Записки оптимизатора 1С (ч.16). Риски падения Postgres: потребление и высвобождение памяти процессами postgres
Введение
Статья родилась в ходе наблюдения за одной из систем на Postgres, что у нас на поддержке. Результаты наблюдения несколько удивили, поэтому делюсь, ибо причинно-следственные связи далеко не очевидны.
Триггером к изучению, можно сказать, даже к расследованию, послужило событие, когда однажды утром сервер PG завалился, потому что процессы postgres заняли всю память. Но поговорить я хочу не конкретно о том событии, а больше о странной особенности работы Postgres с памятью, т.к. события с резким падением свободной оперативной памяти были не единичны и требовалось разобраться в причинах.
Мы стали копать и обнаружили интересные вещи: не все йогурты одинаково полезны процессы postgres высвобождают память после завершения запросов. Поэтому провели дополнительное исследование, чтобы подтвердить закономерность.
Пример работы с памятью Postgres+1C
Начну с наглядного примера работы Postgres в связке с 1С (не с того, что привел к падению, но принцип тот же).
Ниже на скрине из мониторинга Perfexpert видно, что в системе в ~11:56 запустилось порядка 400 фоновых заданий 1С и объем доступной оперативной памяти на сервере СУБД снизился.
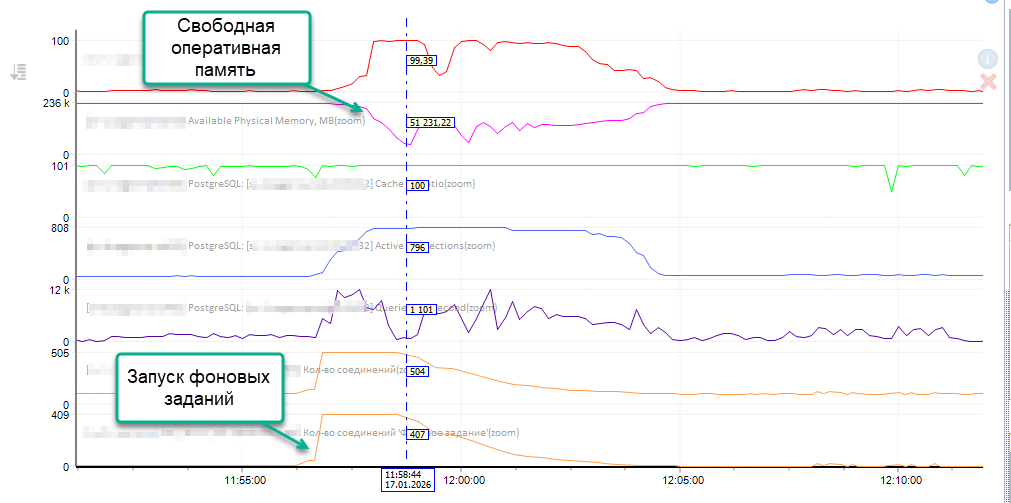
С одной стороны ничего такого страшного не произошло – в этот раз оперативная память в ноль не упала (второй сверху розовый график), сервер устоял. Но смутило другое. На протяжении всего интервала выполнения фоновых заданий видно множество неактивных процессов postgres, которые уже ничего не делают, но память держат:
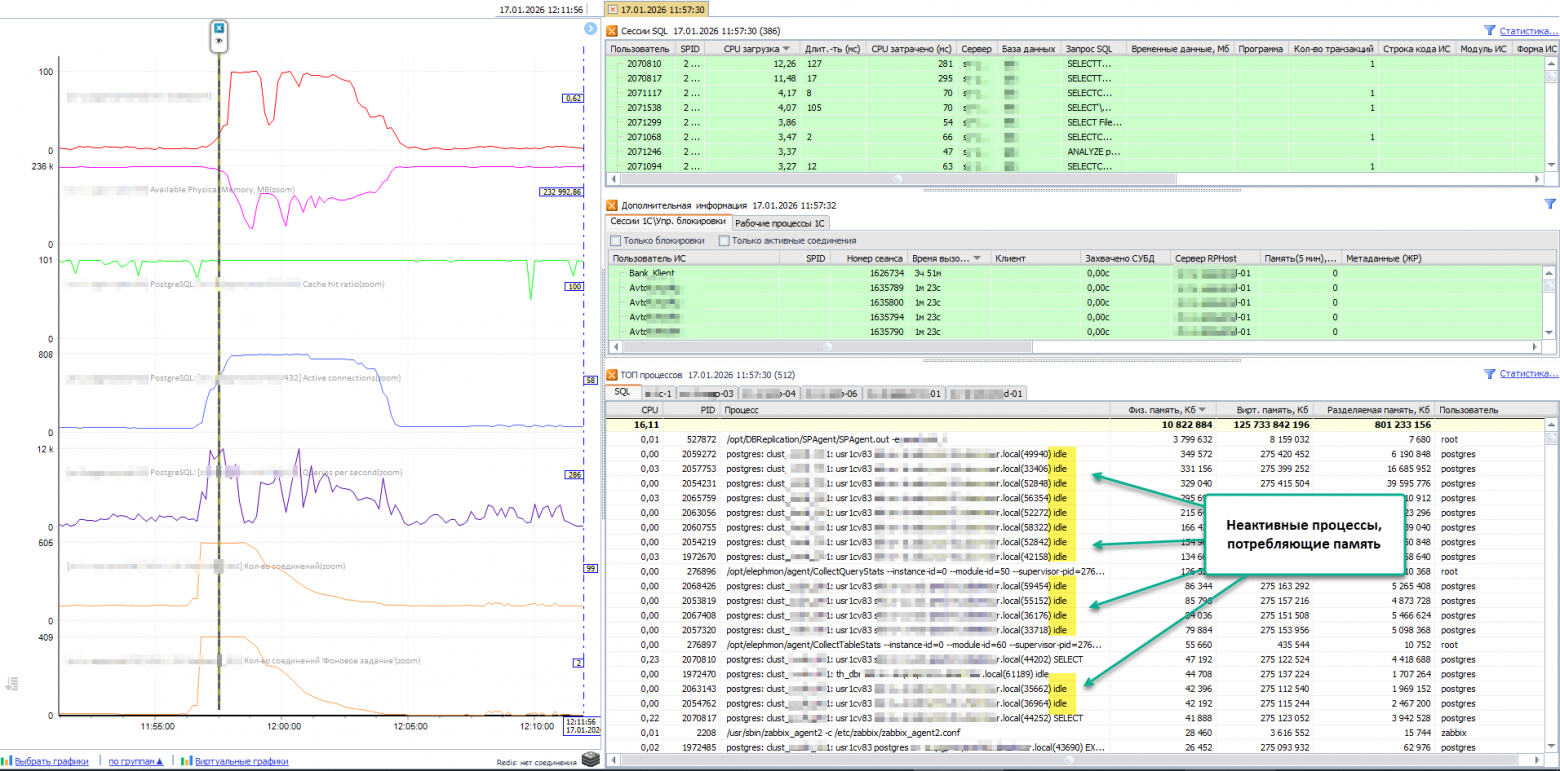
Возьмем из списка для примера два верхних процесса – PID 2057753 и 2059272, и посмотрим на потребление ими оперативной памяти. Для этого в Perfexpert построим виртуальные графики для каждого процесса (PID) – два последних синих графика:
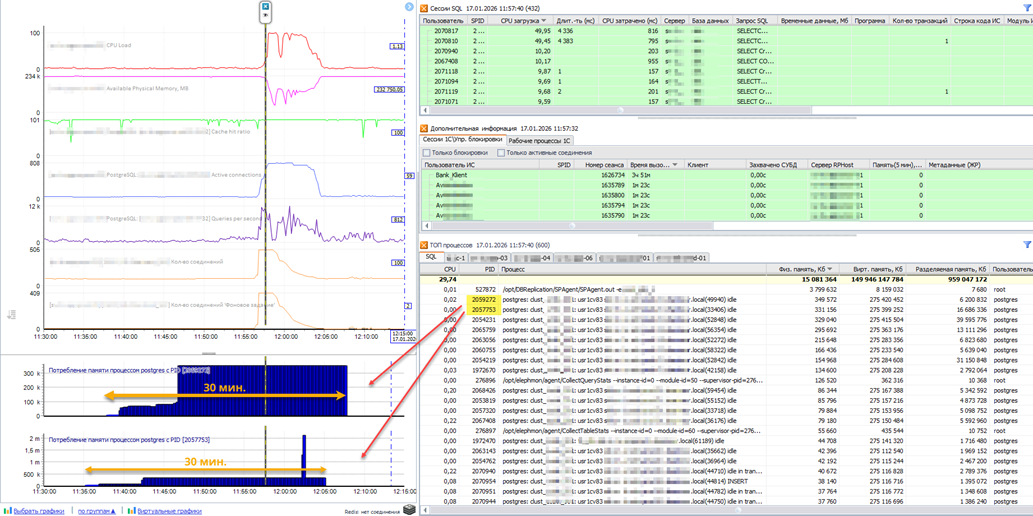
Четко видно, что процессы стартовали задолго до старта фоновых заданий и на протяжении всего времени жизни держат и не отпускают почти постоянный объем памяти. Процесс [2057753] имел непродолжительный всплеск потребления памяти в 12:03, далее память отпустил, но не полностью, а на уровень ~330 Мб.
Причём время жизни таких процессов – не более 30 минут. Т.е. раз в полчаса 1С удаляет старые сессии и создает новые (подробно об этом мы писали в статье Postgres — особенности работы с памятью для 1С-систем. Часть 3).
А теперь посмотрим сколько памяти вообще держится за такими idle-процессами на нашем временном отрезке – самый нижний темно-зеленый график:
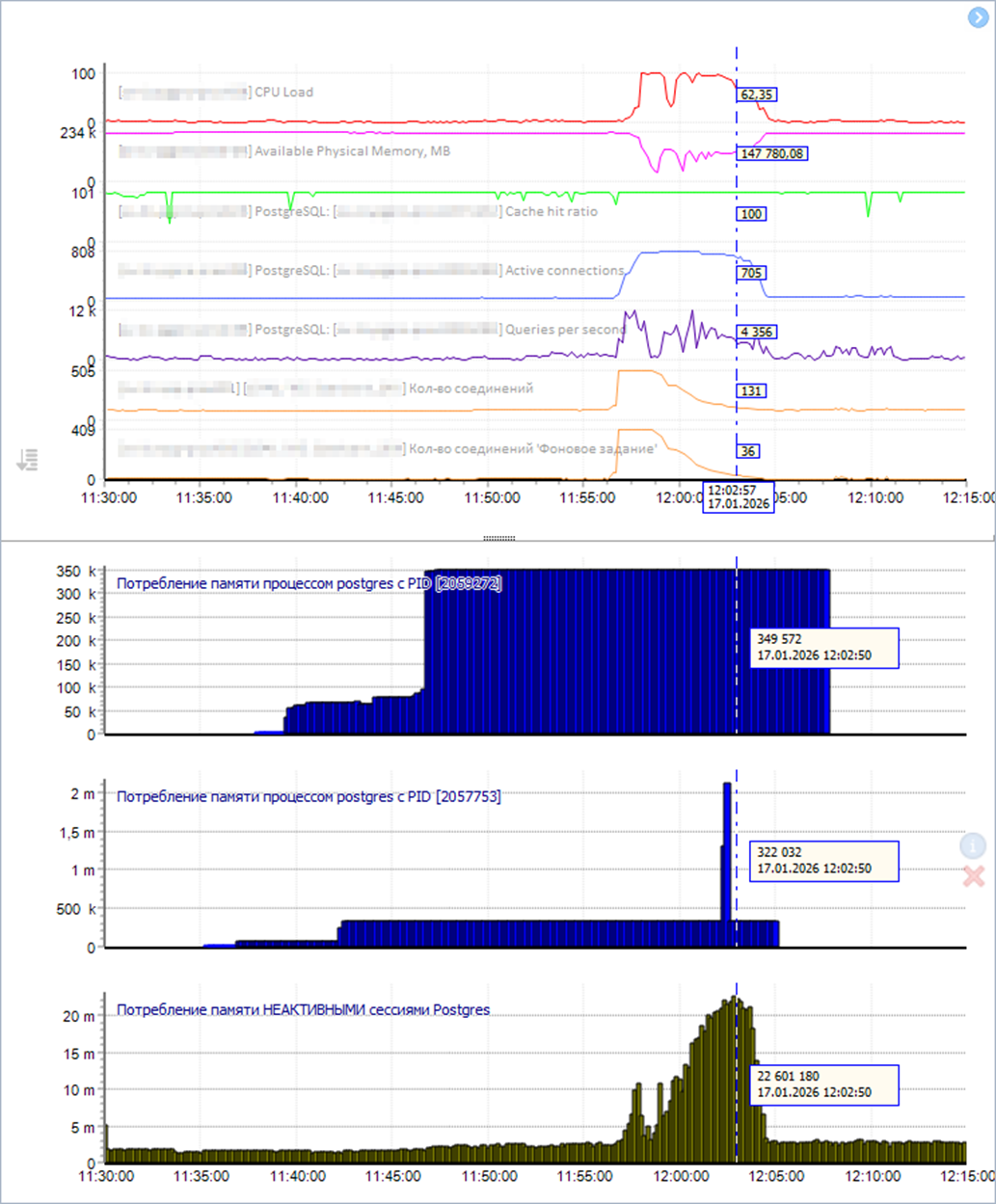
В пике он показывает потребление чуть более 22 Гб. И после окончания фоновых заданий большая часть процессов завершена, но не все, и фоном остается захваченными примерно 3 Гб оперативной памяти.
На нашей практике встречали ситуации, когда в неактивных процессах postgres оставалось не высвобожденными до 100 Гб.
То есть что получается. Если не будет высвобождаться память процессов postgres, то при запуске новых сессий, например, фоновых задач, памяти может банально не хватить.
Причина вроде бы найдена. Но что делать? Интернет говорит разное: и что Postgres должен отдавать память и не должно быть такого поведения, и диаметрально противоположенное. Поэтому решено провести свой чистый эксперимент с высвобождением памяти. На голом PG от разных вендоров, выполняя один и тот же эталонный запрос.
Эксперимент по высвобождению памяти на чистом Postgres
Цель эксперимента: убедиться, что Postgres разных версий и редакций не освобождает или же, наоборот, высвобождает оперативную память в неактивном процессе.
Суть эксперимента: значительно использовать память СУБД, выполнив один и тот же эталонный тяжелый запрос к большой таблице на 10 млн. строк.
Потребление памяти на сервере будет происходить за счет использования запросом памяти work_mem.
Ниже, в следующем разделе, приведено небольшое пояснение по work_mem и дана ссылка на другую нашу статью с уже подробным объяснением что такое пирог памяти, где там в нём work_mem, shared_buffers и др. виды памяти.
Подготовка к эксперименту
Для чистоты эксперимента мы отключили на всех стендах параллелизм max_parallel_workers_per_gather=0 (у некоторых вендоров он включен по умолчанию) и запускали запрос в одном потоке.
Исходные данные стендов:
- виртуальные машины: 4 vCPU, RAM 4 Gb.
- СУБД: ванильная Postgres, а также несколько популярных сборок Postgres на рынке РФ, которые через нас проходили, включая платные версии (порядка 10 СУБД).
- Настройки work_mem: 512 Мб и 1024 Мб.
- Настройки параметров idle_session_timeout и idle_in_transaction_session_timeout везде стоят по умолчанию и равны 0 (то есть отключены).
Создание таблицы 10 млн. строк со случайными данными (время создания 20+ мин.):
CREATE TABLE table1 (column1 TEXT, column2 INT);
DO $$
DECLARE
_id int :=0;
BEGIN
WHILE _id < 10000000 LOOP
INSERT INTO table1 (column1, column2) VALUES (array_to_string(array(
SELECT SUBSTR('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789',((random()*(36-1)+1):: INTEGER),1)
FROM generate_series(1,256)),''), round(random()*100 ));
_id := _id+1;
END LOOP;
END $$;Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)Запрос, который использовался в каждом эксперименте (время выполнения 12-15 сек.):
SELECT t3.* FROM table1 t1
FULL JOIN table1 t2 ON t1.column2=t2.column2
FULL JOIN table1 t3 ON t3.column2=t2.column2
LIMIT 10Code language: PostgreSQL SQL dialect and PL/pgSQL (pgsql)Результаты эксперимента
Результаты замеров сведены в общую таблицу, в которой наименования СУБД обезличены (кроме ванильной) – никого не рекламируем и антирекламу тоже не даём.
Ход эксперимента.
Для каждой СУБД и для каждой настройки work_mem (512 и 1024 Мб) запускали запрос и смотрели потребление памяти в моменте с помощью консоли htop – колонка RES (количество резидентной, фактически используемой памяти).
На любой СУБД запрос выполняется не долго – 10-12 сек и памяти потреблял в пике ~2 Гб. После выполнения запроса сессия оставалось открытой на протяжении нескольких часов, на htop можно отслеживать потребление памяти процессом.
Некоторые СУБД отдавали память сразу же после выполнения запроса, а некоторые оставляли процессу достаточно большие куски памяти до тех пор, пока вручную не закроешь сессию. На некоторых стендах мы оставили висеть неактивную сессию на выходные — ничего не изменилось, автоматически она не сбросилась. Если у кого-то есть информация по причинам такого поведения – напишите, пожалуйста.
Для понимания приведу несколько скринов из htop, которые были сняты после выполнения запроса. Первый – это СУБД от вендора Х, второй – от другого вендора Y, а третий – ванильная PG. СУБД от вендор X не высвободила достаточно большой объем памяти и удерживала его до ручного закрытия сессии, а на втором и третьем скрине память высвобождена.
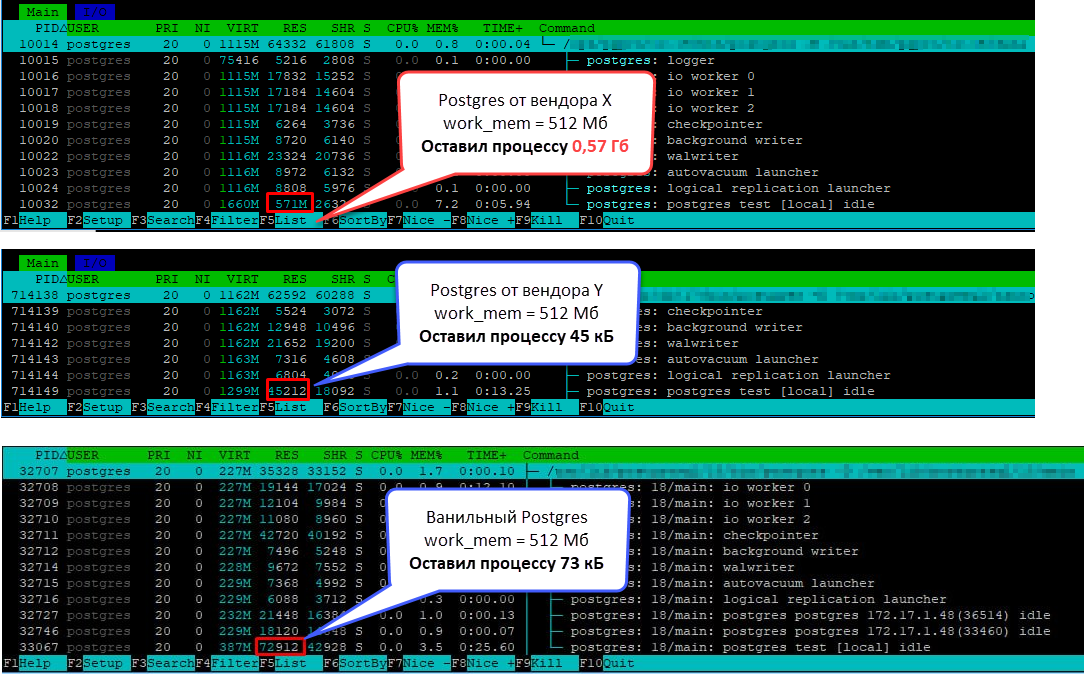
Ну теперь итоговая табличка с замерами. Как сказал выше, вендоры обезличены. Под «вер.1», «вер.2» подразумевается какая-то комбинация версии и/или редакции СУБД.
| СУБД | Объем памяти процесса postgres, Мб | |
| work_mem = 512 Мб | work_mem = 1024 Мб | |
| Postgres 18 ванильная | 0,073 | 0,045 |
| СУБД вендор 1, вер 1 | 571 | 985 |
| СУБД вендор 1, вер 2 | 957 | 1397 |
| СУБД вендор 1, вер 3 | 566 | 1007 |
| СУБД вендор 2, вер 1 | 0,045 | 0,046 |
| СУБД вендор 2, вер 2 | 0,045 | 0,045 |
| СУБД вендор 2, вер 3 | 0,085 | 0,085 |
| СУБД вендор 3, вер 1 | 0,092 | 0,092 |
| СУБД вендор 4, вер 1 | 452 | 1248 |
Получается, что ванильная Postgres, СУБД 2, СУБД 3 память высвобождают после окончания выполнения запроса. Причем сразу. А вот СУБД 1 и СУБД 4 продолжают удерживать некий объем памяти, который еще зависит от параметра work_mem – чем он больше, тем больше удерживаемый объем памяти. Схематично эту ситуацию можно изобразить так:
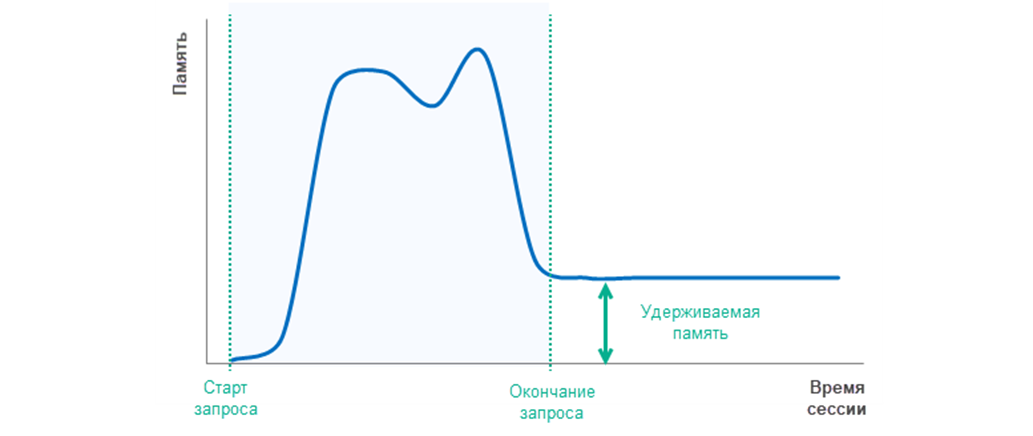
И пока сессия активна, процесс продолжает удерживать этот остаточный объем памяти.
Выводы по эксперименту
Результат, конечно, несколько неожиданный. Некоторые СУБД освобождают память, некоторые нет. Возможно – это баг, а может и фича. Если кто-то знает, поделитесь.
В любом случае следует внимательно наблюдать за потреблением памяти, особенно неактивными процессами. Кроме того, вы можете повторить эксперимент и узнать, как обстоят дела с возвратом памяти на вашей СУБД.
Небольшой ликбез по work_mem
Поскольку именно настройки work_mem влияют непосредственно на потребление памяти запросом и именно этот параметр мы варьировали на эксперименте, то имеет смысл напомнить что это такое и как его настраивать. Про память в Postgres у нас был цикл из трёх статей. Конкретно про work_mem – это часть 2 этого цикла. А сейчас кратко.
work_mem — задаёт базовый максимальный объём памяти, который будет использоваться во внутренних операциях при обработке запросов (например, для сортировки или хеш-таблиц), прежде чем будут задействованы временные файлы на диске. То есть количество памяти выделяется не на запрос, а на операции в запросе, поэтому потребление памяти в запросе может кратно превышать work_mem. Значение по умолчанию — четыре мегабайта (4MB).
В случае нехватки памяти для операций типа JOIN, GROUP BY, ORDER и т.п. запрос записывает данные на диск в темповые данные и работает с диском. Поэтому оценивать нехватку work_mem нужно по двум критериям — использованию темповых данных (Temp data) и использованию физических чтений во время выполнения тяжелых запросов. Если эти критерии совпадают по времени, то значит размер work_mem недостаточен.
С чего начать, устанавливая work_mem? Как сказал выше, по умолчанию – он 4 Мб. Для высоконагруженных БД – это, конечно, совсем мало, но в любом случае настройка work_mem – это итерационный процесс. Для старта(!) можно воспользоваться формулой от вендора 1С: разделить объём доступной памяти (физическая память минус объём, занятый под другие программы и под совместно используемые страницы shared_buffers) на максимальное число одновременно используемых активных соединений. А дальше нужно следить за использованием темповых данных (Temp data) и использованием физических чтений во время выполнения тяжелых запросов.
В общем, повторяться не буду, за подробностями – во вторую часть цикла статей про память в PG. Единственное, что хочу отметить – это частый соблазн сразу выставить большое значение work_mem.
Почему нельзя увеличить слишком сильно work_mem, выставив, например, сразу 20 Гб и ничего не проверять по временным файлам?
Потому что есть два риска:
- Появится сложный запрос, а в 1С это очень вероятно, с большим количеством HASH JOIN, GROUP BY, ORDER и прочее, который съест всю память и приведет к падению PG.
- По мере роста базы данных прежние настройки могут начать работать против вас. Из-за излишне высокого значения work_mem (20 ГБ) запрос, который раньше не требовал много памяти, на увеличенных таблицах может потреблять ее в разы больше. Как следствие, это может спровоцировать падение Postgres.
Ну а маленькое значение work_mem приведет к избыточной нагрузке на диск и увеличению длительности выполнения запросов.
Выводы
- Первое, о чем хочется сказать, что для высоконагруженных систем, такое поведение СУБД очень опасно – при определенных условиях никакой памяти может не хватить. Применительно к данной ситуации, с высоконагруженной и большой 1С-системой, мы сумели оптимизировать проблемные запросы, и они просто стали выполняться быстро с минимальным количеством логических чтений (=низкое потребление памяти). Но сама первопричина осталась и никуда не делась.
- Почему это не очень критично для 1С-систем? Потому что платформа 1С автоматически чистит пулы с сессиями примерно раз в полчаса. Не уверен, есть ли в документации что-то об этом, но для нас это просто эмпирический факт. Если знаете, поделитесь.
- Для кого это критично? Для тех ИТ-систем, где очень трепетно относятся к эффективности использования памяти сервером СУБД.
- Если у вас на сервере 750 Гб и свободно 300 Гб, то скорее всего вам это не критично.
- Если у вас система, в которой создается большое количество сессий, и они долго не пересоздаются, то вы уже в группе риска.
- Если вы боретесь за каждый гигабайт, потраченный впустую, а свободной оперативной памяти (помните тот розовый график на первых скринах?) у вас постоянно в диапазоне 20-30 ГБ, то вот тут нужно всегда держать руку на пульсе.
- Ну и последнее, о чем говорю в каждой первой статье – нужно иметь хорошую и работающую в нужный момент систему мониторинга. Без нее, ну никак.Вот не имеете вы мониторинга. Смогли бы раскрутить эту ситуацию? Хорошо, если удастся связать фоновые задания с падением памяти. Это уже очень здорово. Далее пошли бы к разработчикам 1С и, сказали: «Дорогие наши разработчики 1С, ну зачем же вы запустили утром 100500 фоновых заданий? Сервер и не выдержал, надо бы уменьшать нагрузку». И в моменте это даже поможет, но это не первопричина и через неделю/месяц возникнет похожая ситуация, коих огромное множество! Так что, ставьте мониторинг, настраивайте мониторинг, используйте мониторинг. Он должен работать 24/7.
Ссылки на остальные части Записок оптимизатора 1С:
- Записки оптимизатора 1С (ч.1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
- Записки оптимизатора 1С (ч.2). Полнотекстовый индекс или как быстро искать по подстроке
- Записки оптимизатора 1С (ч.3). Распределенные взаимоблокировки в 1С системах
- Записки оптимизатора 1С (ч.4). Параллелизм в 1С, настройки, ожидания CXPACKET
- Записки оптимизатора 1С (ч.5). Ускорение RLS-запросов в 1С системах
- Записки оптимизатора 1С (ч.6). Логические блокировки MS SQL Server в 1С: Предприятие
- Записки оптимизатора 1С (ч.7). «Нелогичные» блокировки MS SQL для систем 1С предприятия
- Записки оптимизатора 1С (ч.8). Нагрузка на диски сервера БД при работе с 1С. Пора ли делать апгрейд?
- Записки оптимизатора 1С (ч.9). Влияние сетевых интерфейсов на производительность высоконагруженных ИТ-систем
- Записки оптимизатора 1С (ч.10): Как понять, что процессор — основная боль на вашем сервере MS SQL Server?
- Записки оптимизатора 1С (ч.11). Не всегда очевидные проблемы производительности на серверах 1С
- Записки оптимизатора 1С (ч.12). СрезПоследних в 1C: Предприятие на PostgreSQL. Почему же так долго?
- Записки оптимизатора 1С (ч.13). Что не так в журнале регистрации 1С в формате SQLite?
- Записки оптимизатора 1С (ч.14.1). Любите свою базу данных и не забывайте обслуживать
- Записки оптимизатора 1С (ч.14.2). Пересчет индексов на SSD–дисках. Делаем или игнорируем?
- Записки оптимизатора 1С (ч.14.3). Отличия в обслуживании статистик в MS SQL и в PostgreSQL
- Записки оптимизатора 1С (ч.15). Параллелизм запросов 1С в PostgreSQL
- Записки оптимизатора 1С (ч.16). Риски падения Postgres: потребление и высвобождение памяти процессами postgres