvarchar(4000),@P134 nvarchar(4000),@P135 nvarchar(4000),
@P136 varbinary(16),@P137 varbinary(16),@P138 varbinary(16),@P139 varbinary(16),
@P140 varbinary(16),@P141 varbinary(16),@P142 varbinary(16),@P143 varbinary(16),
@P144 varbinary(16),@P145 numeric(10),@P146 nvarchar(4000),@P147 nvarchar(4000),
@P148 nvarchar(4000),@P149 varbinary(16),@P150 varbinary(16),
@P151 varbinary(16),@P152 varbinary(16),@P153 varbinary(16),@P154 varbinary(16),
@P155 varbinary(16),@P156 varbinary(16),@P157 varbinary(16),@P158 numeric(10),
@P159 nvarchar(4000),@P160 nvarchar(4000),@P161 nvarchar(4000),
@P162 varbinary(16),@P163 varbinary(16),@P164 varbinary(16),@P165 varbinary(16),
@P166 varbinary(16),@P167 varbinary(16),@P168 varbinary(16),@P169 varbinary(16),
@P170 varbinary(16),@P171 numeric(10),@P172 nvarchar(4000),@P173 nvarchar(4000),
@P174 varbinary(16),@P175 varbinary(16),@P176 varbinary(16),@P177 varbinary(16),
@P178 varbinary(16),@P179 varbinary(16),@P180 varbinary(16),@P181 varbinary(16),
@P182 varbinary(16),@P183 numeric(10),@P184 nvarchar(4000),@P185 nvarchar(4000),
@P186 nvarchar(4000),@P187 varbinary(16),@P188 varbinary(16),
@P189 varbinary(16),@P190 varbinary(16),@P191 varbinary(16),@P192 varbinary(16),
@P193 varbinary(16),@P194 varbinary(16),@P195 varbinary(16),@P196 numeric(10),
@P197 nvarchar(4000),@P198 nvarchar(4000),@P199 varbinary(16),
@P200 varbinary(16),@P201 varbinary(16),@P202 varbinary(16),@P203 varbinary(16),
@P204 varbinary(16),@P205 varbinary(16),@P206 varbinary(16),@P207 varbinary(16),
@P208 numeric(10),@P209 nvarchar(4000),@P210 nvarchar(4000),@P211 varbinary(16),
@P212 varbinary(16),@P213 varbinary(16),@P214 varbinary(16),@P215 varbinary(16),
@P216 varbinary(16),@P217 varbinary(16),@P218 varbinary(16),@P219 varbinary(16),
@P220 numeric(10),@P221 nvarchar(4000),@P222 nvarchar(4000),@P223 varbinary(16),
@P224 varbinary(16),@P225 varbinary(16),@P226 varbinary(16),@P227 varbinary(16),
@P228 varbinary(16),@P229 varbinary(16),@P230 varbinary(16),@P231 varbinary(16),
@P232 numeric(10),@P233 nvarchar(4000),@P234 nvarchar(4000),@P235 nvarchar(4000),
@P236 varbinary(16),@P237 varbinary(16),@P238 varbinary(16),@P239 varbinary(16),
@P240 varbinary(16),@P241 varbinary(16),@P242 varbinary(16),@P243 varbinary(16),
@P244 varbinary(16),@P245 numeric(10),@P246 nvarchar(4000),@P247 nvarchar(4000),
@P248 nvarchar(4000),@P249 varbinary(16),@P250 varbinary(16),
@P251 varbinary(16),@P252 varbinary(16),@P253 varbinary(16),@P254 varbinary(16),
@P255 varbinary(16),@P256 varbinary(16),@P257 varbinary(16),@P258 numeric(10),
@P259 nvarchar(4000),@P260 nvarchar(4000),@P261 nvarchar(4000),
@P262 varbinary(16),@P263 varbinary(16),@P264 varbinary(16),@P265 varbinary(16),
@P266 varbinary(16),@P267 varbinary(16),@P268 varbinary(16),@P269 varbinary(16),
@P270 varbinary(16),@P271 numeric(10),@P272 nvarchar(4000),@P273 nvarchar(4000),
@P274 nvarchar(4000),@P275 varbinary(16),@P276 varbinary(16),
@P277 varbinary(16),@P278 varbinary(16),@P279 varbinary(16),@P280 varbinary(16),
@P281 varbinary(16),@P282 varbinary(16),@P283 varbinary(16)'
,N''
,N''
,N''
,0
,'2001-01-01 00:00:00'
,N''
,0
,N''
,N'Inspire'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'SAP Форма'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Termination check-list'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'График отпусков сотрудника'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N'Заявка на доплату за дополнительную работу'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на закрытие позиции'
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на изменение вакантной позиции'
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на изменение графика работы'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на изменение персональных данных'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N'Заявка на кадровый перевод'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на отгул'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на отпуск/компенсацию отпуска'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на отсутствие'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на подбор/прием'
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на предоставление компенсаций и льгот'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на работу в праздники и выходные'
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на создание позиции с созданием должности'
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на создание позиции с существующей должностью'
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на справку, копию трудовой книжки'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Заявка на увольнение'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Перенос планового отпуска'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6
,0
,N''
,N'Справка о сдаче крови и ее компонентов'
,N''
,0xB1546BE70A42DD5243368450AD207924
,0x9053A321153550C24F0AF927FAEC307C
,0xAD59FF13374430134AABA1871F93E5E6
,0xAD59FF13374430134AABA1871F93E5E6
,0xB4D400505601147811EC8E24AE89F11C
,0xB4D400505601147811EC8E24AE89F11C
,0x9053A321153550C24F0AF927FAEC307C
,0xB4D400505601147811EC8E24AE89F11C
,0xAD59FF13374430134AABA1871F93E5E6Из трассы видно, что его длительность прыгала от 0,6 сек. до почти 2 мин. Причем в половине случаев запрос выполнялся условно быстро за 1-2 сек., а в остальных случаях дольше минуты.
Обратите внимание на другие колонки трассы по отобранным 19-ти запросам — количество логических чтений и количество планов запросов.

Мониторинг Perfexpert помимо текста запросов собирает и планы запросов. Суммарное количество планов запросов, которые использовал SQL Server для нашего запроса в разные дни равняется семи (на самом деле их может быть больше, т.к. не все планы запросов попадают в Perfexpert). И только с помощью одного плана запрос выполнялся с ~80 тыс. логических чтений. С остальными же планами запрос вынужден был делать миллионные чтения, что сразу увеличивало его длительность на порядки:

С физикой процесса разобрались. Идем дальше, чтобы понять как с этим бороться.
Что делать
Альтернатив не много.
1. Использовать «Производительный режим работы RLS»
В отличии от стандартного режима, где ограничения прописываются на языке запросов 1С в ролях и добавляются к основному запросу в виде левых соединений, здесь все отборы и ограничения добавляются не в запрос, а в так называемые ключи доступа. И в итоговом запросе указываются именно ключи доступа. Ключи доступа – это один справочник «КлючиДоступа» и два регистра сведений: «КлючиДоступаКОбъектам» и «КлючиДоступаПользователей».
Предрассчитанные ключи доступа, с одной стороны, должны давать хороший прирост по скорости выполнения запроса, но, с другой, требуют правильного обслуживания и обновления данных в регистрах. Очень часто при входе пользователей в систему запускается обработка проверки актуальности ключей аналитики, которая удаляет неактуальные ключи и обновляет существующие – это серьезная нагрузка на всю систему и дополнительные ожидания пользователей.
Релевантной статистики по данному методу у нас пока нет, поэтому ни хвалить, ни ругать его я не могу. Но точно есть подводные камни, надо уметь их видеть и обходить.
2. Отказаться от RLS
Это самое, казалось бы, простое решение. Но совсем отказаться от RLS нельзя, т.к. некоторые виды бизнеса просто не могут себе этого позволить: есть чувствительные данные, да и конфиденциальность никто не отменял. А значит нужно прописывать ограничения вручную на уровне запросов в коде 1С. Что будет трудозатратно, не факт, что будет работать быстрее, да еще повлечет за собой вагон функциональных ошибок.
3. Оптимизация РЛС (упрощение)
Этот вариант выглядит более реалистичным. Подходит тоже далеко не всем. Если вы когда-нибудь видели список ролей в крупной ИТ-системе (1000+, из которых больше половины использует RLS), то понимаете, что провести их аудит задача крайне непростая, претендующая на отдельный проект.
4. Помочь оптимизатору запросов выбрать правильный план.
Этот вариант, на первый взгляд, может показаться нереальным, но нет, решение есть.
Использование QProcessing для ускорения RLS в 1С-системах
Как мы помним, в тексте 1С-запросов нельзя вставлять подсказки (хинты) для sql-запросов. А бывает, что очень нужно. Поэтому этот момент обходится при помощи нашего решения Softpoint QProcessing, представляющего из себя программный прокси-сервер, устанавливается между сервером приложений 1С и сервером баз данных MS SQL Server. Позволяет, не изменяя код приложения 1С, задавать и применять правила модификации определенных sql-запросов.
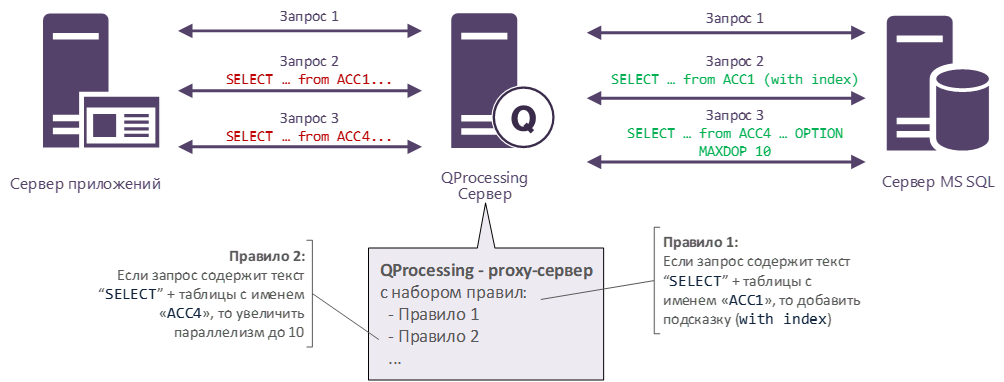
В ходе нескольких аудитов производительности, которые мы проводили нашим заказчикам, мы заметили, что при моделировании тяжелых запросов оптимизатору запросов можно «подсказать» нужный план. В правильном плане оптимизатор будет использовать правильные методы соединения физических таблиц.
Ниже представлен рисунок, демонстрирующий сравнение неэффективного плана с 4 млн. логических чтений и длительностью около 1 минуты, и оптимального плана, при котором запрос выполняется за 8 секунд, выполнив лишь 64 тыс. логических чтений.

Видно, что плохой план использует в качестве метода левого соединения вложенные циклы (Nested Loops) и это не очень здорово. Если в тексте запроса заменить все условия «LEFT OUTER JOIN» на «LEFT OUTER HASH JOIN», явно указав оптимизатору SQL использовать хэширование в качестве типа соединения, то запрос выполняет на два порядка меньше логических чтений и на порядок сокращается его длительность. Это очень хороший результат. И такой эффект наблюдается почти для всех запросов с RLS.
Немного цифр для понимания эффекта ДО и ПОСЛЕ применения QProcessing.
Для анализа в продуктивной базе взял два периода длительностью одна календарная неделя каждый со схожим профилем нагрузки (количество пакетов в секунду, транзакций, пользователей, sql-сессий). Первая неделя – без использования QProcessing, вторая — с QProcessing.
1) Пример 1. Только один вид запросов
По хешу запросов отобрал один с RLS, у которого длительность значительно скачет на первой неделе и сравнил статистику по нему на двух неделях.
| Кол-во запросов | Среднее кол-во лог. чтений | Сумм. кол-во лог. чтений | Средняя длит-ть | Сумм. длит-ть | Максим. длит-ть | |
| Неделя ДО | 53 | 2 867 882 | 151 997 789 | 53,22сек | 47м 0сек | 2м 45сек |
| Неделя ПОСЛЕ | 54 | 117 654 | 6 353 353 | 0,99сек | 53,66сек | 1,84сек |
Эффект очевиден.
2) Пример 2. Статистика по всем запросам из трассы DURATION
Поскольку один запрос – не очень показательный пример, то взял всю трассу Duration (запросы с длительностью > 5 сек.) за первую и вторую неделю.
На рисунках ниже представлен скриншот трассы DURATION по каждой неделе. Запросы сгруппированы по видам, для каждого вида показано количество запросов, средние и максимальные длительности выполнения. На диаграмме показаны количественные метрики из трассы, разбитые по трём группам длительностей выполнения запросов: «< 10 сек.», «10 .. 60 сек.» и «> 60 cек.».
")
")
За вторую неделю с включенными правилами QProcessing в системе зарегистрировано тяжелых sql-запросов длительностью более пяти секунд всего 250 шт. То есть, их количество сократилось с 907 до 250 – в 3,5 раза. Причем запросов длительностью более 1 мин. в трассе не осталось вообще, а запросов длительностью более 10 секунд стало в разы меньше и осталось 122 против 455. Еще раз акцентирую внимание, что профиль нагрузки на обеих неделях идентичный. Соответственно, эти цифры не говорят, что запросов в системе стало меньше. Это значит, что стало меньше запросов длительностью более 5 секунд, а остальные просто мониторинг Perfexpert не собирает в трассу.
Итого
Поддержка RLS в 1С-системах не самый простой процесс, но зато отнимающий очень много сил у поддержки и нервов у пользователей. В статье я показал, что есть достаточно простой способ ускорить запросы с RLS с уже настроенными ограничениями, который:
- Не требует переписывания кода 1С и переписывания ограничений в шаблонах.
- Исключает наличие функциональных ошибок, которые обязательно будут, если проводить действия из п.1
- Не требует ресурсов со стороны разработчиков и поддержки.
Надеюсь, статья с очередным практическим(!) кейсом использования программы QProcessing вам понравилась.
Для подготовки материала я использовал, как обычно, данные, собранные системой мониторинга Perfexpert. Почитать про его возможности можно на нашем сайте https://perfexpert.ru. А практические кейсы с ним и QProcessing мы описываем почти во всех наших статьях: https://habr.com/ru/companies/softpoint/articles/.
Ну а кто решился и готов попробовать QProcessing (бесплатно!) и оценить эффект, милости просим сюда:
https://qp-rls.softpoint.ru.
Ссылки на остальные части Записок оптимизатора1С:
2. Записки оптимизатора 1С (часть 2). Полнотекстовый индекс или как быстро искать по подстроке.
3. Записки оптимизатора 1С (часть 3). Распределенные взаимоблокировки в 1С системах.
4. Записки оптимизатора 1С (часть 4). Параллелизм в 1С, настройки, ожидания CXPACKET.