Записки оптимизатора 1С (часть 7). «Нелогичные» блокировки MS SQL для систем 1С предприятия
Продолжаем тему блокировок на сервере СУБД. Сегодня «нелогичные» блокировки. Нелогичные в кавычках, потому что с точки зрения пользователя они выглядят как обычные логические sql-блокировки (Записки оптимизатора 1С (часть 6). Логические блокировки MS SQL Server в 1С: Предприятие), но природа их совсем другая.
Блокировки на временных таблицах
В системах 1С это довольно распространенный вид блокировок, т.к. 1С очень активно использует базу [tempDB].
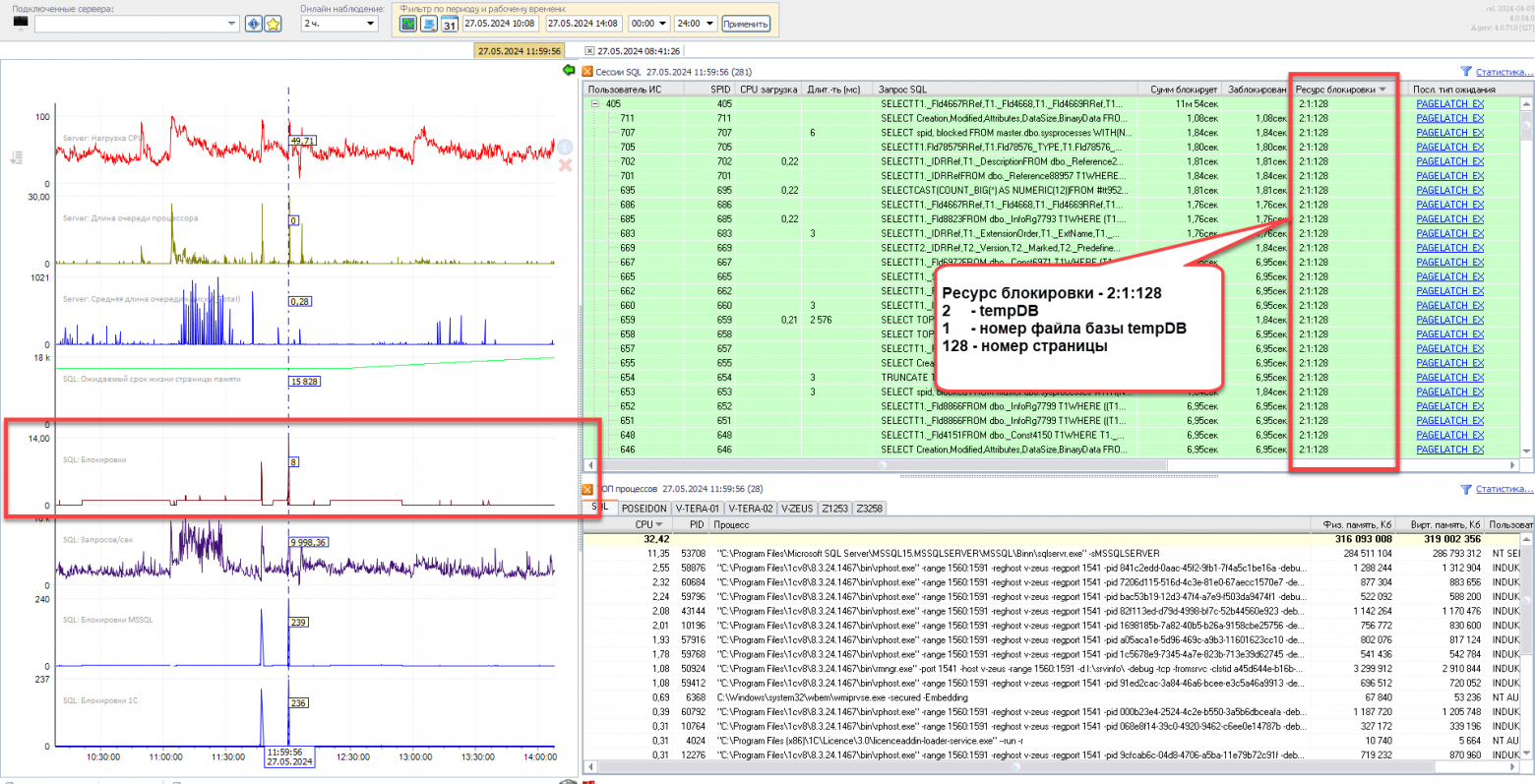
При создании и удалении большого множества временных таблиц база [tempDB] становится узким местом, особенно если количество файлов, на которое она разбита, маленькое. В этом случае возникают кратковременные блокировки PageLatсh_ХХ, когда множество сеансов пытаются одновременно получить доступ к системным страницам базы [tempDB] во время создания временных таблиц.
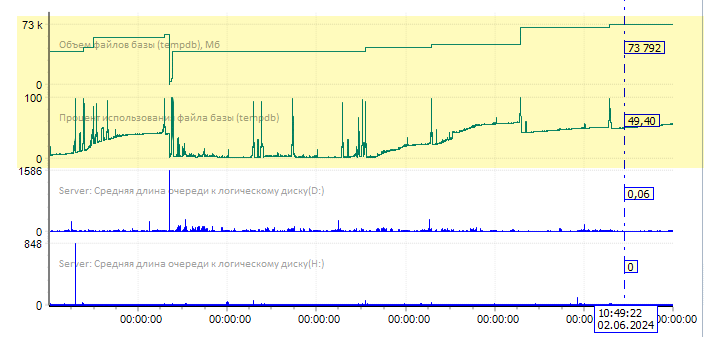
В последних версиях SQL Server количество файлов [tempDB] по умолчанию равно восьми, но очень часто имеет смысл его увеличить. Количество файлов, на которое можно разбить базу должно быть не больше количества всех логических ядер процессора (= количества одновременных потоков). И не забывайте, что все файлы должны быть одного размера. Первоначальный размер файлов можно посчитать заранее, получив статистику по тому, как меняется суммарный объем [tempDB] за период и как этот объем используется. Ниже как раз приведен графики изменения объема [tempDB] и процента ее использования за одну календарную неделю, и на первом счетчике видно, что максимальный объем [tempDB] достигал ~73 Гб:
В SQL Server 2019 был добавлен параметр MEMORY_OPTIMIZED TEMPDB_METADATA (оптимизированные метаданные tempdb в памяти). По умолчанию он выключен. И если его включить, то метаданные базы [tempDB] будут храниться в памяти, что должно снизить вероятность ожиданий PageLatсh_ХХ и ускорить часть операций с базой.
С этим параметром нужно быть осторожным и однозначной рекомендации по его использованию мы не дадим. Все очень индивидуально, нужно пробовать, но при этом не забывать, что есть риск, когда вся память в какой-то момент просто уйдет под метаданные [tempDB] . MS дает ряд рекомендаций как это контролировать и настраивать. Небольшую цитату приведу. Кому надо, найдет полный текст статьи:
· Увеличьте максимальное количество памяти сервера, чтобы обеспечить достаточный объем памяти для работы при наличии рабочих нагрузок с большим объемом tempdb.
· Периодически запускайте
sys.sp_xtp_force_gc.· Чтобы защитить сервер от потенциальной нехватки памяти, можно привязать базу данных tempdb к пулу ресурсов Resource Governor. Например, создайте пул ресурсов с помощью
MAX_MEMORY_PERCENT = 30. Затем используйте следующую командуALTER SERVER CONFIGURATION, чтобы привязать пул ресурсов к метаданным tempdb, оптимизированным для памяти.
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED TEMPDB_METADATA = ON (RESOURCE_POOL = '<PoolName>');Это изменение требует перезапуска, даже если метаданные, оптимизированные для tempdb памяти, уже включены.
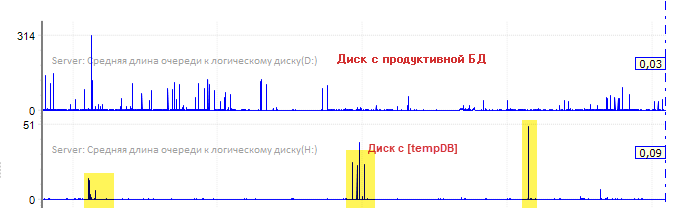
Опцию MEMORY_OPTIMIZED TEMPDB_METADATA имеет смысл рассмотреть, если на диске, где лежит [tempDB], наблюдаются постоянные очереди, а значит гарантированные замедления. В этом случае включение MEMORY_OPTIMIZED TEMPDB_METADATA скорее всего даст положительный эффект. На рисунке ниже показаны примеры очередей на дисках, где лежат обе базы – основная и [tempDB]. На диске <Н>, где расположена [tempDB], очереди есть, но они носят скорее эпизодический, некритический характер. Привел данные просто для примера – что и где смотреть в мониторинге Perfexpert.
Блокировки PageIOLatch
Для операций чтения и изменения данных SQL Server использует оперативную память, точнее ее часть, называемую Buffer Pool или Buffer Cache, и не использует напрямую дисковую подсистему. Такой подход позволяет получать хорошее время отклика, уменьшить количество обращений к диску (операций ввода/вывода) и дольше сохранить ему ресурс. Но чтобы поместить страницу данных в буферный кэш, ее необходимо сначала считать с диска. И вот на этот промежуток времени, пусть и кратковременный, страница блокируется. Ожидание завершения этого чтения – задержка PageIOLatch.
Задержки PageIOLatсh делятся внутри на несколько видов: PAGEIOLATCH_DT, PAGEIOLATCH_EX, PAGEIOLATCH_KP, PAGEIOLATCH_SH, PAGEIOLATCH_UP, но на данном уровне абстракции это не важно. Все они возникают, когда любой из запросов ждёт данных от диска, чтобы переместить их в буферный кэш, что и приводит к кратковременной блокировке буфера.
Чем меньше объем буферного кэша, тем быстрее он будет вымываться и тем чаще будет обращение к дисковой подсистеме. Основные причины почему вымывается буферный кэш:
- Изначальный недостаток оперативной памяти для сервера SQL Server. Недостаток может выражаться: в маленьком объеме физической памяти, в настройках SQL Server, а также в лицензионных ограничениях (SQL Server Standard Edition позволяет использовать не более 128 Гб для buffer pool).
- Неоптимальные запросы и неоптимальные планы выполнения запросов, которые приводят к избыточным чтениям миллионов строк. Таким образом, SQL Server постоянно не находит нужных страниц в buffer pool и для их получения обращается к заведомо более медленной дисковой подсистеме.
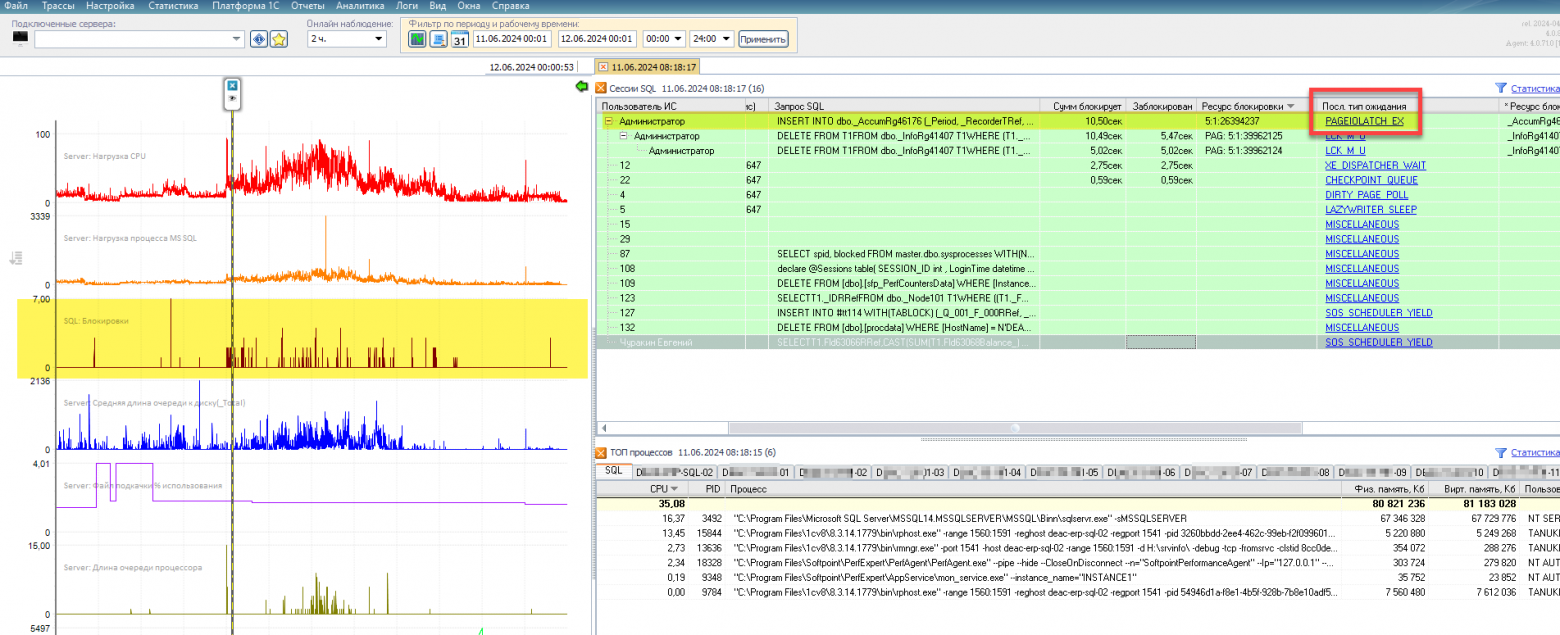
В мониторинге Perfexpert удобно смотреть полную картину по блокировкам как в моменте, так и в агрегированном виде. Для оперативного анализа в главном окне, в его левой части с графиками, видны периоды, когда появляются блокировки (третий график сверху). А в правой части (в окне «Сессии SQL») видно, что в выбранный момент времени Администратор собрал дерево блокировок, и на самом верху как раз блокировка с типом PageIOLatch_EX:
А суммарно за день картина по PageIOLatch такая:

Итого, если в системе есть существенные задержки PageIOLatch, то их, скорее всего, можно снизить, используя более быстрые диски, наращивая объём памяти и оптимизируя запросы. В редких случаях, когда SQL сервер использует сетевые хранилища (SAN или NAS), нужно обратить внимание на пропускную способность сети и ее отклик.
Блокировки на приращении файла лога
Эта кратковременная блокировка с типом ожидания PREEMPTIVE_OS_WRITEFILEGATHER. Указывает на то, что текущая задача SQL Server ожидает завершения операции ввода-вывода (I/O) в операционной системе, связанной с записью в файл лога. SQL Server не управляет этой операцией (она управляется ОС), и вынужден ждать ее окончания.
При этом в файле лога нет достаточного свободного места, а в настройках [tempDB] указан шаг прироста файла лога не в абсолютных значениях, а в процентах. Получается, что если файл лога изначально большой, то его прирост в процентах тоже становится большим. Соответственно, вероятность блокировки возрастает.
Покажу пример, когда происходит ожидание на росте лога [tempDB] (но равным образом это относится и к основной БД ).
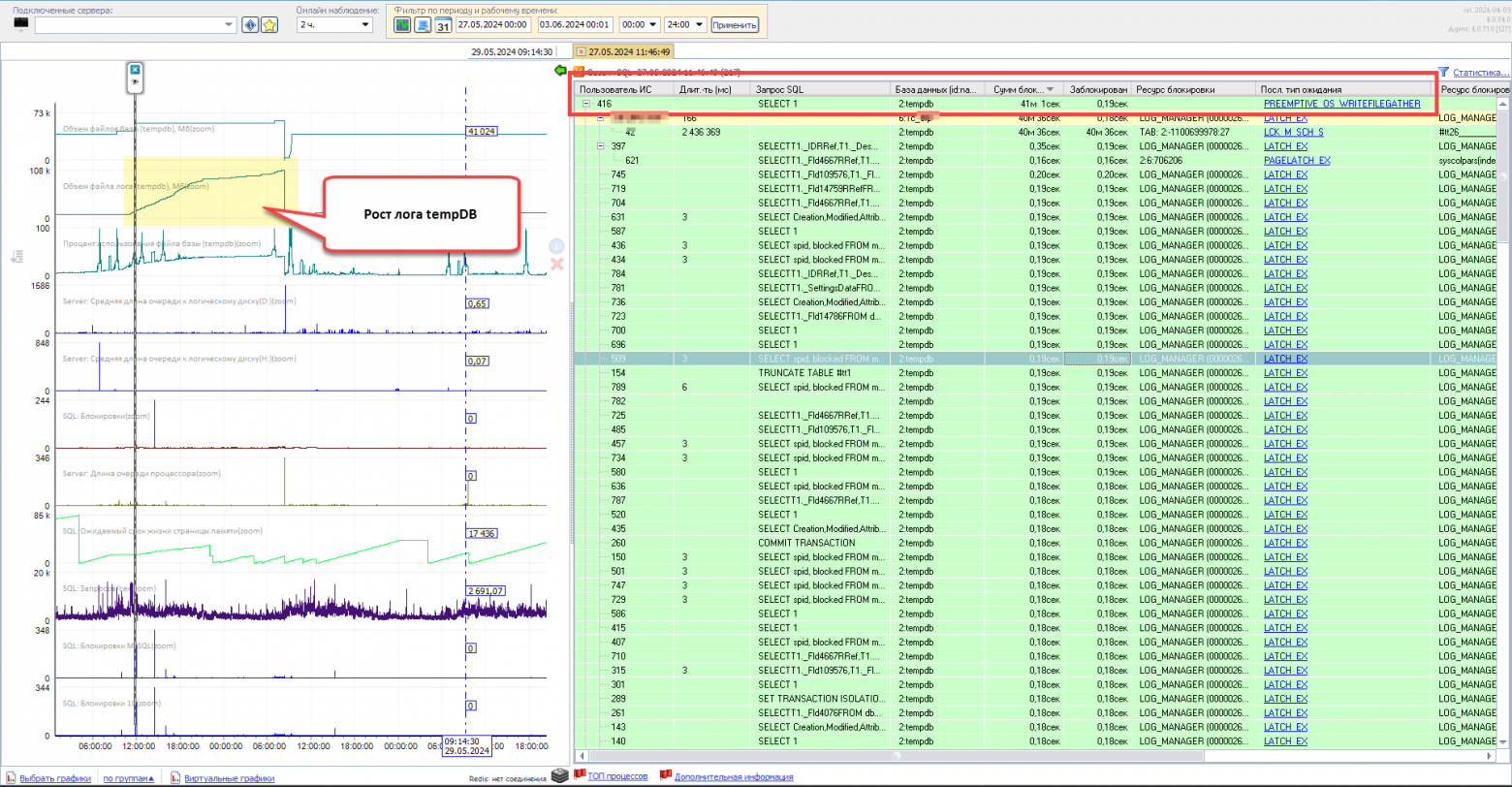
Пользователь [416] наложил блокировку PREEMPTIVE_OS_WRITEFILEGATHER и все остальные сессии в дереве блокировок его ждали.
Стандартная рекомендация – включить мгновенную инициализацию файлов (instant file initialization). Включение этой опции позволяет на порядки (до нескольких секунд) сократить время создания или приращения файлов данных. Если опция выключена, СУБД приходится заполнять нулями все заново выделяемое пространство, что часто выливается в запись нескольких гигабайт нулей на диск. При включенной опции СУБД просто резервирует необходимое место на диске без принудительного «зануления». Для включения опции мгновенной инициализации файлов необходимо пользователю ОС, из-под которого запускается служба MS SQL, выдать права Perform Volume Maintenance Tasks.
Другая рекомендация – проверить настройки прироста файла лога. Должен быть выбран параметр с фиксированным приращением файла (в Мб, не процент).
Блокировки на обновлении статистики
Это кратковременная блокировка, которая сопровождается ожиданием с типом LCK_M_SCH_M и означает ожидание получения эксклюзивного блокирования (SCH-M) на объект в базе данных. К изменениям схемы относятся не только операции создания или изменения колонок таблицы, но и операции обслуживания: перестроение индексов и пересчёт статистик. При пересчёте статистик ресурс блокировки отображается как «MD: database_id = 11 STATS…».
Причем, уровень блокирования самый строгий, когда блокируется любое другое чтение или запись в объекте. Если сессия ожидает на блокировке типа LCK_M_SCH_M, она ждет пока другие запросы завершат свою работу с объектом, прежде чем она сможет получить доступ к нему.
Возвращаясь к статистикам. Для выполнения запроса необходима статистика данных по таблице. Может случиться ситуация, когда какой-то произвольный запрос использует статистику, а автообновление статистики пытается ее обновить и повисает на сеансе пользователя, ожидая окончание выполнения запроса. При этом другие сеансы, для выполнения запросов которых необходима эта статистика, не могут получить ни старый вариант, ни новый рассчитанный, и массово висят на процессе автообновления статистики. Забавность этой ситуации в том, что все пользователи не работают с транзакциями, и блокировки могут формироваться запросами на чтение.
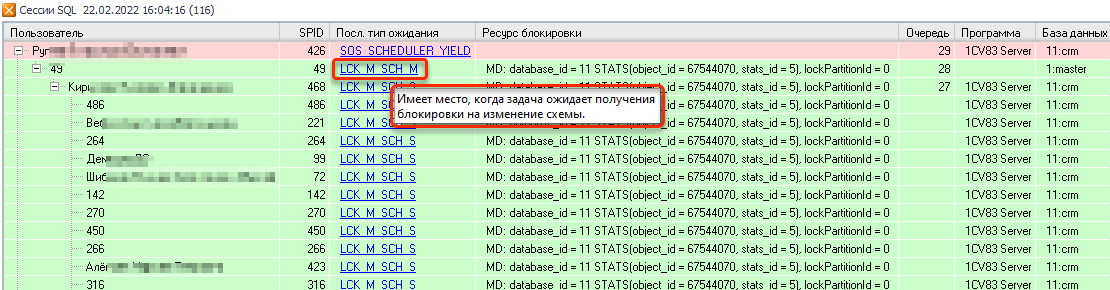
Рассмотрим пример, представленный ниже в виде дерева блокировок.
Источником блокировок выступало соединение с SPID 426. Следующим узлом блокировки выступало системное подключение со SPID 49 к базе «master» с типом ожидания — LCK_M_SCH_M.
Дальнейшая проверка показала, что в свойствах базы включены опции is_auto_update_stats_on и is_auto_update_stats_async_on.
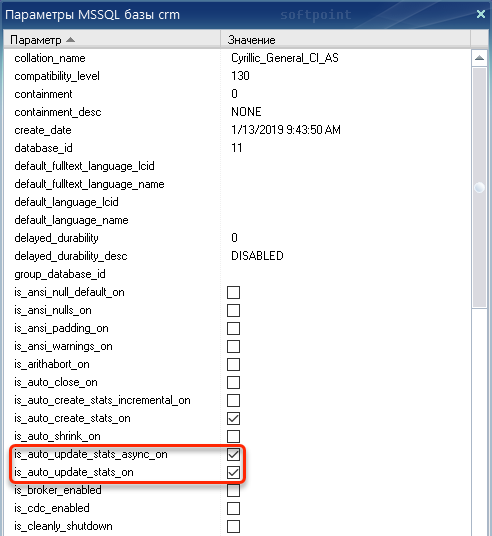
Если опции включены, то сервер СУБД может принять решение об обновлении статистики в любой момент. Получается, что в нашем случае произошло стечение нескольких обстоятельств, которые привели к появлению блокировок. С одной стороны, серверу СУБД необходимо было обновить статистику, и для этого была наложена блокировка схемы. А с другой стороны, выполнялась операция пользователя 1С «Руг….(SPID 426)», которая использовала имеющую статистику.
Блокировки на CXPacket
Те, кто используют в настройках SQL Server параллелизм, отличный от единицы (max degree of parallelism = 1), обязательно сталкиваются с такими ожиданиями.
В двух словах. Если сервер SQL принял решение распараллелить выполнение запроса на несколько потоков – инструкции в плане запросов выполняют одновременно несколько ядер CPU, то возникают дополнительные издержки на синхронизацию этих потоков. И достаточно часто бывает, что суммарное процессорное время меньше и даже много меньше, чем фактическая длительность запроса. То есть процессор больше ждал, чем работал. Это совсем нехорошо. Вот пример таких запросов:
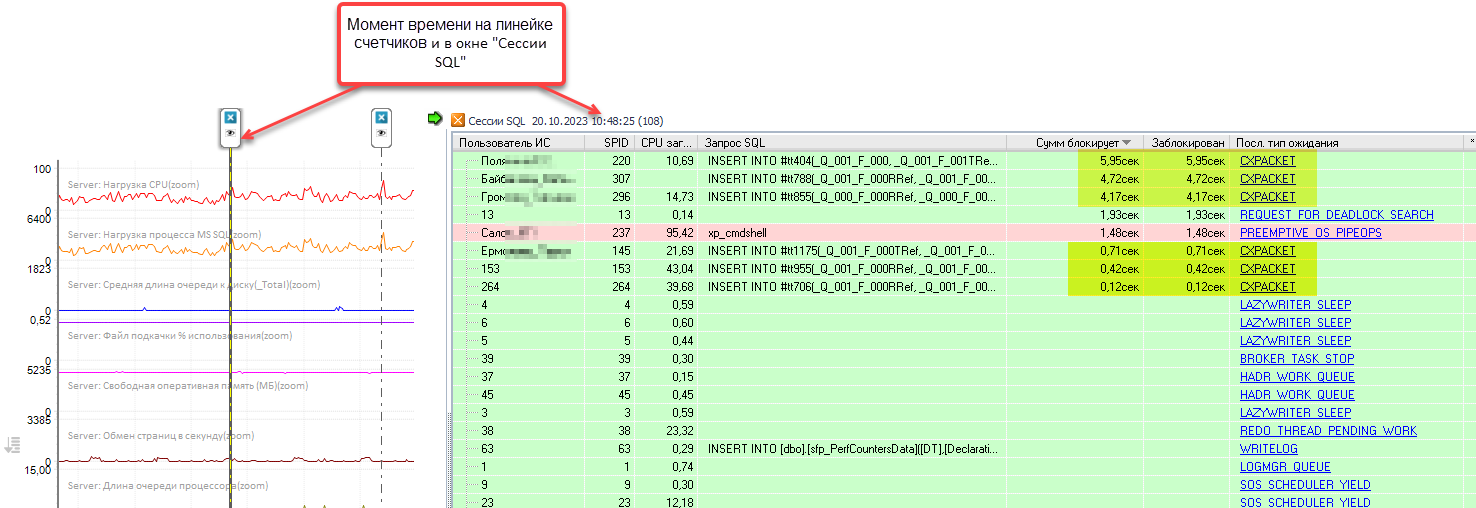
Нас интересуют строки, где в колонке «Последний тип ожиданий» значение равно CXPACKET. В колонке «Сумм. блокирует» видно сколько секунд эти запросы ожидают на параллелизме на выбранный момент времени (10:48:25). Например, SPID 220 ждет уже почти 6 секунд.
Теперь посмотрим в трассе DURATION за сколько этот запрос реально выполнился, и сколько времени ожидал.
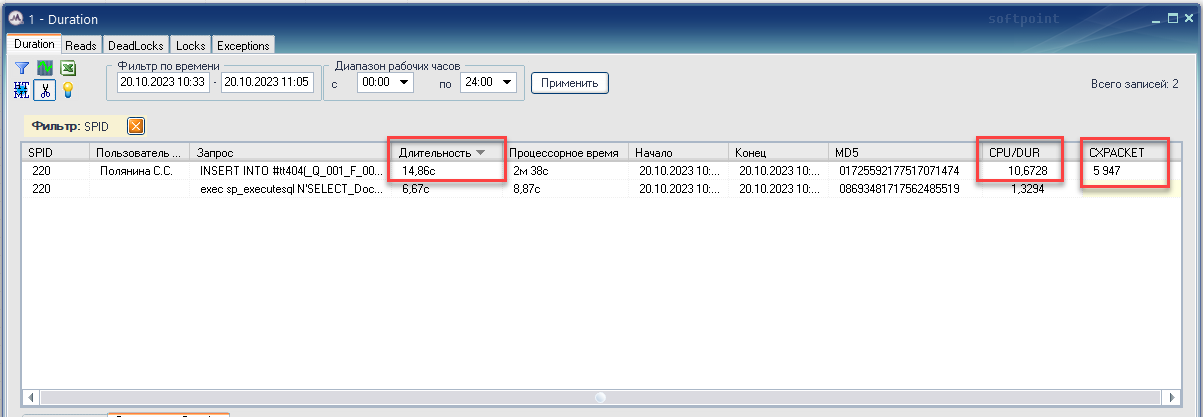
Видно, что запрос распараллелился в среднем на 11 ядер (колонка CPU/DUR показывает отношение суммарного процессорного времени к длительности запроса), выполнялся 14,86 сек и висел на ожиданиях всё те же 5,95 сек.
Рекомендации. Тут два подхода, которые мы предлагаем своим клиентам.
- Стандартный, для которого используются типовые настройки SQL Server.Можно попытаться подобрать оптимальную комбинацию параметров «max degree of parallelism» и «cost threshold for parallelism». Первым мы ограничим в принципе возможность использования ядер больше, чем укажем. А стоимостью параллелизма можно запретить распараллеливаться многим запросам, если у них стоимость того или иного оператора в плане запроса будет ниже указанного порога. Не самая тонкая настройка. Но других вариантов у штатных инструментов для работы с параллелизмом в 1С-системах нет.Процесс итерационный: меняем MAXDOP, смотрим результат, опять меняем MAXDOP, смотрим результат. Пробуем поднять или опустить COST, опять смотрим результат. И т.д.
- Эта стратегия более тонкая и предполагает использование внешнего инструмента Softpoint QProcessing.Основная идея – ограничение или, наоборот, увеличение значение MAXDOP для конкретного запроса. Кратко напомню, что QProcessing представляет собой программный прокси-сервер, который устанавливается между приложением (сервером приложений) и сервером баз данных SQL Server.
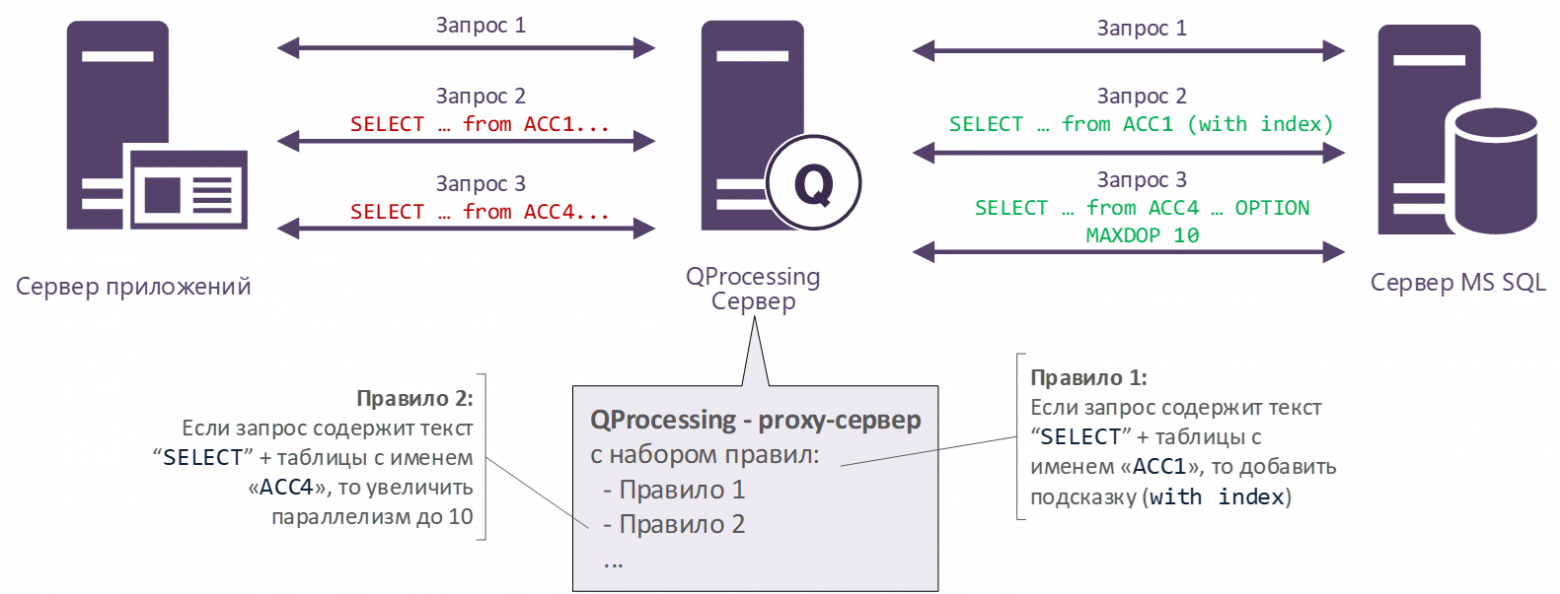
Соответственно, он по определенном правилу(ам) может перехватить любой запрос и модифицировать его, установив ему хинт. На рисунке выше как раз есть пример, где Запросу 3 добавляется хинт MAXDOP 10.
То есть, QProcessing позволяет «хирургическим образом», выборочно устанавливать запросу максимальную (или наоборот минимальную) степень параллелизма, с которой он может выполняться. А для остальных запросов будет действовать ограничение из глобальных настроек БД или сервера
Подробно про CXPACKET мы писали в отдельной статье. Кто не читал, рекомендую ознакомиться — Записки оптимизатора 1С (часть 4). Параллелизм в 1С, настройки, ожидания CXPACKET.
Блокировки на процессоре
Индикатором того, что в системе есть проблемы с процессором является, так называемый, общий тип ожидания SOS_SCHEDULER_YIELD. Наличие ожиданий с данным типом – это нормальная ситуация. Но если он преобладает в системе, то это признак наличия запросов с очень интенсивной нагрузкой на процессор. Либо запросы неоптимальные и сильно нагружают процессор (чаще всего), либо процессор перестал справляться с увеличенной нагрузкой и фиксируются очереди к нему.
Рассмотрим конкретный пример, связанный с наличием очередей к процессору. В таблице приведена статистика по ожиданиям SQL Server за один рабочий день.
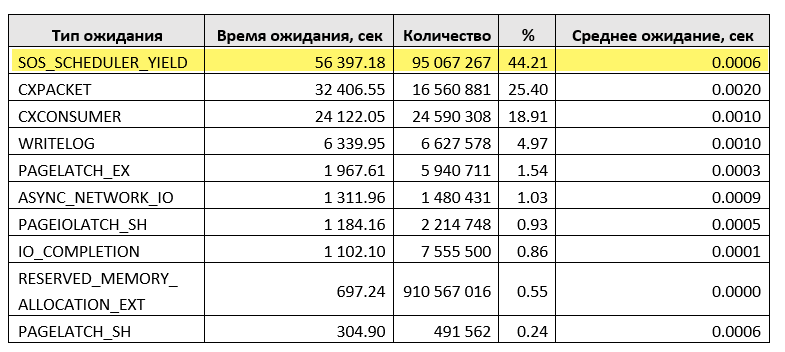
Первое место занимает SOS_SCHEDULER_YIELD. Этот тип ожидания возникает, когда «запрос» ждёт в очереди доступа к процессору. Очереди к процессору являются основными признаком появления данного типа ожидания.
Если посмотреть на нагрузку процессора в течение дня, то она еле-еле поднималась до 40%, а большей частью времени составляла 20-25%. При этом, уже в такие моменты в системе присутствуют продолжительные очереди к процессору, которые поднимаются до 12 и выше (второй график на рисунке ниже). Это говорит о том, что часто ресурс процессора недоступен, несмотря на небольшой показатель «Нагрузка CPU». Что косвенно подтверждается ожиданиями с типом SOS_SCHEDULER_YIELD.
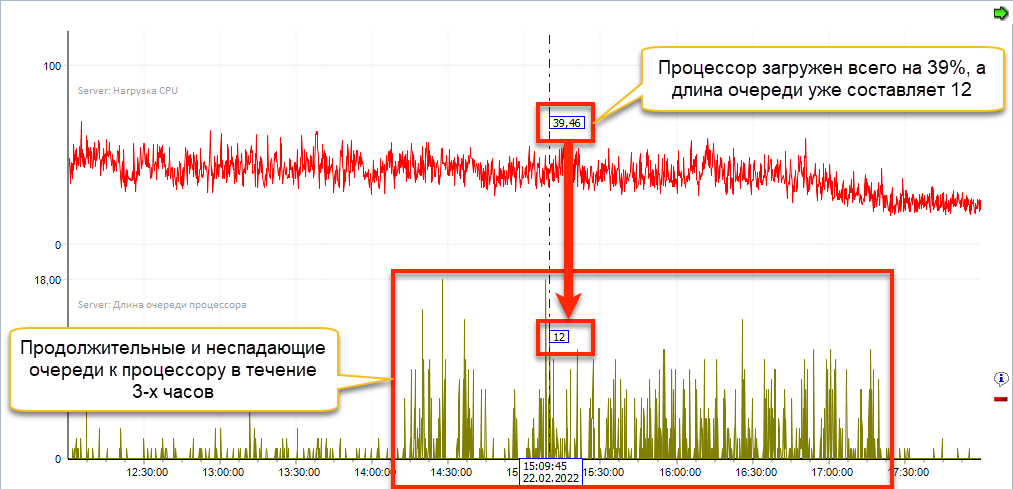
В последнее время мы часто встречаемся с такими картинами. Одна из вероятных причин – виртуализация серверов. На хосте находятся несколько виртуальных машин и между ними происходит конкуренция за процессорные ресурсы. Распространена ситуация, когда общее количество ядер на хосте меньше суммарного количества ядер по всем виртуальным машинам, а сервер СУБД очень чувствителен к таким вещам.
Выводы
С точки зрения пользователя все проблемы в системе одинаковые – система тормозит плюс ошибки блокировок. Но под капотом совершенно все разное. Каждая блокировка имеет свою природу и бороться с каждой из них нужно в соответствии с этой природой. Далеко не все системы мониторинга могут детализировать данные до типа ожидания? получить картину в моменте, за день, за два дня, за неделю, сравнить разные периоды между собой. А без должной информации очень легко ошибиться, ввести себя же в заблуждение и сделать неправильные выводы.
Ссылки на остальные части Записок оптимизатора 1С:
- Записки оптимизатора 1С (ч.1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
- Записки оптимизатора 1С (ч.2). Полнотекстовый индекс или как быстро искать по подстроке
- Записки оптимизатора 1С (ч.3). Распределенные взаимоблокировки в 1С системах
- Записки оптимизатора 1С (ч.4). Параллелизм в 1С, настройки, ожидания CXPACKET
- Записки оптимизатора 1С (ч.5). Ускорение RLS-запросов в 1С системах
- Записки оптимизатора 1С (ч.6). Логические блокировки MS SQL Server в 1С: Предприятие
- Записки оптимизатора 1С (ч.7). «Нелогичные» блокировки MS SQL для систем 1С предприятия
- Записки оптимизатора 1С (ч.8). Нагрузка на диски сервера БД при работе с 1С. Пора ли делать апгрейд?
- Записки оптимизатора 1С (ч.9). Влияние сетевых интерфейсов на производительность высоконагруженных ИТ-систем
- Записки оптимизатора 1С (ч.10): Как понять, что процессор — основная боль на вашем сервере MS SQL Server?
- Записки оптимизатора 1С (ч.11). Не всегда очевидные проблемы производительности на серверах 1С
- Записки оптимизатора 1С (ч.12). СрезПоследних в 1C: Предприятие на PostgreSQL. Почему же так долго?
- Записки оптимизатора 1С (ч.13). Что не так в журнале регистрации 1С в формате SQLite?
- Записки оптимизатора 1С (ч.14.1). Любите свою базу данных и не забывайте обслуживать
- Записки оптимизатора 1С (ч.14.2). Пересчет индексов на SSD–дисках. Делаем или игнорируем?
- Записки оптимизатора 1С (ч.14.3). Отличия в обслуживании статистик в MS SQL и в PostgreSQL
- Записки оптимизатора 1С (ч.15). Параллелизм запросов 1С в PostgreSQL