Записки оптимизатора 1С (ч.15). Параллелизм запросов 1С в PostgreSQL
Продолжим разбирать тему параллелизма для баз 1С, но сегодня разговор будет не о MS SQL, а о PostgreSQL. Принципы работы тут отличаются, поэтому нужно пояснение.
Что даёт параллелизм и зачем он нужен
Параллелизм позволяет запросу использовать несколько ядер процессора вместо одного, т.е. выполняться в несколько потоков. В идеальном мире запрос, который занимает 10 секунд процессорного времени на одном ядре, на четырёх ядрах выполнился бы за 2,5 секунды. Получается линейное ускорение без изменения кода. Выглядит очень привлекательно.
Как это делается на MSSQL
Подробная статья о параллелизме в MS SQL вышла 2,5 года назад и называлась Записки оптимизатора 1С (ч.4). Параллелизм в 1С, настройки, ожидания CXPACKET. За подробностями туда, а здесь приведу краткие выжимки, которые нам понадобятся для сравнения.
В MS SQL есть две основные ручки: max degree of parallelism (сколько ядер может использовать запрос) и cost threshold for parallelism (стоимость запроса, с которой можно начинать параллелить).
1С рекомендует ставить для всего сервера (базы данных) параметр max degree of parallelism = 1, чтобы избежать, во-первых, неконтролируемого роста нагрузки на CPU, а, во-вторых, роста ожиданий на параллелизме – CXPacket. Но обладая хорошими аппаратными мощностями, будет обидно, если CPU будет частично простаивать, обрабатывая любой запрос лишь в один поток. Поэтому имеет смысл, как минимум, попробовать как у вас взлетит параллелизм, управляя комбинацией «max degree of parallelism» + «cost threshold for parallelism». Это достаточно грубые настройки, но они позволят оценить потенциал вашей базы к параллелизму. Почему грубые? Потому что каждой новой комбинацией либо отсекается пласт запросов, который мог бы распараллелиться (а теперь им запрещено), либо наоборот – разрешается распараллеливаться, хотя делать этого им не стоило, т.к. появились слишком большие ожидания CXPacket и их средняя длительность увеличилась вместо того, чтобы уменьшиться.
Поэтому мы рекомендуем придерживаться одной из двух стратегий, каждая из которых имеет право на жизнь в зависимости от конкретной ситуации. Первая – сначала отключить параллелизм полностью на сервере (MAXDOP = 1), а потом точечно включать для отдельных запросов, которым это реально нужно. Вторая стратегия – включить параллелизм для всего сервера (базы данных), а затем точечно запрещать распараллеливаться тем запросам, у которых издержки на параллелизм превышают эффект от распараллеливания (большие ожидания CXpacket). Выбор стратегии зависит от железа и профиля нагрузки. Всё индивидуально. Но в любом случае для таких точечных «запретов» и «разрешений» используется программа QProcessing, чтобы определенным запросам устанавливать хинты MAXDOP. Ну а с помощью мониторинга Perfexpert контролируется динамика изменения профиля нагрузки и эффект на каждом шаге.
В PostgreSQL всё немного иначе
PostgreSQL не использует потоки внутри одного процесса, как это делает MS SQL. Вместо этого он использует модель «один процесс – один запрос», а параллелизм реализуется через несколько полноценных процессов (свой SPID и т.п.) операционной системы. Когда оптимизатор решает, что запрос можно выполнять параллельно, основной процесс клиента становится лидером выполнения, а дополнительные процессы запускаются как parallel workers. Все они существуют одновременно, имеют собственные контексты выполнения и взаимодействуют между собой через динамическую разделяемую память. Т.е. каждый воркер берёт свою часть данных, обрабатывает её, а результаты собирает координатор (лидер-процесс) через узел Gather или Gather Merge.
Но это еще не всё. Параллелизм включается не просто «для запроса», а для конкретных операций в плане: последовательное сканирование таблицы (Seq Scan), соединения (Join) и агрегации. И настраивается это через несколько параметров.
Выгода от использования параллелизма чаще всего проявляется на тяжелых операциях, когда есть что делить на потоки:
- сканирование больших таблиц (Seq Scan)
- агрегации (SUM, COUNT, AVG) по миллионам строк
- тяжёлые соединения (Hash Join, Merge Join)
Пройдемся немного по глобальным параметрам, чтобы понимать их количество и вариативность.
| Параметр | По умолчанию | Описание |
|---|---|---|
| max_worker_processes | 8 | Максимальное число всех фоновых процессов (включая параллельных воркеров, но и не только их) |
| max_parallel_workers | 8 | Максимальное число воркеров на всём сервере, которые могут одновременно работать на параллельных запросах. Обычно рекомендуется не более половины ядер CPU. |
| max_parallel_workers_per_gather | 2 | Максимальное число воркеров для одного узла Gather. Это ключевой параметр, определяет сколько воркеров может получить один запрос. Значение 0 = параллелизм выключен. |
| max_parallel_maintenance_workers | 2 | Максимальное число воркеров для обслуживающих операций: CREATE INDEX, VACUUM |
| parallel_setup_cost | 1000 | Оценочная стоимость запуска каждого воркера. Чем выше, тем реже планировщик выбирает параллельный план. |
| parallel_tuple_cost | 0.1 | Стоимость передачи одного кортежа от воркера к лидеру через Gather |
| min_parallel_table_scan_size | 8MB | Таблицы меньше этого размера не будут сканироваться параллельно |
| min_parallel_index_scan_size | 512kB | То же для индексов. |
| parallel_leader_participation | ON | Лидер-процесс тоже обрабатывает данные, а не только координирует. Обычно это хорошо, выключать не стоит. |
Планировщик PostgreSQL вычисляет количество воркеров для последовательного сканирования таблицы по логарифмической шкале: каждое трёхкратное увеличение размера таблицы сверх min_parallel_table_scan_size добавляет одного воркера (но не более max_parallel_workers_per_gather).
Важное ключевое различие между MS SQL Server и PostgreSQL заключается в механизмах контроля ресурсов. В MS SQL Server количество потоков для одного запроса в принципе может быть не ограничено – параметр max degree of parallelism при значении 0 позволяет одному запросу захватить все доступные ядра процессора. Это создаёт реальный риск и один неоптимальный запрос может полностью утилизировать CPU, резко ухудшив отклик остальных запросов, т.е. фактически «положить» сервер, забрав все вычислительные ресурсы.
В PostgreSQL архитектура параллелизма принципиально иная: число воркеров ограничивается и «на запрос» (max_parallel_workers_per_gather), и «на весь сервер» (max_parallel_workers), плюс есть лимит на общее число процессов (max_worker_processes). Эти параметры выступают в роли предохранителей – один запрос не может потребить ресурсов больше, чем разрешено этими лимитами. Да, в части настроек это выглядит на первый взгляд сложнее, чем в MS SQL, но зато можно не опасаться, что единичная операция обрушит производительность всей системы. Видя реальные свободные ресурсы CPU, можно осознанно подбирать под них настройки для параллельных планов запросов.
Стратегия для систем 1С под PostgreSQL
Здесь, пожалуй, можно провести параллель с MS SQL : «Главное – не навредить». Меняя глобальные настройки, вы проводите достаточно агрессивную параллелизацию, и многие запросы могут от нее пострадать, т.к. издержки на параллелизм превышают (часто даже очень) сам эффект от распараллеливания. Но это не значит, что не стоит пробовать. Просто на высоконагруженных системах, назовем их «Большие 1С», риск получить просадку по производительности очень велик.
Поскольку 1С сама генерирует SQL, и мы не можем вставить хинт в произвольный запрос, то наиболее работоспособная стратегия аналогична подходу для MS SQL, с учётом архитектурных особенностей PostgreSQL, но с использованием дополнительного ПО – прокси-сервера QProcessing:
- Начальная настройка. Параметр max_parallel_workers_per_gather устанавливается в 0. Это полностью отключает параллельное выполнение запросов. Система становится предсказуемой, исключаются ситуации неконтролируемого потребления процессорных ресурсов.
- Выявление кандидатов. Анализируются длительные запросы. Особое внимание уделяется запросам с последовательным сканированием больших таблиц, не работающим в транзакциях – как правило, это отчёты или регламентные задания. Для анализа используем мониторинг Perfexpert, который собирает трассы тяжелых и длительных запросов.
- Точечное включение. Для отобранных запросов параллелизм активируется с помощью хинтов. В PostgreSQL для этого используется расширение pg_hint_plan, которое позволяет добавлять указания оптимизатору непосредственно в текст запроса. Само добавление хинта осуществляется с помощью программы QProcessing, представляющей собой прокси-сервер – пропускает через себя весь трафик sql-запросов и реагирует только на определенные, соответствующие заданным правилам.
Пример добавленного хинта:/*+ Parallel(t1 4 hard) */, где t1 – алиас таблицы, 4 – желаемое число воркеров, hard – режим «жесткого» требования параллелизма, при котором оптимизатор игнорирует стандартные оценки стоимости и использует столько воркеров, сколько указано. - Оценка эффективности. Сравнивается время выполнения запроса до и после включения параллелизма. Если ускорение стабильно и не приводит к деградации других операций, где может использоваться этот же запрос, хинт сохраняется. Мы для сравнения используем мониторинг Perfexpert, который собирает трассы тяжелых и длительных запросов и позволяет сравнить картину ДО и ПОСЛЕ включения параллелизма.
Практический пример
Рассмотрим реальный запрос из Большой 1С. Запрос был отобран у заказчика в ходе работ по оптимизации тяжелых запросов. Запрос в меру частый – выполняется ~150 раз в сутки. Средняя длительность 14..16 сек, возвращает всегда одну строку и при этом делает ~1 млн. логических чтений.
Текст запроса:
SELECT
T1._IDRRef
FROM _Document1065 T1
LEFT OUTER JOIN _Document1389 T2
ON (T1._Fld22435_TYPE = '\010'::bytea
AND T1._Fld22435_RTRef = '\000\000\005m'::bytea
AND T1._Fld22435_RRRef = T2._IDRRef)
AND (T2._Fld2507 = CAST(0 AS NUMERIC))
WHERE (T1._Fld2507 = CAST(0 AS NUMERIC))
AND (
(T1._Fld22435_TYPE = '\010'::bytea
AND T1._Fld22435_RTRef = '\000\000\004\302'::bytea
AND T1._Fld22435_RRRef = '<uuid>'::bytea)
OR ((CASE WHEN T2._Fld37840_TYPE = '\010'::bytea
AND T2._Fld37840_RTRef = '\000\000\004\302'::bytea
THEN T2._Fld37840_RRRef END) = '<uuid>'::bytea)
AND T1._Posted = TRUE
AND (T1._Marked = FALSE)
);Code language: PHP (php)Ниже на рисунке трасса этих запросов за один день.
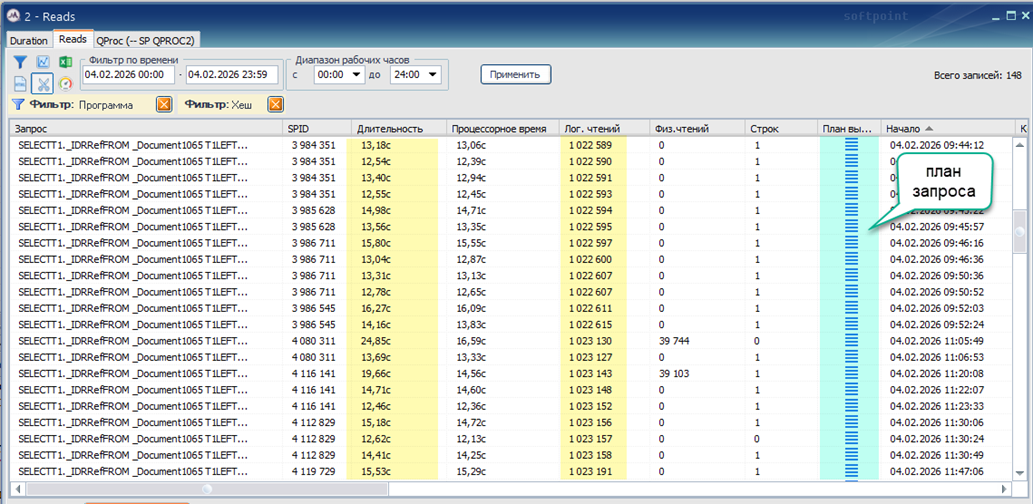
Статистика по таблицам из запроса:
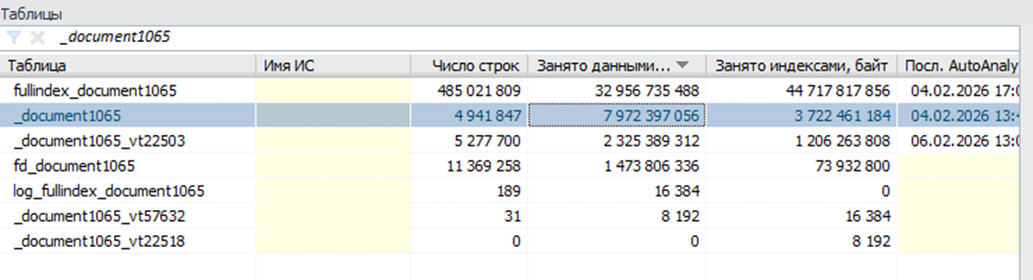

В запросе выбираются ссылки из таблицы Document1065 (почти 5 миллионов записей) с LEFT JOIN к таблице Document1389 (3,7 млн. записей). Условия включают проверки полей составного типа (TYPE, RTRef, RRRef). Запрос возвращает всего одну строку, но из-за формы условия (OR + ссылка на T2 через CASE) планировщик часто вынужден читать и фильтровать большие объемы данных, а это как раз то место, где параллельный скан и параллельные джойны могут дать выигрыш.
Откроем план какого-нибудь запроса из трассы:
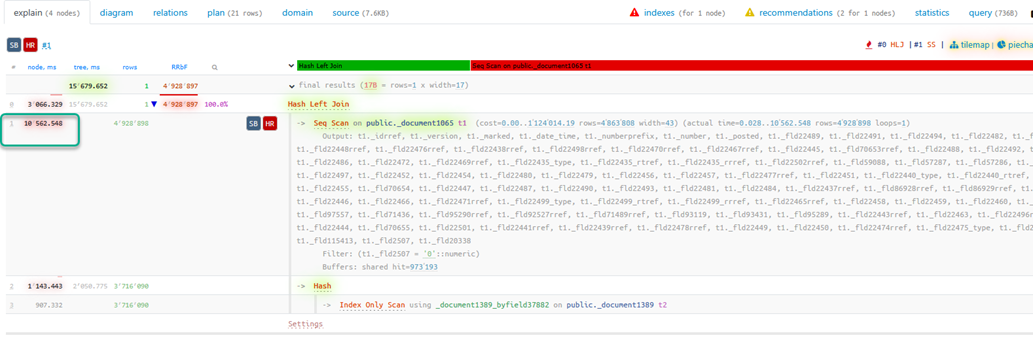
При длительности запроса 15,6 сек. основная часть времени (10,5 сек.) была потрачена на последовательное сканирование таблицы Document1065 (Seq Scan) с фильтром по полю Fld2507 = 0. Поскольку условие неселективное (подходят практически все строки), индекс не используется. Сканирование обрабатывает 4 928 898 строк.
Теперь добавим параллелизм этому запросу.
В трассе прекрасно виден «водораздел», когда запросы начали распараллеливаться (примерно в 12:00 было включено правило в QProcessing на данный вид запросов) и длительность запросов сократилась в разы.
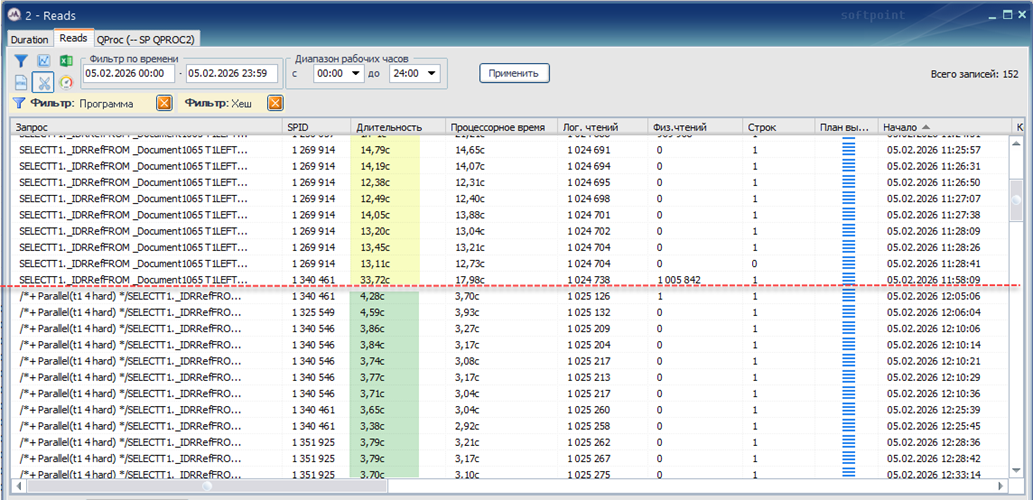
Никакие настройки PG тоже не изменились, лишь добавился хинт в текст запроса:
/*+ Parallel(t1 4 hard) */
SELECT
T1._IDRRef
FROM _Document1065 T1
LEFT OUTER JOIN _Document1389
…Code language: CSS (css)Посмотрим на новый план:
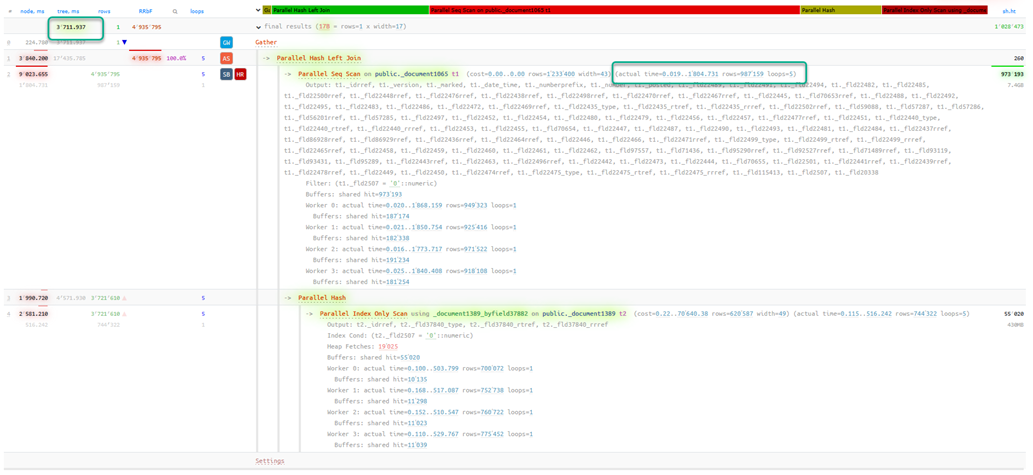
Ключевые изменения в плане:
- Появился узел Gather для координации работы параллельных воркеров.
- Последовательное сканирование _Document1065 выполняется параллельно четырьмя воркерами. Каждый обрабатывает свой диапазон строк (от 918 до 971 тысячи строк на воркер).
Суммарная длительность (по всем воркерам) теперь составляет ~1,8 сек. - Индексное сканирование _Document1389 также выполняется с поддержкой параллелизма, каждый воркер строит свою часть хеш-таблицы.
Общая длительность: 3,71 сек.
Результат отличный — запрос получил линейное ускорение ~4 раза. Таким образом можно точечно пройтись по многим другим запросам, которые имеют хорошие перспективы для распараллеливания.
Выводы
Не все запросы демонстрируют подобную эффективность при параллельном выполнении. Сложные запросы с множественными соединениями или агрегациями могут показывать худшие результаты из-за конкуренции за ресурсы и увеличения накладных расходов на синхронизацию. Кроме того, параллелизм неэффективен для коротких запросов — затраты на запуск воркеров могут превысить выигрыш от распараллеливания.
В системах 1С наиболее перспективны для распараллеливания:
- Тяжелые отчетные запросы/обработки, выполняющие сканирование больших таблиц регистров (оборотно-сальдовая ведомость, закрытие месяца и т.п.).
- Обработки данных, работающие вне транзакций.
- Запросы с фильтрацией по неселективным условиям (где индексы бесполезны).
Этой статьей я хотел показать, что параллелизм в PostgreSQL – это мощный инструмент для получения линейного прироста скорости по многим операциям, но требует аккуратного обращения (впрочем, как и в MS SQL). Общая рекомендация отключать параллелизм в продуктивных системах 1С является разумной стратегией по умолчанию, позволяющей избежать непредсказуемого поведения. Однако полный отказ от параллельных запросов может означать потерю значительного потенциала производительности. Особенно это важно и обидно в высоконагруженных 1С, в которых, наверняка, заложены и используются хорошие аппаратные мощности.
Ключевым фактором успеха становится системный подход – качественный анализ по выявлению запросов-кандидатов и точечное включение параллелизма для некоторых из них. Такой подход исключает риски неконтролируемой просадки производительности всей системы, и в то же время гарантирует увеличение скорости выполнения отдельных операций. Да, он небыстрый, итерационный, но надежный.
Ссылки на остальные части Записок оптимизатора 1С:
- Записки оптимизатора 1С (ч.1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
- Записки оптимизатора 1С (ч.2). Полнотекстовый индекс или как быстро искать по подстроке
- Записки оптимизатора 1С (ч.3). Распределенные взаимоблокировки в 1С системах
- Записки оптимизатора 1С (ч.4). Параллелизм в 1С, настройки, ожидания CXPACKET
- Записки оптимизатора 1С (ч.5). Ускорение RLS-запросов в 1С системах
- Записки оптимизатора 1С (ч.6). Логические блокировки MS SQL Server в 1С: Предприятие
- Записки оптимизатора 1С (ч.7). «Нелогичные» блокировки MS SQL для систем 1С предприятия
- Записки оптимизатора 1С (ч.8). Нагрузка на диски сервера БД при работе с 1С. Пора ли делать апгрейд?
- Записки оптимизатора 1С (ч.9). Влияние сетевых интерфейсов на производительность высоконагруженных ИТ-систем
- Записки оптимизатора 1С (ч.10): Как понять, что процессор — основная боль на вашем сервере MS SQL Server?
- Записки оптимизатора 1С (ч.11). Не всегда очевидные проблемы производительности на серверах 1С
- Записки оптимизатора 1С (ч.12). СрезПоследних в 1C: Предприятие на PostgreSQL. Почему же так долго?
- Записки оптимизатора 1С (ч.13). Что не так в журнале регистрации 1С в формате SQLite?
- Записки оптимизатора 1С (ч.14.1). Любите свою базу данных и не забывайте обслуживать
- Записки оптимизатора 1С (ч.14.2). Пересчет индексов на SSD–дисках. Делаем или игнорируем?
- Записки оптимизатора 1С (ч.14.3). Отличия в обслуживании статистик в MS SQL и в PostgreSQL
- Записки оптимизатора 1С (ч.15). Параллелизм запросов 1С в PostgreSQL