Записки оптимизатора 1C (часть 8). Нагрузка на диски сервера БД при работе с 1С. Пора ли делать апгрейд?
Поговорим про падения производительности ИТ-систем, которые на первый взгляд связаны с дисковой подсистемой. Но это только «на первый взгляд». Технические специалисты часто видят нагрузку на диски, очереди к ним и сразу появляется жгучее желание модернизировать дисковое хранилище.

Бесспорно, новый диск/хранилище будет работать лучше старого по многим параметрам, но важно другое — увидит ли система и пользователи эффект от этого апгрейда? Ускорятся операции или пропадут замедления диска?
Давайте разбираться. Для это рассмотрим несколько показательных примеров из нашего опыта, ход расследования и докопаемся до первопричины просадки производительности.
Для тех, кто недавно или в первый раз читает наши статьи — все измерения, статистика, трассы запросов сделаны с помощью программы мониторинга производительности PERFEXPERT.
Ситуация 1. Плохая эффективность работы кэша данных СУБД
Это, сразу скажу, самая частая и основная причина замедлений работы диска на СУБД MS SQL Server.
Одна из важных компонент SQL Server — механизм кэширования считанных данных в оперативной памяти. Все страницы, считанные из дисковой подсистемы, помещаются в область памяти, называемую buffer pool. При повторном обращении к таким данным они будут считаны из оперативной памяти, а скорость считывания будет на несколько порядков выше, чем при первом чтении. Таким образом, эффективная работа такого кэша помогает в несколько раз ускорять выполнение наиболее популярных запросов. В случае нехватки места в кэше для очередной порции данных СУБД освобождает необходимое место за счёт ранее считанных страниц. По сути, новые данные «вымывают» данные из кэша. Отследить такие инциденты можно по графику показателя «ожидаемый срок жизни страниц в памяти» — при каждом таком вытеснении график будет резко обрываться вниз.
То есть, если в ходе выполнения запроса СУБД необходимо считать данные, но в оперативном кэше (buffer pool) их нет, то она вынуждена обращаться к заведомо более медленной (в сравнении со скоростью оперативной памяти) дисковой подсистеме. И если объем данных значительный, то диск не успевает их отдавать и образуются очереди к нему. На рисунке ниже изображены два графика: Ожидаемый срок жизни страницы — PLE (зеленый) и Средняя длина очереди к диску (синий). На выделенном желтым фрагменте видно, как падение PLE сопровождается очередями к диску.

Приблизим желтый участок поближе:

Судя по графику очередей к диску, его активное использование началось примерно в 12:56 — 12:57. Если построить трассу READS с тяжелыми запросами, выполняющими более 50 000 логических чтений (см. рисунок ниже) и с сортировкой по логическим чтениям, то видно, что первый в списке запрос SPID 194 начался как раз в 12:57, длился 35 мин. 53 сек и выполнял более 9 млн. физических чтений, т. е. чтений с диска. А нужно ему было для выполнения 128 409 812 логических чтений. Поскольку одно чтение вычитывает страницу памяти размером 8 кБ, то получается, что запрос пытался прочитать 979 Гб данных. И вполне предсказуемо, что всех нужных данных в buffer pool не было, и СУБД считывала часть, и весьма весомую, с диска.

Еще раз повторюсь. Ситуация очень частая. И она имеет два решения:
- Оптимизация таких тяжелых запросов, считывающих, скорее всего, избыточный массив данных. Иногда — это элементарная нехватка подходящих индексов, а иногда неудачный код приложения, который вызвал такой запрос.
- Другое решение ‑добавить оперативной памяти. Особенно будет актуально, когда график PLE «лежит» в нуле и почти не растет в течение рабочего дня. То есть памяти SQL Server»у катастрофически не хватает. И тут оптимизируй, не оптимизируй запросы — результат не изменится.
Первое решение наиболее эффективное. А второе — самое простое и быстрое, но не такое эффективное как первое. Естественно, одно решение не отменяет другое и нужно рассматривать проведение оптимизации производительности со всех сторон.
Ситуация 2. Свопирование
История с файлом подкачки на сервере СУБД чаще всего возникает тогда, когда на одной машине работает и сервер SQL, и какое‑то другое приложение, например, сервер приложений 1С. Или же когда максимальный объем памяти, который выделяется серверу SQL не ограничивают в настройках — параметр max server memory. По умолчанию он равен 2 147 483 647 Мб. Но это довольно редкие случаи. В последнее время уже не встречаем.
Поэтому рассмотрим ситуацию одновременной работы на одной машине служб и SQL Server и 1С сервера. Если серверу SQL почти всегда ограничивают потребление памяти параметром max server memory, то с 1С как раз все в точности наоборот. Хоть там предусмотрена подобная настройка, администраторы ею часто манкируют — параметр «Критический объем памяти процессов» остается в значении по умолчанию — «0». В этом случае рабочий сервер 1С имеет возможность «съесть» до 95% объема оперативной памяти.

Учитывая тот факт, что оба сервера расположены на одной машине, а 95% считается от общего объема, то 1С сервер может попытаться взять себе больше оставшейся ему от SQL сервера памяти. SQL Server, со своей стороны, может даже поделиться своей памятью, если не использует ее в текущий момент. А может случиться так, что начнется процесс свопирования.
Рассмотрим пример. Он очень показателен, поэтому разберем его подробно.
Всего памяти на машине: 256 Гб. На ней работает две службы MS SQL Server и сервер 1С. Из них серверу SQL отведено 128 Гб. И логично предположить, что серверу 1С остались другие 128 Гб. Но нет, поскольку, как и на рисунке выше, параметр «Критический объем памяти процессов» был выставлен в ноль. Проанализируем инцидент, который привел к свопированию и значительному снижению производительности.
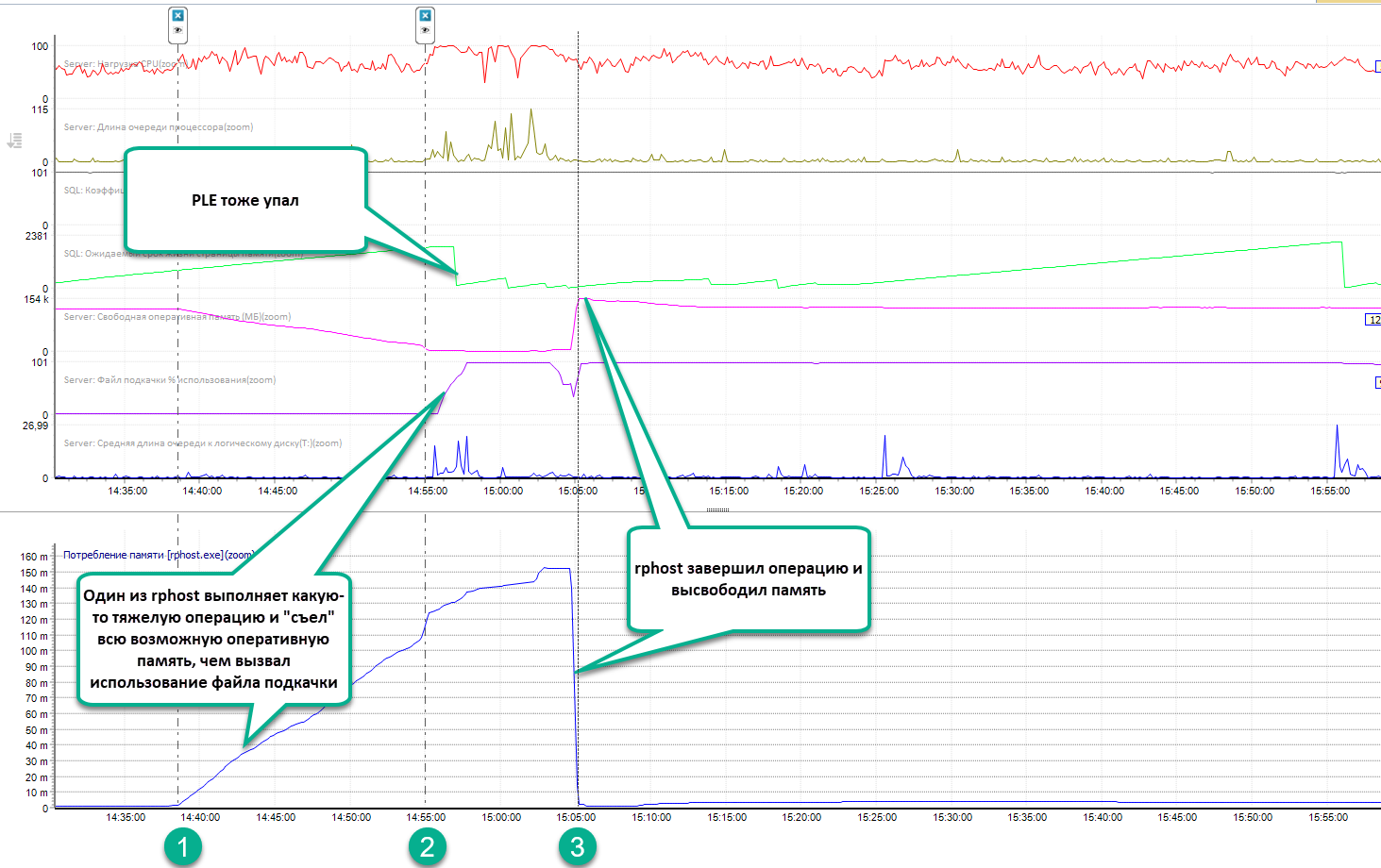
На рисунке ниже обратите внимание на график свободной оперативной памяти (розовый). В момент времени t1 начался его спад, в момент времени t2 он достиг нуля и начался процесс свопиропания –рост процента использования файла подкачки (третий, фиолетовый график), который сопровождался очередями к диску. То есть оперативной памяти не хватило, и используется файл подкачки на диске, что заведомо более медленно.

Теперь можно провести небольшое расследование и узнать что стало причиной этой ситуации.

Подозрение падает в первую очередь на 1С сервер. Просто по опыту, т. к. он расположен на той же машине. Если построить виртуальный график по потреблению памяти процессами rphost, то сразу видно (см. рисунок ниже), что память выровнялась, как только высвободили память один или несколько rphost (точка №3). Забегая вперед, скажу, что это один rphost и мы его сейчас найдем.
Чтобы выявить виновника ситуации, достаточно в главном окне мониторинга Perfexpert пробежать курсором по шкале времени в диапазоне пика потребления памяти rphost’ами (точки 1-3) и посмотреть на чём/ком растет потребление.
Покажу картину процессов сразу в точке №3 (на 1-й и 2-й точке картины полностью аналогичны, только потребления памяти меньше).

Процесс rphost с PID 18124 потребил к этому моменту уже ~150 Гб оперативной памяти (см. вкладку «ТОП процессов» ячейку с желтым цветом). А чуть выше, на вкладке «Сессии 1С \Упр. блокировки», видно, что это сделал пользователь «1142», от имени которого запущено фоновое задание, потребившее к этому моменту 139 Гб памяти (тоже ячейка с желтым цветом). В колонке «Данные (ЖР)» видно, что выполнялся отчет «Рефинанс…». Время выполнения отчета к этому моменту составило 22 мин. 51с, что как раз совпадает со стартом роста потребления памяти (точка №1).
Итого, один пользователь, запустив один единственный отчет, может легко парализовать работу всей системы.
Понятно, что не всегда удается запретить пользователям запускать отчеты с фривольными настройками типа «Посмотрю-ка я статистику за 5 лет по всем организациям», но нужно об этом помнить. И не забывайте устанавливать ограничения по потреблению памяти как по сеансам, так и по рабочим процессам.
Ситуация 3. Блокировки на приросте файлов БД
Я приведу пример с файлом лога базы tempDB, но это может быть и лог любой базы данных.
Прирост лога транзакций файла базы данных — это типичная ситуация. Но когда это сопровождается блокировками — не очень хорошо.
На рисунке ниже показана ситуация, когда на сервере SQL начались блокировки (нижний график, выделенный желтым). Рядом выведены еще два графика — «Процент использования лога транзакций tempDB» и «Процент использования файлов tempDB». Если сравнить верхний график и нижний, то четко видно корреляцию, что основная масса блокировок началась, когда процент использования лога tempDB достиг горизонтальной полки в 100%. Как раз на верхнем графике

Происходит активное взаимодействие с базой tempDB
В сессиях SQL хорошо видно деревья блокировок, что где в корневых сессиях ресурсом блокировки является LOG_MANAGER

Для избегания приращения лога (что tempDB, что продуктивной БД) лучше сразу закладывать достаточный размер. А процесс увеличения файла лога провести в технологическое окно. Кроме того, в настройках файла лога устанавливайте настройку увеличения файла лога в абсолютных величинах, не в процентах.
Ну, конечно, и никто не отменял оптимизацию проблемного запроса. Если вы смогли выделить запрос, который приводит к этой ситуации, нужно попытаться его оптимизировать либо на уровне индексного тюнинга, на уровне кода.
Ситуация 4. Частые операции разбиения страниц данных
В MS SQL Server есть специальный счетчик, который показывает количество разбиений страниц в секунду (Page splits). Если совсем кратко, то разбиения страниц памяти происходят, когда на странице данных не хватает свободного места для вставки или обновления данных. Поэтому SQL Server переносит часть данных с этой страницы на другую. Соответственно, чем больше разбиений, тем больше фрагментация таблиц и индексов. Получаются накладные расходы в виде избыточных операций чтения/записи к памяти и диску, дополнительных циклов процессора. И все это может негативно сказаться на производительности запросов.
Обратимся к примеру из мониторинга Perfexpert, где можно вывести одновременно два графика –счетчик кол-ва разбиений страниц/сек и очереди к диску. И сопоставить их.

Видна корреляция, когда значительное увеличение количества split’ов ведет к росту очередей на диске. Таких ситуаций может быть немного. Тем не менее, рост счетчика разбиения страниц до значения несколько тысяч и даже десятков тысяч в секунду ведет к дополнительной нагрузке на дисковую подсистему и дополнительным временным издержкам.
В параметрах SQL Server есть настройка, на значение которой стоит обратить внимание — степень заполнения страниц индексов по умолчанию (fill factor). Именно эта настройка определяет, сколько свободного места для новых данных будет в индексе после перестроения. По умолчанию всем индексам параметр fill factor установлен в 0, это означает, что после перестроения индекса на странице не остается свободного места для вставки новых данных. Если СУБД все же приходится добавлять данные в такой индекс, ей требуется выделять место в другой секции файла данных — другими словами, любое добавление или изменение данных моментально приводит к росту фрагментации по такой таблице.
Замечу, что слишком низкое значение fill factor приводит к неоправданному росту занимаемого базой места на диске. Поэтому «золотой серединой» по нашему опыту считаются значения из диапазона 80–90. При таком значении fill factor размер базы разрастается на 5-10%, и остается место для изменения/добавления новых данных.
Ситуация 5. Длительность запросов выросла из-за плохого диска
И, наконец, рассмотрим ситуацию, когда диск стал-таки причиной замедлений в системе и его нужно менять на что-то более скоростное.
Этот кейс свежий совсем. Еще не остыл, можно сказать. Заказчик жаловался на деградацию скорости определенного запроса, анализ которого не выявил каких‑то патологий — запрос попадал в индекс, читал разумное количество данных и должен по всем раскладам выполняться быстрее. Гораздо быстрее. Поэтому и обратили внимание на поток чтения записи с диска.
Ниже представлены два скриншота, показывающих зависимость очереди к диску от объема записанных и считанных данных с разницей 2 минуты.


Эмпирически, передвигая курсор со шкалой времени было замечено, что при скорости обработки данных (Чтение + Запись) 10 Мб/с очереди к диску почти отсутствуют и находятся на нулевом уровне. Однако при увеличении траффика данных выше 10 Мб/с, как показано на втором рисунке, очереди к диску <E> значительно возрастают. Т. е. суммарный поток поток в 96 Мб/с вызвал огромную очередь к диску. Это ненормально.
Если открыть трассу DURATION, в которую попадают запросы длительностью более 5 секунд, то в ней встречаются много запросов, у которых фактическая длительность больше процессорного времени при отсутствии блокировок и взаимоблокировок на параллелизме (MAXDOP=1).

В нормальных условиях эти показатели должны совпадать.
SQL Server предоставляет статистику задержек ввода-вывода файлов баз данных, которая опять же говорит о том, что дисковая подсистема не соответствует требованиям к производительности современных СХД. Задержка записи в файл рабочей базы данных составляет до 130 мс при рекомендованным 5 мс. Совсем нехорошо.

Выводы и заключения
Подведем маленькие итоги. Мы рассмотрели 5 ситуаций, при анализе которых любой мониторинг производительности покажет нагрузку на диски и очереди, но лишь один последний связан действительно с проблемами дисковой системы, которая требует модернизации. Во всех остальных же случаях повышенная нагрузка на диски связана совершенно с другими причинами.
Я не хочу сказать, что админы этого не увидят. Вовсе нет. Но вероятность сделать неправильный вывод довольно высока, и мы в своей практике встречались с этим не раз.
Мы за системный анализ, за взгляд на проблему со всех сторон, т.к. причинно-следственная связь может быть очень неожиданная и неочевидная.
Ссылки на остальные части Записок оптимизатора 1С:
- Записки оптимизатора 1С (ч.1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
- Записки оптимизатора 1С (ч.2). Полнотекстовый индекс или как быстро искать по подстроке
- Записки оптимизатора 1С (ч.3). Распределенные взаимоблокировки в 1С системах
- Записки оптимизатора 1С (ч.4). Параллелизм в 1С, настройки, ожидания CXPACKET
- Записки оптимизатора 1С (ч.5). Ускорение RLS-запросов в 1С системах
- Записки оптимизатора 1С (ч.6). Логические блокировки MS SQL Server в 1С: Предприятие
- Записки оптимизатора 1С (ч.7). «Нелогичные» блокировки MS SQL для систем 1С предприятия
- Записки оптимизатора 1С (ч.8). Нагрузка на диски сервера БД при работе с 1С. Пора ли делать апгрейд?
- Записки оптимизатора 1С (ч.9). Влияние сетевых интерфейсов на производительность высоконагруженных ИТ-систем
- Записки оптимизатора 1С (ч.10): Как понять, что процессор — основная боль на вашем сервере MS SQL Server?
- Записки оптимизатора 1С (ч.11). Не всегда очевидные проблемы производительности на серверах 1С
- Записки оптимизатора 1С (ч.12). СрезПоследних в 1C: Предприятие на PostgreSQL. Почему же так долго?
- Записки оптимизатора 1С (ч.13). Что не так в журнале регистрации 1С в формате SQLite?
- Записки оптимизатора 1С (ч.14.1). Любите свою базу данных и не забывайте обслуживать
- Записки оптимизатора 1С (ч.14.2). Пересчет индексов на SSD–дисках. Делаем или игнорируем?
- Записки оптимизатора 1С (ч.14.3). Отличия в обслуживании статистик в MS SQL и в PostgreSQL
- Записки оптимизатора 1С (ч.15). Параллелизм запросов 1С в PostgreSQL