Записки оптимизатора 1С (часть 1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
Вступление
Этой статьей мы начинаем цикл разбора нетривиальных случаев в нашей практике оптимизации производительности ИТ-систем. Возможно, кому-то они пригодятся, так как решения будут нестандартные. Возможно, кто-то узнает свою ситуацию и поделится своими решениями или наведет на интересную мысль. Ведь, коллективный разум – это сила!
Не секрет, что самой популярной и массовой платформой в России для создания ИТ-систем для бизнеса является 1С:Предприятие 8.х. На ней разработано огромное количество отраслевых и самописных решений.
Хочу обратить внимание на одну интересную особенность работы приложений 1С, а именно, очень интенсивную работу с временными таблицами СУБД. Подобной интенсивной работы с tempDB, наверное, нет ни в одном тиражном решении в мире.
С точки зрения кода 1С создание временной таблицы выполняется командой ПОМЕСТИТЬ – менеджер временных таблиц (МВТ) создается не явно и MS SQL создает локальную временную таблицу с одной решеткой (#), например, #tt60. После завершения пакетного запроса неявный МВТ закрывается, платформа автоматически удаляет временную таблицу, отдавая серверу СУБД команду <truncate table>, чтобы освободить ресурсы под следующий запрос:
TRUNCATE TABLE #tt60
TRUNCATE – это крайне простая и быстрая операция. Даже для таблиц с миллионами строк она длится миллисекунды. Тем не менее, у некоторых своих клиентов мы столкнулись с очень странной ситуацией, когда производительность системы проседает из-за того, что запросы с очисткой временных таблиц могут длиться 5, 10, 20 и более секунд (не миллисекунд, а секунд!). А учитывая масштаб запросов с временными таблицами в ИТ-системе на 1С, это время в совокупности становится просто огромным. А поскольку техподдержка Microsoft для российских пользователей фактически закрыта, то они (пользователи) остаются с проблемой один на один.
Проблематика: немного цифр
Как я сказал выше, проблема наблюдается далеко не у всех. Более того, среди тех, у кого она есть, о ней могут и не знать вовсе. Проблема может быть очень незаметная, отъедающая единицы процентов ресурсов CPU. Замечают ее только очень внимательные сотрудники, которые своими изысканиями вышли как-то на tempDB, записали трассу в профайлере SQL и наткнулись на странные цифры длительности запросов с TRUNCATE.
А есть, наоборот, очень яркие примеры, где доля потребления ресурсов CPU составляет уже несколько десятков процентов! Такими примерами и займемся. Для анализа используем программу мониторинга PerfExpert, собирающую различные данные 24/7.
Возьмем для примера данные за одну календарную неделю по трассе Duration у одного нашего заказчика. В трассу попадают все запросы длительностью более 5 секунд. На рисунке ниже представлены данные, сгруппированные по типу запроса и отсортированные по доле потребления CPU.
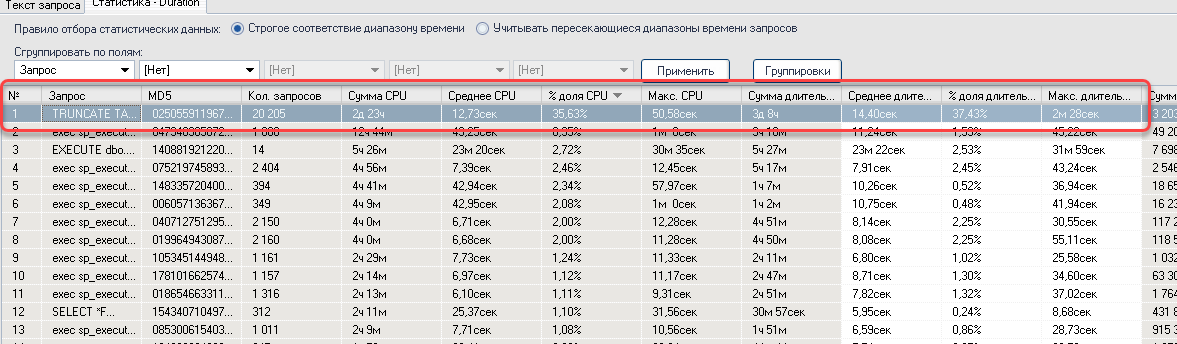
И что мы видим? Запрос типа TRUNCATE TABLE #TT оказался на первом месте по потреблению CPU. Всего таких запросов чуть более 20 тысяч, отъевших процессорного времени на почти 3 дня (колонка Сумма CPU). Еще раз акцентирую внимание, что в мониторинге Perfexpert собираются данные только по запросам длительностью более 5 секунд. А фактически, их гораздо больше. Так что, три дня процессорного времени – это даже не нижняя граница. В любом случае, стоит побороться за такие цифры паразитивной нагрузки на CPU.
Далее хочу обратить ваше внимание еще на два интересных факта.
Возьмем другую высоконагруженную базу данных, во-первых, чтобы показать, что проблема не единична и ее масштаб схож, а, во-вторых, показать, что клиент пытается на своем уровне как-то бороться с ней. Берем опять одну календарную неделю и группируем все запросы Truncate по дням.

Обратите внимание на колонки Сумма CPU и Сумма длительность. Значения в них почти равные. Например, 19 февраля было зафиксировано ~5 тыс. запросов Truncate длительностью более 5 секунд, и они заняли 10ч 41мин. процессорного времени и почти столько же была их общая длительность – 10ч 55мин.
Это очень важный момент. Равенство данных величин указывает на то, что длительность запросов вызвана не блокировками, не какой-то задержкой со стороны сервера приложений, а процессором на сервере СУБД. Который каждый раз что-то вычислял, и на каждый запрос в среднем в этот день тратил по 7-8 секунд (в максимуме до 46 сек).
Что за сложные вычисления могут быть в команде TRUNCATE? Не понятно и попахивает конспирологией.
Также стоит отметить тот факт, что после перезагрузки сервера СУБД 16 февраля (оранжевая горизонтальная линия на рисунке выше) кол-во длительных TRUNCATE сразу снизилось, но потом постепенно поднялось до исходных значений в 4-5 тыс. в сутки. Этот эффект повторялся каждый раз после перезагрузки сервера. Т.е. наблюдается какой-то накопительный эффект с не очень ясными условиями накопления.
Сама по себе проблема плавающая, наблюдается далеко не у всех. Вероятно, зависит от какой-то характерной последовательности запросов и их интенсивности. Смоделировать её так, чтобы задержка вызывалась именно процессорным временем, на синтетических тестах в полной мере пока не удалось. Вопросов больше, чем ответов.
Сведу в единый список проблемы и наблюдения по разным экспериментам.
- Простейшая команда TRUNCATE выполняется непозволительно долго (иногда 40+ сек) на сервере СУБД, что может дать значительную просадку производительности всей системы, учитывая огромное количество запросов с временными таблицами. Это, собственно, основная проблема из-за которой вся статья и написана.
- Проблема длительных TRUNCATE наблюдается только на MS SQL Server 2019. На более ранних версиях такого не было – собственноручно наблюдали появление проблемы у клиентов именно после перехода на MS SQL Server 2019. Про более свежие версии пока трудно сказать – статистики не хватает.
- Проблема временно рассасывается после перезагрузки сервера SQL, но достаточно быстро (до двух дней) возвращается в исходное состояние.
- Время выполнения запроса обусловлено процессорным временем на MS SQL Server. Что само по себе очень подозрительно!
- Количество строк во временной таблице не влияет на время выполнения запроса TRUNCATE TABLE.
- Проблему не удалось смоделировать синтетическими тестами (как запросами из кода 1С, так и напрямую скриптами на СУБД), в которых временные таблицы создаются, заполняются и очищаются с разной интенсивностью и с разным количеством строк.
Как мы обходили проблему длительных Truncate
В сложившейся ситуации Microsoft фактически не оказывает поддержку клиентам из России. Все вопросы в техподдержку остаются без ответов. А поскольку столь интенсивная работа с tempDB характерна именно для российских систем на 1С:Предприятие, то ожидать в ближайшем будущем Service Pack’ов по данной проблеме не приходится. Пока предлагаю оставить за скобками всякие конспирологические теории и будем рассматривать проблему как ошибку в работе СУБД.
Чем можно заменить Truncate?
Вариант 1: DELETE

Операция DELETE также сохраняет первоначальную структуру таблицы, но при этом логируется и на нее можно накладывать условия. В принципе, тоже достаточно быстрая операция, особенно если не накладывать условий. Но тем не менее, не настолько быстрая, как хотелось бы – таблица очищается построчно. Чем больше строк, тем дольше удаление.
Суть тестирования была в подмене строк запроса
TRUNCATE TABLE #tt<номер>Code language: HTML, XML (xml)на
DELETE FROM #tt<номер>Code language: HTML, XML (xml)Как и каким инструментом мы производили подмену опишу чуть ниже, чтобы не отвлекаться от хода эксперимента. Просто пока примите за факт, что это возможно, даже в связке 1C сервер + SQL Server.
В результате первого прогона мы получили кучу пользовательских ошибок. Почти каждый пользователь сразу при открытии 1С:Предприятие получал вот такое замечательное сообщение:
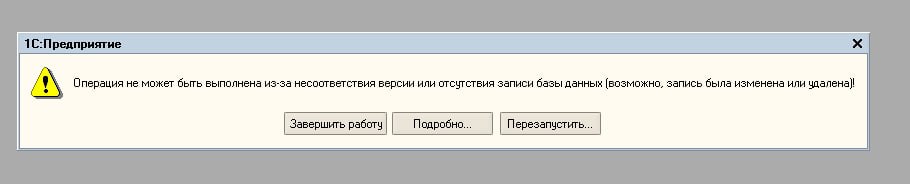
Сразу же появилась мысль, что 1С просто не ожидает, что сервер SQL будет возвращать какую-то информацию о количестве строк и надо добавить в подменный запрос конструкцию SET NOCOUNT ON , чтобы приложение не получало ничего лишнего. На выходе получилось:
SET NOCOUNT ON
DELETE FROM #tt<номер>Code language: HTML, XML (xml)После подмены и при средней интенсивности запросов TRUNCATE 7…10 тысяч в минуту мы наблюдали в мониторинге резкий рост количества всех sql-запросов в 4-5 раз, а также потребления ресурсов CPU на сервере приложений 1С и на сервере СУБД. В течение буквально пары минут оба сервера ушли «в банку» и потребовалось срочно отключать правило подмены и возвращать всё как было.
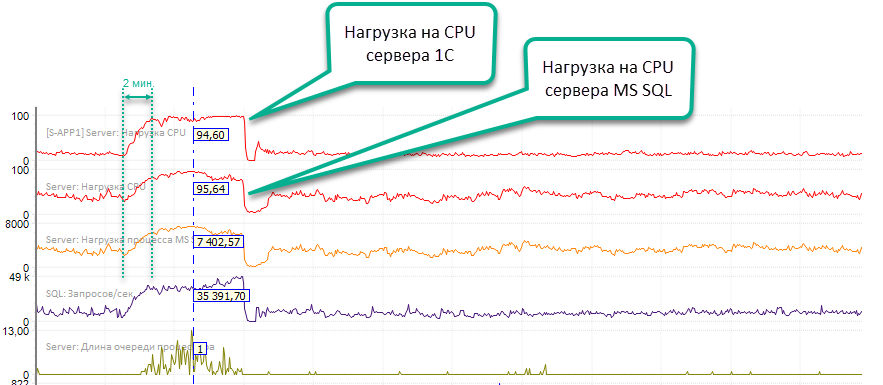
Ну что тут сказать. Это был epic fail. Какие-то мысли крутились в голове, но никак не хотели сформироваться во что-то прикладное. Кто догадался – молодец, читаем дальше, не надо сразу бросаться писать комментарии типа «Ну это задача для первоклассника», «Это ж очевидно» и т.п.
На тот момент мы не поняли сразу причину и пошли думать в другую сторону, отбросив вариант с <DELETE> как ущербный.
Вариант 2: DROP TABLE
Данная команда удаляет уже таблицу целиком, а не записи в ней. Поэтому подмена в запросе будет более сложная: копируем структуру исходной таблицы в промежуточную, удаляем исходную и переименовываем вторую таблицу в исходную.
Причем, к этому моменту мы догадались в чем же был косяк с DELETE, и обернули наш подменный запрос в конструкцию <SET NOCOUNT ON … SET NOCOUNT OFF>, чтобы не было ситуации как в предыдущем варианте.
Таким образом одна строчка TRUNCATE TABLE #tt60 превращается в шесть:
SET NOCOUNT ON
SELECT Top 0 * into #tt60_temp from #tt60
DROP TABLE #tt60
SELECT Top 0 * into #tt60 from #tt60_temp
DROP TABLE #tt60_temp
SET NOCOUNT OFFCode language: CSS (css)Мониторинг Perfexpert позволяет собирать свою произвольную трассу запросов по текстовой маске – TextMask. Мы запустили сбор всех подмененных запросов по разным правилам. Сейчас нас интересуют запросы DROP, и на рисунке ниже представлен скрин трассы, записи которой отфильтрованы по вхождению «DROP TABLE #tt».
По началу все шло нормально, но постепенно (примерно за 1 час) длительность новых запросов возрастала все больше и дошла до полутора минут. Система встала колом – появились блокировки, основные запросы перестали выполняться, пользователи расстроились.
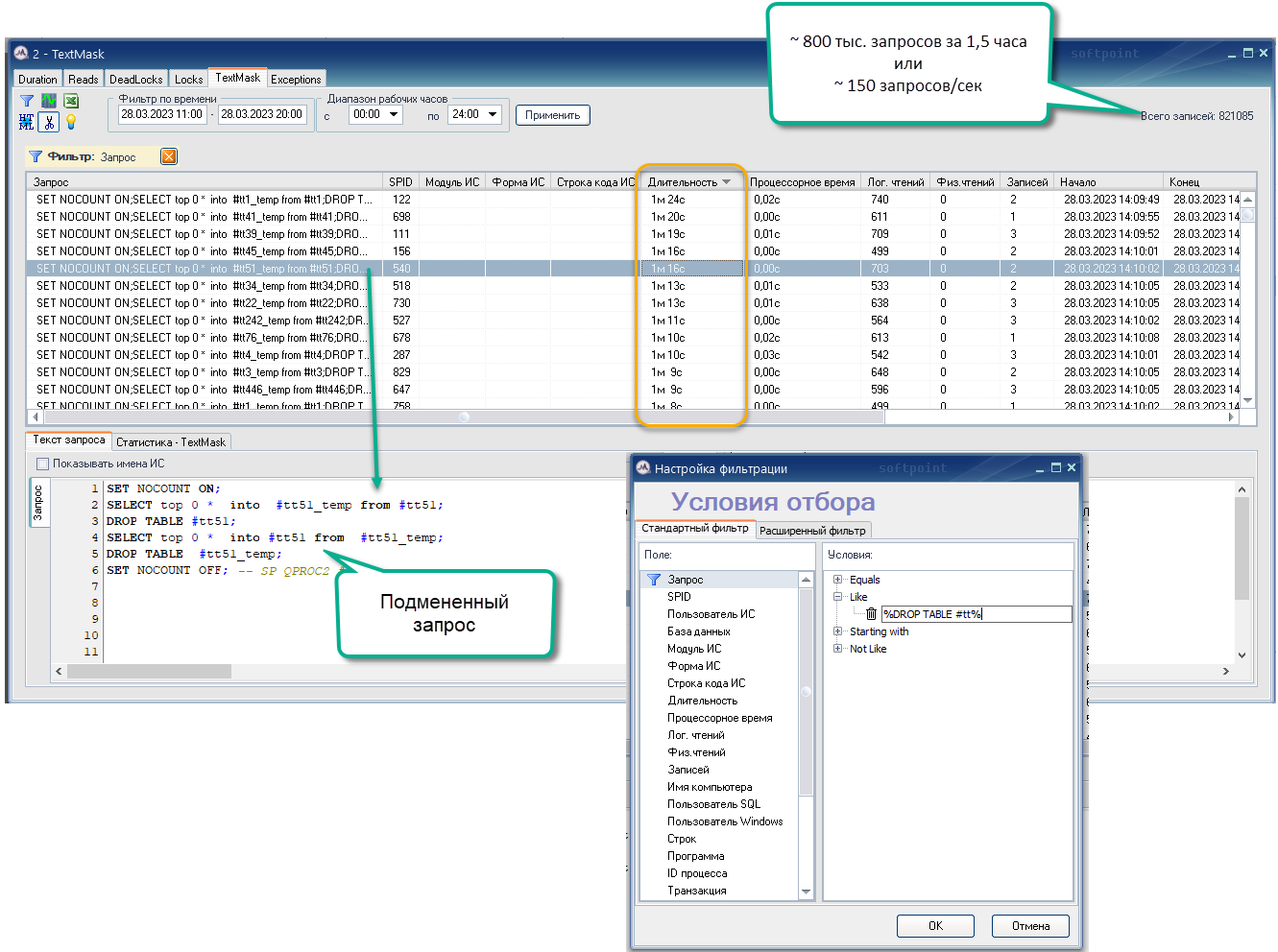
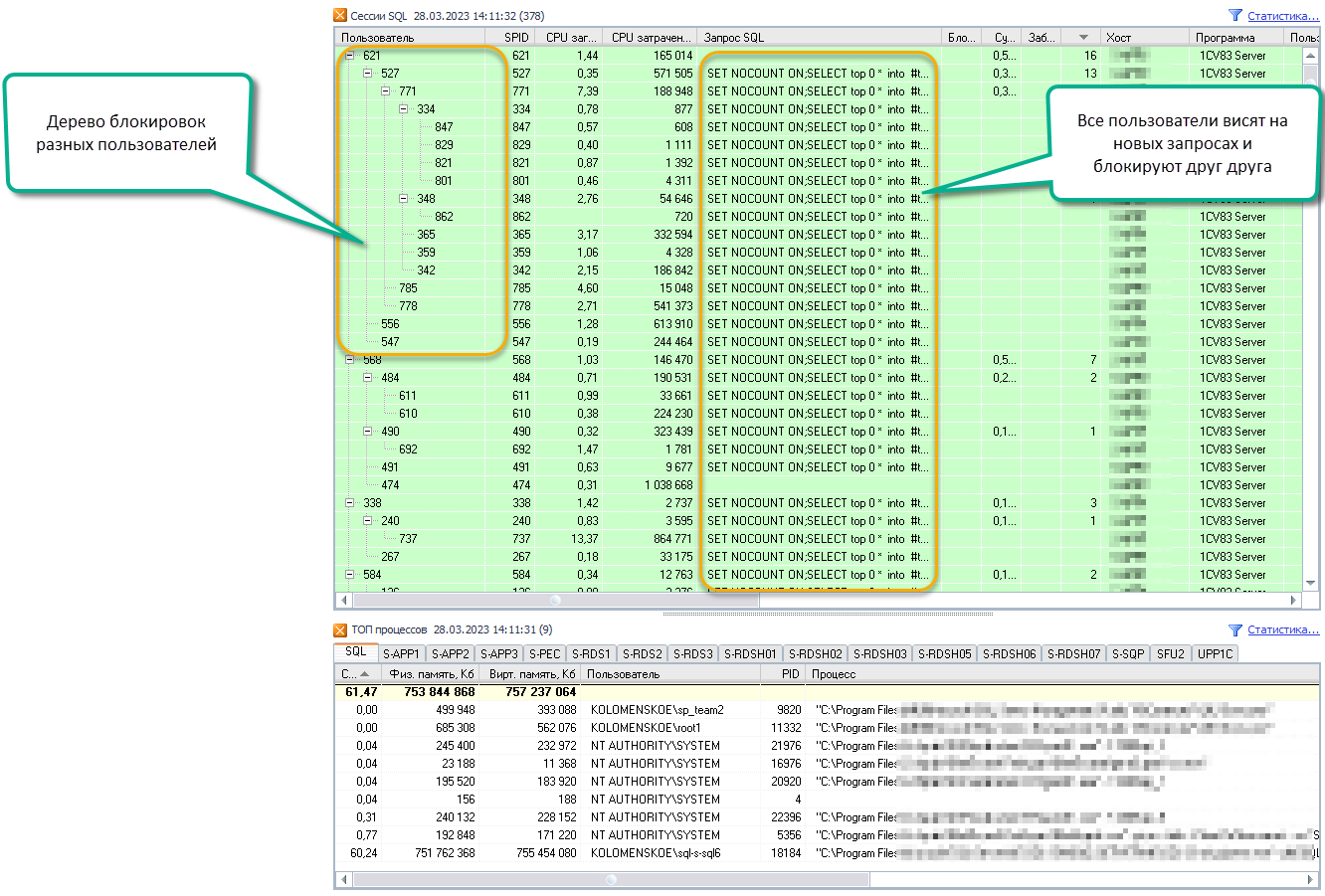
Судя по дереву блокировок, узким местом стала системная таблица в базе tempDB. Это и логично – с учетом интенсивности TRUNCATE (сотни в секунду) такое количество пересозданий таблиц и такую интенсивность база tempDB не выдерживает. Причем, ситуация развивалась постепенно, не лавинообразно. SQL Server зависал на какой-то строчке нового запроса и, скорее всего, это была команда создания новых временных таблиц:
SELECT Top 0 * into #tt60_temp from #tt60Code language: CSS (css)По итогам пришлось правило отключить, т.к. деградация длительности удаления была очевидна и весьма динамична. Вариант с DROP ничего нам не дал, и мы остались с тем же, с чего начали.
Вариант 3: DELETE в комбинации с TRUNCATE

Почему вариант c DELETE нам не зашел в прошлый раз? Во-первых, из-за отсутствия конструкции SET NOCOUNT OFF. Во-вторых, в DELETE удаление данных из таблицы производится построчно. Даже без условия. Поэтому, как только попадалась таблица с большим количеством строк (сотни тысяч и миллионы), то процесс очищения таблицы становился катастрофически длинным и ресурсозатратным. И в довершение проигрывал аналогичному TRUNCATE.
Пробуем DELETE еще раз, но с новшествами. Новая идея состояла в сочетании TRUNCATE и DELETE. Сочетание основывается на количестве строк во временной таблице.
Нужно написать такое регулярное выражение в правиле подмены, которое бы в зависимости от количества строк либо оставляло запрос как есть с TRUNCATE, либо меняло его на DELETE.
«Большое количество строк» определялось эмпирически. Мы остановились на цифре 100 000 строк, и подменный запрос принял вид:
SET NOCOUNT ON;
DECLARE @count int
SELECT @count = MAX(row_count)
FROM tempdb.sys.dm_db_partition_stats (nolock)
WHERE object_id = object_id('tempdb.dbo.#tt378')
IF @count < 100000
DELETE FROM #tt<номер таблицы>
ELSE
TRUNCATE TABLE #tt<номер таблицы>
SET NOCOUNT OFF;Code language: PHP (php)Вот так выглядит трасса TextMask по всем запросам удаления временных таблиц (TRUNCATE + DELETE) в мониторинге PerfExpert с отсортированной по убыванию длительностью запросов:
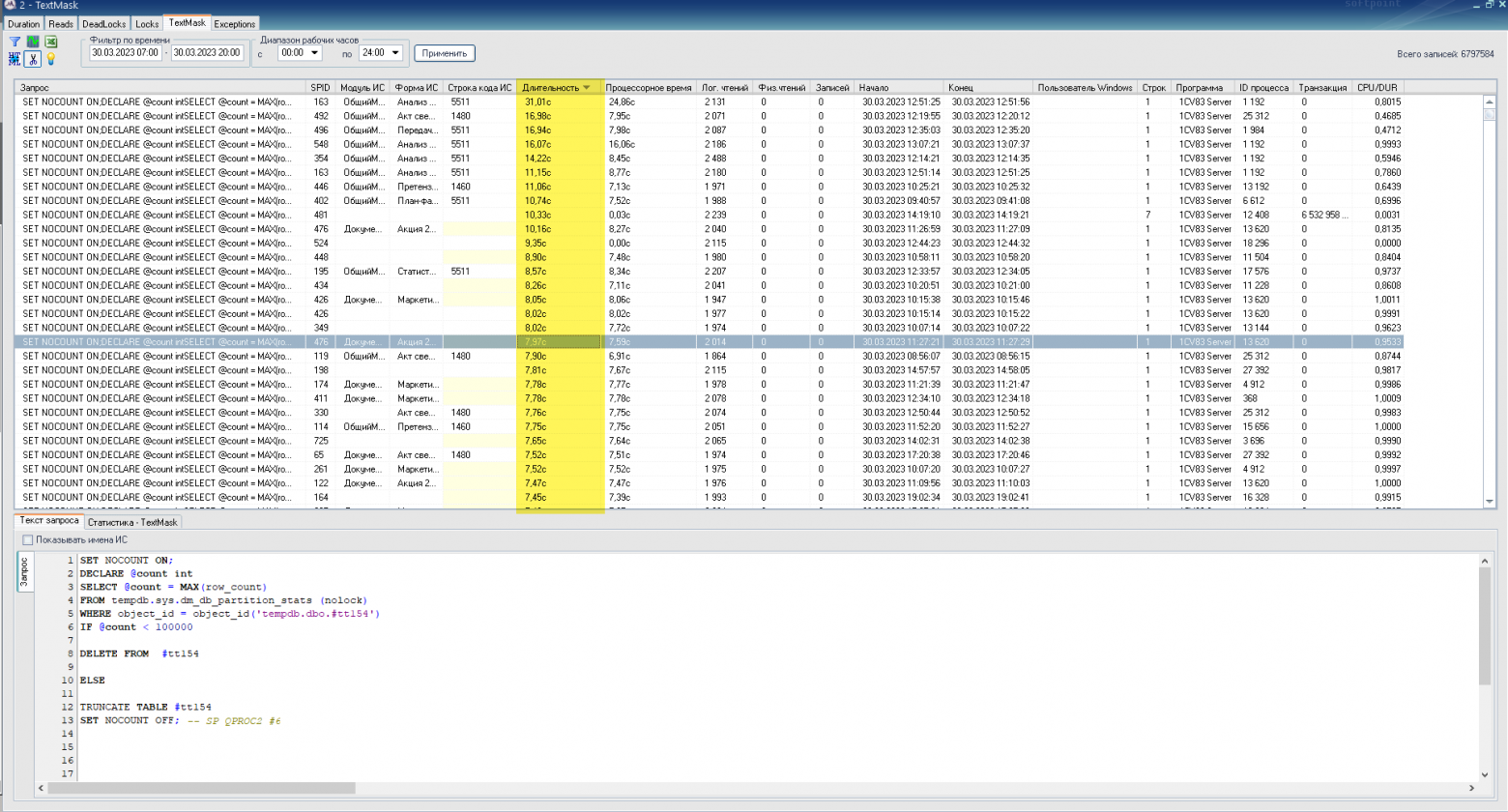
За один день в рабочие часы получились такие цифры:
- Кол-во запросов – 6,7 млн.;
- Среднее значение длительности – 0,01 сек;
- Максимальное значение длительности – 31 сек.
Распределение длительности в течение дня представлено на рисунке ниже, причем видно, что по всему дню было лишь несколько точечных всплесков.
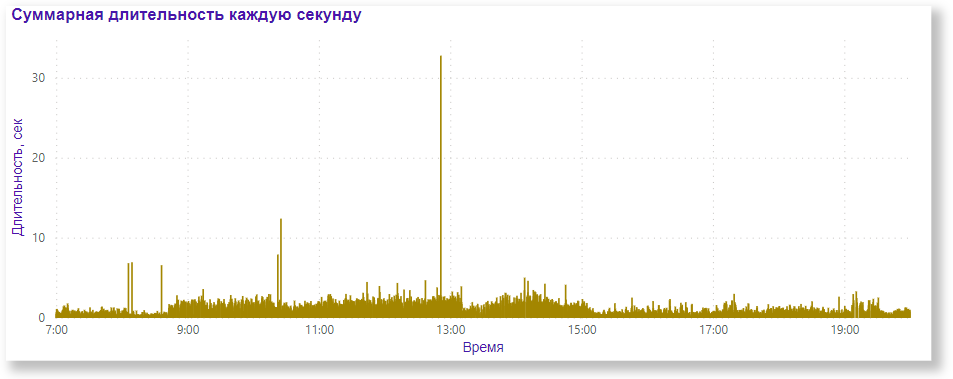
Если же рассматривать только тяжелые запросы более 5 секунд, как в первоначальных данных, то их почти не осталось:
- Кол-во запросов – 74. Менее одной сотни против 20 тыс. двумя днями ранее;
- Среднее значение длительности – 8,19 сек;
- Максимальное значение длительности – 31 сек.
Распределение длительности в течение дня выглядит так:
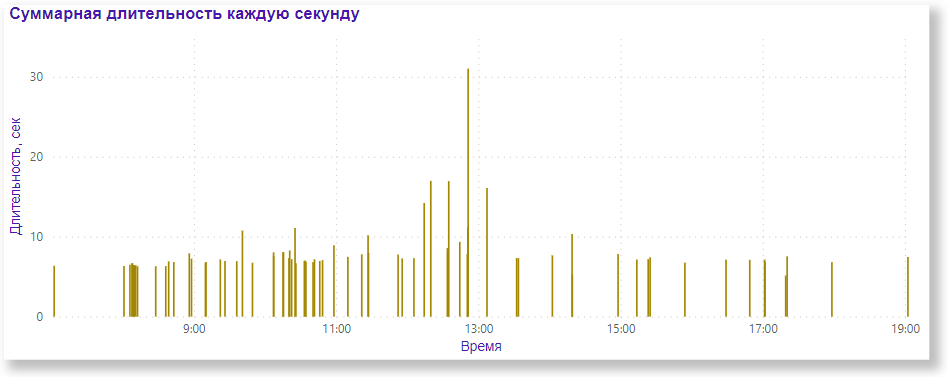
Статистически, выбрав пороговое количество строк во временных таблицах как 100 000, мы распределили примерно в равных долях количество запросов c TRUNCATE и с DELETE. Причем, львиная доля запросов с DELETE приходится на таблицы с количеством строк меньше сотни (см. диаграммы ниже).
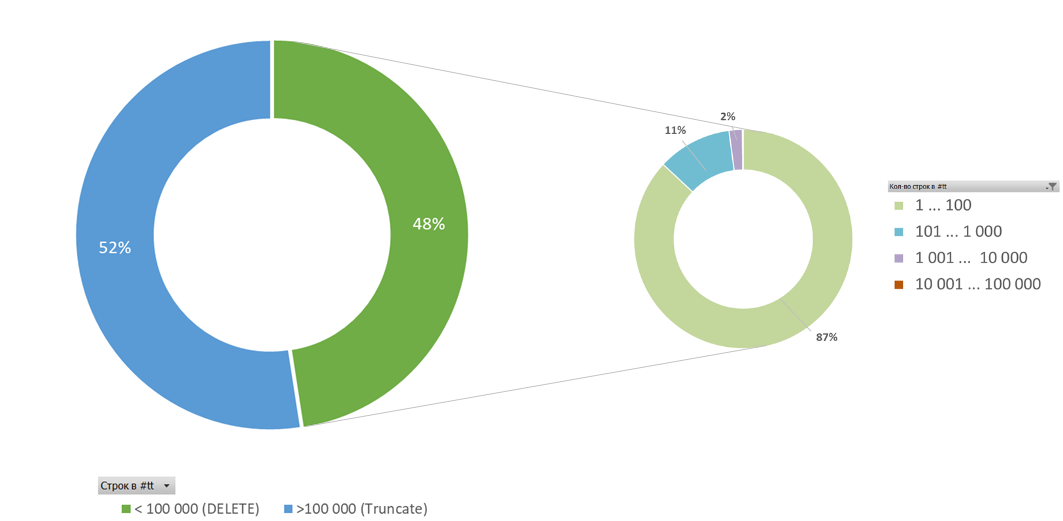
В результате комбинация DELETE + TRUNCATE позволила очень хорошо обойти, пусть и не полностью, странное поведение (или ограничение?) MS SQL Server 2019 и значительно снизить проблему длительных TRUNCATE.
То есть, перебросив всего половину запросов с операции TRUNCATE на DELETE (с условно небольшим количеством строк), удалось очень заметно снизить нагрузку на систему. Считаю результат весьма достойный.
Как подменять текст запроса T-SQL на лету
Платформа 1С формирует T-SQL запрос к БД самостоятельно и вмешиваться в этот процесс нельзя – программист пишет запрос на языке 1С, а дальше платформа автоматически трансформирует этот запрос к серверу СУБД. Использование прямых запросов к серверу СУБД тоже не вариант, т.к. придется брать на себя фактически все функции компилятора запросов 1С и логики платформы. Например, попробуйте контролировать хотя бы номер временной таблицы. Почему она #tt60, а не #tt218?
Поэтому либо нужно переписывать код 1С и отказываться от временных таблиц, хотя бы в критичных по времени операциях (прецеденты уже есть), либо научиться модифицировать запросы на лету. Мы пошли по второму пути, потому что имеем значительный опыт в этой части.
В нашем портфеле уже много лет есть программа Softpoint QProcessing, которая используют технологии модификации запросов к СУБД «на лету», в результате чего ее внедрение происходит без изменения кода приложения.
QProcessing представляет собой программный прокси-сервер, который устанавливается между сервером приложений и сервером баз данных SQL Server.
На рисунке ниже представлена схема работы QProcessing.
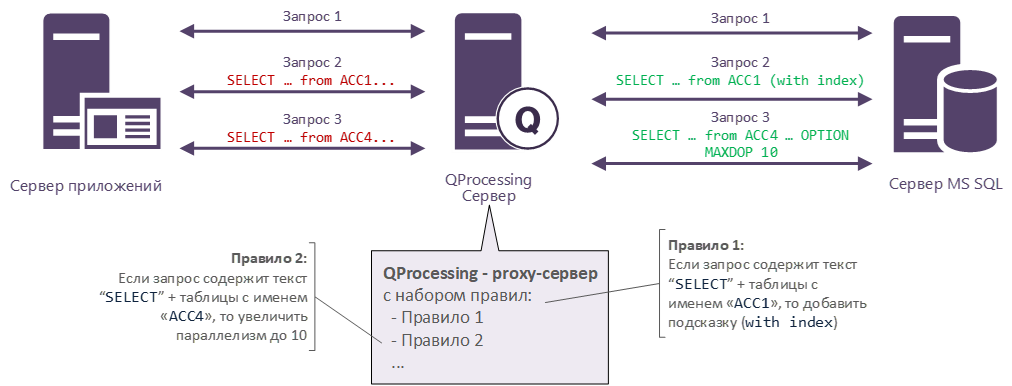
Основные задачи, решаемые Softpoint QProcessing:
- Добавление хинтов к запросам SQL, в результате чего появляется возможность задавать:a) Изменение уровня изоляции транзакции.
b) Подсказки оптимизатору по использованию индексов.
c) Определение опций SQL Server для выполнения запросов. - Связывание различных запросов к SQL Server, которое даст возможность:a) Замены одного текста запроса SQL альтернативным.
b) Изменения имён и параметров в хранимых процедурах.
c) Оптимизация поисковых запросов по подстроке вида LIKE %текст%
Принцип работы QProcessing – перехват всех запросов к СУБД и модификация только определенных, соответствующих условиям, запросов по заложенным правилам. На рисунке выше как раз показан схематично этот процесс – «Запрос 1» проходит как есть без изменений, а «Запрос 2» и «Запрос 3» модифицируются путем добавления подсказок.
QProcessing как точный инструмент хирурга – позволяет подправить запросы, когда нет возможности подобраться к движку приложения, и позволяет ускорить их выполнение в десятки и сотни раз.
Одну из следующих статей обязательно посвятим разбору QProcessing.
Выводы

Проблема, с которой столкнулись наши клиенты достаточно редкая и скорее всего связана с багом внутренних механизмов MS SQL Server 2019 (кстати, в MS SQL Server 2022, как нам сообщили, проблема сохранилась). У кого-то ее нет вообще, у кого-то она есть, но пользователи и администраторы не замечают ее, т.к. критическая масса еще не накоплена. Но те, кто столкнулись с ней, фактически находятся в заложниках – штатных решений для нее нет, а техподдержка MS на заявки из РФ не реагирует и ожидать помощи от них в этой части не стоит в ближайшее время. Поэтому рекомендую очень хорошо взвешивать риски при переходе на следующие версии SQL Server и при установке Service Pack’ов.
Возможные решения:
- Ничего не делать, принимать жалобы от назойливых пользователей и несколько раз в неделю перегружать сервер СУБД.
- Сделать downgrade и откатиться на предыдущие версии MS SQL. Теоретически затея осуществима, но для огромных БД (терабайты) чревата серьезными осложнениями и простоями, т.к. через обычный backup эту процедуру не выполнить. А в маленьких базах этой проблемы скорее всего и нет.
- Вычистить код конфигурации 1С и отказаться по максимуму от использования временных таблиц. Очень ресурсозатратное занятие. По времени может растянуться на годы. Плюс любая последующая доработка должна проходить в парадигме «Мы больше не используем у себя временные таблицы» для вот этих операций. Для около типовых конфигураций, особенно на поддержке, а также для конфигураций, которые активно дорабатываются сторонними подрядчиками – это утопичная идея, потому что любой программист 1С «с детства» приучен использовать временные таблицы.
- Попробовать QProcessing, который без доработки кода 1С позволит на лету модифицировать проблемные запросы. Не только с TRUNCATE, но и любые другие тяжелые запросы, оптимизация которых затруднительна на уровне приложения.
На этом всё. Если вы в своей практике встречались с длительными TRUNCATE и пытались с ними бороться, то буду признателен, если поделитесь в комментариях своим опытом – как удачным, так и неудачным.
Обновление от 04.03.2024:
Отличная новость – есть решение, которое обеспечит исключение длительных выполнений TRUNCATE TABLE средствами SQL Server. Необходимо включить флаг 2392 ( DBCC TRACEON (2392, -1) ). Более подробнее разбор данной ситуации можно прочитать в статье https://sqlpeakperf.com/truncate-troubles-diagnosing-sql-server-spinlock-contention/. Конечно, при включении этого флага мы жертвуем информацией о необходимых индексах и подсказках.
Остается «загадкой» влияние механизма подсказок на усечение временной таблицы, но этот вопрос скорее к разработчикам MS.
Материалы данной статьи оставлены как есть для истории и демонстрации процесса исследования подобных ситуаций.
Ссылки на остальные части Записок оптимизатора 1С:
- Записки оптимизатора 1С (ч.1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
- Записки оптимизатора 1С (ч.2). Полнотекстовый индекс или как быстро искать по подстроке
- Записки оптимизатора 1С (ч.3). Распределенные взаимоблокировки в 1С системах
- Записки оптимизатора 1С (ч.4). Параллелизм в 1С, настройки, ожидания CXPACKET
- Записки оптимизатора 1С (ч.5). Ускорение RLS-запросов в 1С системах
- Записки оптимизатора 1С (ч.6). Логические блокировки MS SQL Server в 1С: Предприятие
- Записки оптимизатора 1С (ч.7). «Нелогичные» блокировки MS SQL для систем 1С предприятия
- Записки оптимизатора 1С (ч.8). Нагрузка на диски сервера БД при работе с 1С. Пора ли делать апгрейд?
- Записки оптимизатора 1С (ч.9). Влияние сетевых интерфейсов на производительность высоконагруженных ИТ-систем
- Записки оптимизатора 1С (ч.10): Как понять, что процессор — основная боль на вашем сервере MS SQL Server?
- Записки оптимизатора 1С (ч.11). Не всегда очевидные проблемы производительности на серверах 1С
- Записки оптимизатора 1С (ч.12). СрезПоследних в 1C: Предприятие на PostgreSQL. Почему же так долго?
- Записки оптимизатора 1С (ч.13). Что не так в журнале регистрации 1С в формате SQLite?
- Записки оптимизатора 1С (ч.14.1). Любите свою базу данных и не забывайте обслуживать
- Записки оптимизатора 1С (ч.14.2). Пересчет индексов на SSD–дисках. Делаем или игнорируем?
- Записки оптимизатора 1С (ч.14.3). Отличия в обслуживании статистик в MS SQL и в PostgreSQL
- Записки оптимизатора 1С (ч.15). Параллелизм запросов 1С в PostgreSQL