Записки оптимизатора 1С (часть 2). Полнотекстовый индекс или как быстро искать по подстроке
В прошлом выпуске записок оптимизатора я обещал вернуться к другим практическим кейсам использования программы QProcessing. Так вот, сегодня речь пойдет про полнотекстовый индекс в высоконагруженных базах данных 1С. А точнее об альтернативе, которую можно предложить взамен полнотекстового поиска от 1С или MS SQL.
Речь пойдет о поисковых запросах по подстроке, которые на стороне SQL превращаются в конструкцию LIKE ‘%текст%’. Именно с двумя %%. В этом случае стандартные индексы не работают и SQL производит полное сканирование таблиц.
Идея о замене стандартных механизмов поиска по подстроке появилась еще шесть лет назад, а в 2018г была выпущена статья на эту тему. Ссылку давать не буду на сторонний ресурс, но 1С-ники знают где искать :-). За эти годы мы уже не раз реализовывали замену стандартного поиска 1С в формах через нашу методику. Прежде чем описать подход, напомню несколько моментов почему такая потребность в принципе существует. Ведь есть движок полнотекстового поиска от СУБД и есть полнотекстовый поиск от 1С.
Где востребован поиск по подстроке с точки зрения бизнес-задач?
В большинстве случаев – это динамические списки: справочник договоров, контрагентов, заказов, платежных документов и т.п. Есть поле поиска или волшебное сочетание «Ctrl+F». Пользователи ищут кого-то по ФИО, ищут номер заказа, номер паспорта, номер платежки и т.п. Ищут как правило не полное ФИО, наименование или номер, а какую-то значимую часть. Например, номер договора ищут без префиксов или без лидирующих нулей. Кроме того, очень часто в поле поиска начинают набивать строку и система, не дожидаясь окончания ввода, начинает поиск чуть ли не после первого введенного символа.
Примерный круг задач я описал. Теперь тезисно перечислю некоторые подводные камни, которые сопровождают полнотекстовый поиск от 1С и от движка SQL. Погружаться в детали я не буду, т.к. про это уже много и не раз написано. Важно понимать то, что полнотекстовый поиск подходит далеко не всем и требует тщательного обслуживания.
Итак, некоторые особенности полнотекстового поиска, о которых следует помнить.
Полнотекстовый индекс SQL:
- Заполнение индекса происходит асинхронно и изменения применяются с некоторой задержкой относительно основной транзакции, зависящей от длины очереди обновления индекса. Задержка может быть как несколько секунд, так и несколько часов.
- Полнотекстовый поиск может искать только от начала слова. Т.е. если мы ищем, например, номер договора без префиксов и лидирующих нулей, то полнотекстовый поиск вернет нам ничего или совсем не то, что ожидаем. Соответственно, если такая задача имеется, то необходимо подготавливать отдельную колонку, где номер договора разбивается на значимые части.
Полнотекстовый поиск 1С:
- Версия платформы и режим совместимости сильно влияют на работу полнотекстового поиска. Так, на старых версиях платформы полнотекстовый поиск может работать некорректно или вообще не работать, выдавая пустой результат.
- При нештатных перезагрузках сервера СУБД индекс полнотекстового поиска данных (ППД) может прийти в негодность.
- При значительном или интенсивном изменении данных, регламентное задание по обновлению индекса ППД оказывает существенную нагрузку на систему. Время на перестроение индекса может измеряться десятками часов.
- Необходимо включить полнотекстовый поиск для всех объектов конфигурации, которые могут использоваться в качестве основной таблицы динамического списка. Также в полнотекстовом поиске должны участвовать все реквизиты объектов конфигурации, которые могут отображаться в динамическом списке и по которым может потребоваться поиск.
- Поиск выполняется не по всем колонкам динамического списка (и объекта конфигурации), а только по тем колонкам, которые отображаются в таблице. А поиск по ссылочным полям выполняется по полям представления, которые также нужно не забывать добавлять в полнотекстовый индекс.
Все эти аспекты делают процедуру обслуживания индекса довольно трудоемкой. Ведь если что-то настроено не так, индекс не отработает и поиск вернет либо ничего, либо переключится на стандартный механизм.
Задача поиска по подстроке очень востребована и в нашей практике поддержки высоконагруженных систем мы встречали разные варианты ее реализации, но преимущественно это были самописные механизмы поиска. При этом штатный поиск во многих формах очень часто запрещался на уровне прав и интерфейсов, либо переписывался с различными ограничениями: состав полей для поиска, количество вводимых символов не менее N, разделением строки на значимые символы и распределением их по колонкам и использованием поиска по начальным символам.
Поиск по подстроке нужен, но полнотекстовый индекс использовать не хотим. Как быть?
Основная проблема с полнотекстовыми индексами – это настроить их на практические задачи и поддерживать в актуальном состоянии состав индексируемых полей, чтобы обеспечить непротиворечивость данных при поиске. Под непротиворечивостью я подразумеваю довольно распространенные ситуации при использовании полнотекстового поиска, когда он возвращает пустую или неверную выборку. Это может приводить к неверным действиям пользователя. Например, пользователь добавит в справочник новый товар, который окажется дублем, ведь поиск его не нашел, а он в справочнике есть. Или пользователь объявит клиенту об отсутствии позиции в каталоге, на складе и т.п.
Расскажу о нашем опыте реализации быстрого поиска с помощью программы QProcessing.
Нужно было модернизировать механизм поиска среди платежных документов по полю «Назначение платежа», в котором может содержаться ФИО, номер договора, паспорт и т.п. Поиск должен выдавать пользователю список документов, в которых встречается набранная строка поиска.
У клиента уже был реализован свой поиск, полностью самописный (на 1С). Время поиска в среднем занимало 5-20 секунд (не прям уж запредельно большие цифры), но при этом обслуживание поиска было трудоёмким, отнимало много времени у техподдержки, перезаполнение «индекса» часто не успевало выполниться в регламентное окно и накладывалось на рабочий период, что приводило к падению производительности всей системы, вплоть до простоев.
Итого, задача в общем виде формулировалась как:
- Ускорить поиск в 1С для отбора платежных документов по части комментария из поля «Назначение платежа» (не более 5…8 сек).
- Снизить трудозатраты на обслуживание механизма поиска, чтобы оно гарантированно укладывалось в технологическое окно (1-2 часа).
К решению мы шли в два этапа.
Этап 1. Используем полнотекстовый индекс SQL
1. Разбить строку на части. Разделителем может являться пробел, точка с запятой, запятая и т.д. Для разбиения использовалась специальная библиотека Word Breaker SQLNGRAM.DLL.
2. Создать уникальный некластерный индекс по одной колонке. В любом документе (или справочнике) такая колонка есть – это Ссылка.
if not exists(
select top 1 1
from sys.indexes
where name = N'sfp_index4fulltext '
and object_id = object_id(N'_Document272'))
create unique nonclustered index sfp_index4fulltext on _Document272 (_IDRRef)
3. Создать для полнотекстового поиска отдельную колонку – expanded_descr, которая будет содержать комбинацию необходимых символов для поиска.Code language: JavaScript (javascript)if not exists (
select top 1 1
from sys.columns
where name = N'expanded_descr'
and object_id = object_id(N'_Document272'))
alter table _Document272 add expanded_descr nvarchar(max)Code language: SQL (Structured Query Language) (sql)4. Созданная колонка заполняется необходимыми данными
if exists(
select top 1 1
from sys.triggers
where name = N'sfp_update_exp_description')
declare @disable_tr nvarchar(max)
select @disable_tr = 'disable trigger ['+tr.name + '] on ['+t.name+']'
from sys.triggers tr
inner join sys.tables t on t.object_id = tr.parent_id and tr.name = 'sfp_update_exp_description'
exec sp_executesql @disable_tr
go
UPDATE x
SET x.expanded_descr =
/* select expanded_descr = */
replace(
replace(
replace(
replace(
replace(
replace(
lower(x._Description + N' '+ x._Fld17764)
, N' ', N'@@'),
N',', N'.'),
N'(', N'#<'),
N')', N'#>'),
N'&', N'#$'),
N'!', N'##')
FROM _Document272 x
WHERE x._Folder = 0x1
AND x._Fld1401 = 0
GO
if exists(
select top 1 1
from sys.triggers
where name = N'sfp_update_exp_description')
declare @enable_tr nvarchar(max)
select @enable_tr = 'enable trigger ['+tr.name + '] on ['+t.name+']'
from sys.triggers tr
inner join sys.tables t on t.object_id = tr.parent_id and tr.name = 'sfp_update_exp_description'
exec sp_executesql @enable_tr
go
Code language: SQL (Structured Query Language) (sql)5. Добавляется триггер, обновляющий содержимое колонки expanded_descr, если в элемент справочника были внесены изменения. Одновременно выполняется экранирование символов, которые могут быть служебными с точки зрения полнотекстового поиска
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
IF OBJECT_ID ('sfp_update_exp_description', 'TR') IS NOT NULL
DROP TRIGGER sfp_update_exp_description;
GO
CREATE or ALTER TRIGGER [dbo].[sfp_update_exp_description] ON [dbo].[_Document272]
AFTER UPDATE
,INSERT
AS
BEGIN
SET NOCOUNT ON
IF NOT (
UPDATE (_Description)
OR
UPDATE (_Fld17764) /* НаименованиеПолное */
)
RETURN;
UPDATE x
SET x.expanded_descr =
/* select expanded_descr = */
replace(
replace(
replace(
replace(
replace(
replace(
lower(x._Description + N' '+ x._Fld17764 )
, N' ', N'@@'),
N',', N'.'),
N'(', N'#<'),
N')', N'#>'),
N'&', N'#$'),
N'!', N'##')
FROM _Document272 x
INNER JOIN inserted i ON x._IDRRef = i._IDRRef
WHERE x._Folder = 0x1
AND x._Fld1401 = 0
END
Code language: SQL (Structured Query Language) (sql)6. Создаётся каталог полнотекстового поиска и, собственно, сам индекс полнотекстового поиска.
if not exists (select top 1 1
from sys.fulltext_catalogs
where name = 'basic_ftc')
CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF
AS DEFAULT
AUTHORIZATION [dbo]
GO
if exists(
select top 1 1 from sys.fulltext_indexes
where object_id = object_id(N'_Document272'))
drop fulltext index on _Document272
create fulltext index on _Document272 (expanded_descr Language 1)
key index sfp_index4fulltext
with change_tracking = Auto
Code language: SQL (Structured Query Language) (sql)Далее с помощью QProcessing при помощи набора правил выполняется замена поискового запроса по подстроке (LIKE @P4) на полнотекстовый поиск по заранее подготовленной колонке: CONTAINS (T1. expanded_descr, @P4).
Результат. В целом все работало, поиск работал быстро. В 99% случаях корректно. Но бывали прецеденты, что поиск возвращал «ничего» или неверные строки (ссылки на документы), в которых искомой подстроки не было. Например, в первый раз поиск возвращал позицию, а при повторном запросе через несколько секунд уже ничего не возвращал.
В общем, это было непрогнозируемо, необъяснимо и непонятно, и сводилось к формулировке «Ну вот так работает полнотекстовый индекс».
Поэтому появился второй этап.
Этап 2. Свой аналог полнотекстового индекса
Основная идея – разбить строку «Назначение платежа» каждого документа на N частей окном (интервалом) 6 символов (6 – выбранное эмпирически ограничение на минимальную длину строки поиска) и смещением на один символ до конца строки. При этом Смещение окна учитывает разделители типа «;», «.», «:», «/» и т.д. То есть, если внутри окна содержится знак разделителя, то оно в индекс не входит.
Пример разбиения строки назначения платежа и ее упаковки в таблицу с учетом разделителей.
Платеж по договору №ФС-2134124124;Иванов Иван Иванович;паспорт№1378921
| Подстрока из шести символов | Попадает в индекс или нет |
| Платеж | Да |
| латеж | Да |
| атеж п | Да |
| теж по | Да |
| … | |
| 124;Ив | Нет |
| 24;Ива | Нет |
| 4;Иван | Нет |
| ;Ивано | Нет |
| Иванов | Да |
| … | |
| в Иван | Да |
| … | |
| 378921 | Да |
Последовательность действий похожа на предыдущий этап.
1. Создание индексной таблицы
CREATE TABLE [dbo].[FullIndex](
[id] [varchar](6) NOT NULL,
[ref] [binary](16) NOT NULL,
[c] [bigint] IDENTITY(1,1) NOT NULL,
CONSTRAINT [PK_FullIndex] PRIMARY KEY CLUSTERED
(
[id] ASC,
[ref] ASC,
[c] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GOCode language: SQL (Structured Query Language) (sql)2. Создание некластерного индекса для индексной таблицы
CREATE NONCLUSTERED INDEX [ind1] ON [dbo].[FullIndex]
(
[ref] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GOCode language: SQL (Structured Query Language) (sql)3. Создание хранимой процедуры по разбиению строки на слова
CREATE PROC [dbo].[SetFullIndex] @Str varchar(max), @_IDRref binary(16), @fulltextindexname varchar(256)
AS
SET NOCOUNT ON
declare @tempstr varchar(max)
declare @int int
declare @sql varchar(max)
declare @delsql varchar(max)
declare @startid int
declare @endid int
set @startid = 1
SET @tempstr = ''
SET @delsql = 'DELETE FROM ' + @fulltextindexname + ' WHERE ref = 0x'+CONVERT(varchar(max),@_IDRref,2) +' '
SET @sql = 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES'
SET @int = 1
WHILE CHARINDEX(';',@str)<>0
BEGIN
SET @endid = CHARINDEX(';',@str)
SET @tempstr = SUBSTRING(@str,@startid,@endid-1)
/*print @Str
print STR(@startid)
print STR(@endid)
print @tempstr*/
IF LEN(@tempstr) > 6
BEGIN
SET @int = 1
WHILE @int + 5 <= LEN(@tempstr)
BEGIN
IF @sql <> 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES'
SET @sql = @sql + ','
SET @sql = @sql + '('''
+ REPLACE(SUBSTRING(@tempstr,@int,6),'''','''''') + ''',0x'+CONVERT(varchar(100),@_IDRref,2) + ') '
SET @int = @int+1
END
END ELSE
BEGIN
IF @sql <> 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES'
SET @sql = @sql + ','
SET @sql = @sql + '('''
+ REPLACE(@tempstr,'''','''''') +''',0x'+CONVERT(varchar(100),@_IDRref,2) + ') '
END
SET @Str = SUBSTRING(@str,@endid+1,len(@Str)-@endid)
END
--print @str
IF LEN(@str)>0
BEGIN
SET @tempstr = @str
IF LEN(@tempstr) > 6
BEGIN
SET @int = 1
WHILE @int + 5 <= LEN(@tempstr)
BEGIN
IF @sql <> 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES'
SET @sql = @sql + ','
SET @sql = @sql + '('''
+ REPLACE(SUBSTRING(@tempstr,@int,6),'''','''''') +''',0x'+CONVERT(varchar(100),@_IDRref,2) + ') '
SET @int = @int+1
END
END ELSE
BEGIN
IF @sql <> 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES'
SET @sql = @sql + ','
SET @sql = @sql + '('''
+ REPLACE(@tempstr,'''','''''') +''',0x'+CONVERT(varchar(100),@_IDRref,2) + ') '
END
END
--print @sql
Exec(@delsql)
EXEC(@sql)Code language: SQL (Structured Query Language) (sql)4. Создание триггера на таблице с документами на изменение индексной таблицы
СREATE TRIGGER [dbo].[sfp_update_fulltextindex] ON [dbo].[_Document272]
AFTER UPDATE
,INSERT
AS
BEGIN
SET NOCOUNT ON
IF (
UPDATE (_Fld23035)
)
BEGIN
DECLARE @fulldescr varchar(max), @IDRref binary(16)
DECLARE fullindex CURSOR FOR
SELECT _Fld23035 as fulldescr, _IDRRef
FROM INSERTED
OPEN fullindex
FETCH NEXT FROM fullindex
INTO @fulldescr, @IDRref
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC SetFullIndex @fulldescr, @IDRref, 'FullIndex'
FETCH NEXT FROM fullindex
INTO @fulldescr, @IDRref
END
CLOSE fullindex;
DEALLOCATE fullindex;
END
ENDCode language: SQL (Structured Query Language) (sql)5. Первоначальное заполнение индексной таблицы.Самая долгая процедура и длилась более суток. В результате индексная таблица заняла более 300 Гб.
DECLARE @int int
DECLARE @max int
DECLARE @tempidrref binary(16)
DECLARE @tempstr varchar(max)
SET @int = 1
IF OBJECT_ID('tempdb..#AllRows') is null
CREATE TABLE #AllRows
(id int identity(1,1) primary key, _IdRref binary(16), _str nvarchar(4000))
ELSE
truncate table #AllRows
INSERT INTO #AllRows(_IDRref,_str)
SELECT _IDRref, _Fld23035 expanded_descr
from _Document272
SELECT @max = max(id) from #AllRows
WHILE @int<=@max
BEGIN
SELECT @tempidrref = _IDRref,@tempstr = _str from #AllRows where id = @int
Exec SetFullIndex @tempstr,@tempidrref,'FullIndex'
SET @int = @int + 1
ENDCode language: SQL (Structured Query Language) (sql)6. Далее настраиваем QProcessing и подменяем штатные поисковые запросы с LIKE%% от 1С на модифицированные
Исходный запрос
SELECT
T1._IDRRef,
T1._Marked,
...
T1._Fld23035,
...
FROM dbo._Document272 T1
WHERE ((T1._Fld2507 = @P10)) AND ((T1._Fld23035 LIKE @P11))',
N'@P1 varbinary(16),@P2 varbinary(16),@P3 varbinary(16),@P4 numeric(10),
@P5 numeric(10),@P6 numeric(10),@P7 numeric(10),@P8 numeric(10),
@P9 numeric(10),@P10 numeric(10),@P11 nvarchar(4000)',0x8FE88206F16BC0A94F138691C51DBB25, 0x8FE88206F16BC0A94F138691C51DBB25, 0x8FE88206F16BC0A94F138691C51DBB25,
10,9,8,2,1,0,0,N'%Иванов Иван%'Code language: SQL (Structured Query Language) (sql)Измененный запрос
Поскольку количество возвращаемых записей из таблицы индекса может быть достаточно большим по популярным строкам (тысячи и даже десятки тысяч), то для уменьшения выборки в подменном запросе, без исключения основного условия с LIKE, мы вставляем дополнительную фильтрацию. Условие содержит не только первые шесть символов поисковой строки, но и последние шесть символов.
SELECT
T1._IDRRef,
T1._Marked,
...
T1._Fld23035,
...
FROM dbo._Document272 T1
WHERE (
T1._IDRRef IN (
SELECT t1.ref
FROM FullIndex t1
INNER JOIN FullIndex t2
ON t1.ref = t2.ref
INNER JOIN FullIndex t3
ON t1.ref = t3.ref
WHERE t1.id = SUBSTRING(@P11, 2, 6)
AND t2.id = SUBSTRING(@P11, LEN(@P11) - 6, 6)
AND t3.id = SUBSTRING(@P11, IIF(LEN(@P11) > 11,5,2), 6)
)
)
AND ((T1._Fld2507 = @P10)) AND ((T1._Fld23035 LIKE @P11))',
N'@P1 varbinary(16),@P2 varbinary(16),@P3 varbinary(16),@P4 numeric(10),
@P5 numeric(10),@P6 numeric(10),@P7 numeric(10),@P8 numeric(10),
@P9 numeric(10),@P10 numeric(10),@P11 nvarchar(4000)',0x8FE88206F16BC0A94F138691C51DBB25,
0x8FE88206F16BC0A94F138691C51DBB25, 0x8FE88206F16BC0A94F138691C51DBB25,
10,9,8,2,1,0,0,N'%Иванов Иван%'Code language: SQL (Structured Query Language) (sql)Полученные результаты
1) Скорость поиска
По результатам внедрения было проведено отдельное автоматическое тестирование механизма поиска и сравнение со старым. Было отобраны 18 000 «номеров документов» и по ним осуществлен поиск среди документов за 6 лет. Время поиска фиксировалось.
Результаты представлены на рисунке ниже.
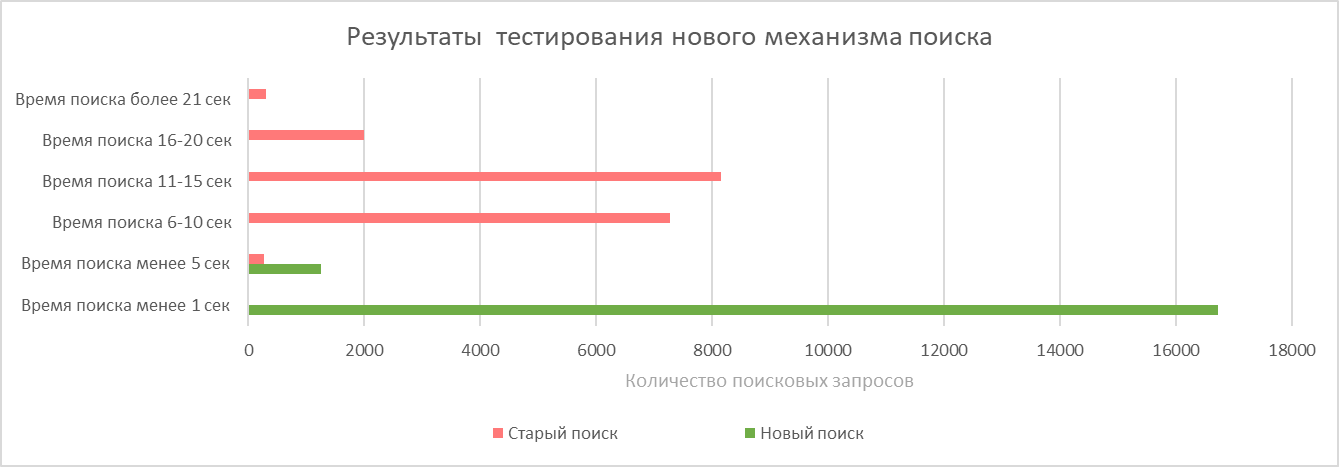
Комментарии, полагаю, излишни. Поиск в 1С ускорился в сотни раз и в 90% случаев стал занимать меньше 1 секунды.
2) Обслуживание и размер индексной таблицы [FullIndex]
После первоначального заполнения в таблице оказалось 2 млрд. строк, объём таблицы составил 345 Гб. Время первоначального заполнения – чуть более суток. У всех это время будет, естественно, разное и зависит от количества строк в исходной таблице (25 млн. строк), количества символов в поле комментария (в среднем 160 символов) и от аппаратных ресурсов.
При общем размере базы данных ~12 Тб увеличение ее размера составило ~3%.
Обновление записей таблицы [FullIndex] происходит автоматически – либо по триггеру на изменение таблицы [_Document272], либо по заданию с любой указанной периодичностью. Мы остановились на задании, чтобы исключить ненужные блокировки у пользователей.
Кроме того, настроили отдельное задание на пересчет статистик по таблице [FullIndex] раз в сутки, чтобы они пересчитывались гарантированно, независимо от пересчета статистик по всем остальным таблицам.
Ссылки на остальные части Записок оптимизатора 1С:
- Записки оптимизатора 1С (ч.1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
- Записки оптимизатора 1С (ч.2). Полнотекстовый индекс или как быстро искать по подстроке
- Записки оптимизатора 1С (ч.3). Распределенные взаимоблокировки в 1С системах
- Записки оптимизатора 1С (ч.4). Параллелизм в 1С, настройки, ожидания CXPACKET
- Записки оптимизатора 1С (ч.5). Ускорение RLS-запросов в 1С системах
- Записки оптимизатора 1С (ч.6). Логические блокировки MS SQL Server в 1С: Предприятие
- Записки оптимизатора 1С (ч.7). «Нелогичные» блокировки MS SQL для систем 1С предприятия
- Записки оптимизатора 1С (ч.8). Нагрузка на диски сервера БД при работе с 1С. Пора ли делать апгрейд?
- Записки оптимизатора 1С (ч.9). Влияние сетевых интерфейсов на производительность высоконагруженных ИТ-систем
- Записки оптимизатора 1С (ч.10): Как понять, что процессор — основная боль на вашем сервере MS SQL Server?
- Записки оптимизатора 1С (ч.11). Не всегда очевидные проблемы производительности на серверах 1С
- Записки оптимизатора 1С (ч.12). СрезПоследних в 1C: Предприятие на PostgreSQL. Почему же так долго?
- Записки оптимизатора 1С (ч.13). Что не так в журнале регистрации 1С в формате SQLite?
- Записки оптимизатора 1С (ч.14.1). Любите свою базу данных и не забывайте обслуживать
- Записки оптимизатора 1С (ч.14.2). Пересчет индексов на SSD–дисках. Делаем или игнорируем?
- Записки оптимизатора 1С (ч.14.3). Отличия в обслуживании статистик в MS SQL и в PostgreSQL
- Записки оптимизатора 1С (ч.15). Параллелизм запросов 1С в PostgreSQL