Мысли вслух. Протоколы и механизмы синхронизации транзакций в распределённом вычислительном кластере СУБД
Предисловие
Продолжаю вести рубрику «Мысли вслух». Цель данной публикации – описать алгоритмы и новизну моих исследований по созданию кластера СУБД с горизонтальным масштабированием производительности – распределенного вычислительного кластера (РВК). Ранее я публиковал несколько статей на эту тему. Набралась очередная порция материалов в следствие новых изысканий и натурных экспериментов, которыми и делюсь. Сегодня речь пойдет о возможных протоколах работы РВК.
Анализ многих существующих статей и решений по кластеризации СУБД показал разрозненную картину: разные системы мало похожи друг на друга, их функционал и ограничения часто неочевидны. Но есть общая проблема: создание распределённого кластера СУБД обычно приносит серьёзные потери в производительности одиночных операций, плюс сложности в разработке, эксплуатации и сопровождении. Цель моей работы – создать РВК без этих недостатков.
Структура изложения: сначала формулирую гипотезы и утверждения на верхнем уровне, затем раскрываю и обосновываю их подробнее. Полных математических доказательств здесь нет – это не диссертация. Для углублённого изучения рекомендую книгу Мартина Клеппмана «Высоконагруженные приложения. Программирование» (оригинал: Kleppmann M., Designing Data-Intensive Applications) – фундаментальный труд по теме.
Описываемый РВК работает и проходит предпромышленную эксплуатацию. Сейчас дорабатываются механизмы оптимизации и администрирования. Так что, перед вами теория, выросшая из практики.
Базовые требования к РВК
Сначала сформулирую основные свойства и требования к протоколам работы РВК. Описание и обоснование представлю в виде логической последовательности (схемы).
Как и сказал выше, основная цель – создать горизонтально масштабируемый кластер СУБД с минимальными издержками по скорости выполнения атомарных операций.
1. РВК как единый виртуальный SQL-сервер
Суть: совокупность физических SQL-серверов объединяется в один «суперсервер». Потери в линейной производительности должны быть минимальны.
С точки зрения использования РВК должен выглядеть как один большой виртуальный SQL-сервер. Это ключевое требование к простоте эксплуатации.
Напомню, что типичная задача виртуализации обычно решается в сторону разделения большого сервера на мелкие, но не наоборот. Технологии объединения ресурсов существуют – кластеризация, федерация БД, но для СУБД сильно сложнее, чем для вычислительных ресурсов. Таким образом разделить мощный сервер на множество маленьких можно, а вот собрать один из нескольких СУБД-серверов – нет.
Горизонтальное масштабирование достигается за счёт распределения запросов на чтение (вне транзакции) по локальным серверам кластера. Осталось самая малость – разобраться с запросами на изменение.
Контрпример: существуют различные онлайн псевдокластерные репликационные системы с асинхронной синхронизацией, но они требуют сложных механизмов разрешения конфликтов и накладывают ограничения на использование. Они не решают часть конфликтов типа «писатель-писатель», поэтому их сложно считать полноценными транзакционными СУБД.
2. Синхронность данных в момент фиксации транзакции
Суть: данные на всех узлах распределённой БД должны быть идентичны в момент фиксации каждой транзакции.
Это требование вытекает напрямую из пункта 1. Только так можно сохранить линейную производительность. Казалось бы, парадокс, ведь синхронизация требует ресурсов. Но синхронизация распределённых данных (постфактум) требует больших издержек на поддержание согласованности.
По этой причине шардированные системы с распределённым хранением данных здесь не рассматриваются – у них другая модель и другие компромиссы.
3. Нагрузка на чтение должна значительно превышать нагрузку на запись
Суть: Нагрузка(чтение) >> Нагрузка(запись)
Если данные синхронизируются на каждой транзакции записи, то в чём выигрыш? Выигрыш в том, что запросы на чтение выполняются локально на любом сервере кластера. При добавлении серверов нагрузка на чтение распределяется между ними.
Основная цель РВК – масштабирование нагрузки за счёт физического увеличения числа серверов кластера и равномерного распределения операций чтения по ним. Это работает только при условии, что нагрузка операций чтения значительно превышает нагрузку операций записи. И для большинства ИТ-систем это справедливо. То есть основная масса операций чтения будет выполняться на локальных узлах, а операции записи – синхронно на всех.
4. Двухфазный протокол фиксации (2PC) и сверка состава транзакций
Суть: для гарантии синхронности необходим координатор, который
- фиксирует все транзакции в составе распределённой только при полном успехе и совпадении состава.
- откатывает всё и везде – при любой ошибке или расхождении.
Без такого механизма при сбоях данные неизбежно рассинхронизируются. Это следствие природы конфликтов «писатель-писатель» в многопоточных системах.
Гипотеза синхронизации: при тотальном использовании протокола двухфазной транзакции и сверке состава транзакций при завершении можно гарантировать синхронизацию данных. Разумеется, исходные данные должны быть уже синхронизированы. Под «сверкой состава» подразумевается проверка изменённых данных в рамках связанных транзакций. Алгоритмически – это буквально сверка наборов записей inserted/deleted в триггерах изменяемых таблиц. Для скорости можно сверять хеш-суммы всех данных. Если хеш-суммы совпадают, распределённая транзакция фиксируется; если нет – всё везде откатывается
Важное следствие: при тотальном использовании 2PC и сверки состава гарантируется одинаковая хронологическая последовательность конфликтующих объектов внутри транзакций. Параллелизм системы остаётся таким же, как в односерверном варианте. Подробнее об этом с логическими экспериментами и доказательствами см. ниже в отдельной главе.
О репликациях: стандартные репликационные схемы (издатель-подписчик через очередь с задержкой) не решают часть конфликтов «писатель-писатель». При этом двухфазная транзакция сама по себе создаёт большие издержки по производительности – не зря я не знаю ни одной типовой репликации с этим протоколом ни в MSSQL, ни в PostgreSQL. Но решение есть, хотя и непростое.
5. Необходимость Proxy
Суть: для реализации 2PC нужен агент-координатор, отслеживающий открытие, фиксацию или откат транзакций, проверяющий их полное совпадение и целостность в рамках двухфазного протокола. А также обеспечивающий транспорт изменений с минимальными издержками. PROXY – самый практичный способ это реализовать.
Альтернативы:
- В PostgreSQL теоретически можно перехватывать события транзакций через расширения.
- Можно встроить логику в приложение.
Но для СУБД с закрытым кодом (например, MS SQL) PROXY остаётся единственным вариантом.
Кроме того, без парсера в PROXY невозможно решить некоторые критические вопросы производительности и функциональности. Поэтому PROXY считаю необходимым компонентом.
6. Быстрый парсер SQL
Суть: при использовании PROXY и разделении операций на чтение/запись нужен парсер, который делает это быстро и достаточно точно.
Механизмы сверки всё равно присутствуют как страховка, но первичная классификация должна работать на уровне парсера.
7. Требования к данным
Суть: таблицы должны иметь первичный ключ, уникальный индекс, или хотя бы уникальный набор полей. Абсолютно одинаковых записей быть не должно.
Это связано с тем, что один из протоколов использует логическую репликацию, а ей необходимо однозначно идентифицировать каждую запись. Строго говоря, это не обязательное условие, но массовые дубликаты серьёзно просадят производительность.
Можно ли обойтись без PROXY?
Теоретически можно обойтись без PROXY, но это создаёт проблемы надёжности, удобства и, самое главное, производительности.
Допустим, мы хотим сделать честный РВК без посредников. Для этого перед каждой фиксацией транзакции нужно реализовать функцию транспортировки всех изменённых данных и координации фиксации на всех узлах.
То есть нужна функция GetDataTranRepl(tranid), которая будет забирать изменения текущей незавершённой транзакции из репликационных очередей и реплицировать их на все узлы кластера. Если данные не заблокированы и не входят в локальные или распределённые дедлоки, они фиксируются; иначе откатываются везде. В некоторых случаях потребуется проверять их состав (например, сравнивать по хеш-сумме).
Эту функцию придётся вызывать перед каждым commit tran. Возникает проблема: а если где-то забудем? И что делать с единичными изменениями без явно объявленной транзакции? Это порождает эксплуатационные проблемы и проблемы производительности.
Гарантия синхронности данных в распределённом кластере при тотальном применении двухфазного протокола
Теперь обсудим очень важный тезис, к которому я пришел после многочисленных опытов с РВК.
При последовательном применении протокола двухфазной фиксации (2PC) со сверкой состава дифференциальных изменений в конце каждой транзакции можно гарантировать синхронность данных в распределённой базе данных на момент завершения любой транзакции.
Попробую обосновать его.
Постановка проблемы
Допустим, в некоторый момент времени все данные на серверах кластера синхронизированы. Также у нас есть механизм сверки: мы проверяем, что состав изменений в распределённых транзакциях идентичен на всех узлах.
Достаточно ли этого, чтобы гарантировать идентичность данных в любой момент времени?
Ответ: нет. Но если применять двухфазный протокол постоянно – да.
Причина в том, что хронология изменений может отличаться на разных серверах. При постоянном применении 2PC нарушение хронологии приводит к конфликтам, которые разрешаются стандартными механизмами СУБД. Локальные конфликты при использовании 2PC становятся глобальными в рамках всей распределённой системы.
Разберём это подробнее. Но сначала зафиксируем терминологию.
Двухфазный протокол (2PC, ДФ): Протокол координации распределенной транзакции, при котором все участники сначала голосуют за возможность фиксации (фаза подготовки), и только после единогласного «да» координатор приказывает зафиксировать изменения (фаза фиксации). В контексте РВК отдельный сервис на прокси-сервере выступает координатором: определяет начало и конец транзакции, в случае успеха фиксирует её на всех узлах, а при ошибке откатывает.
Конфликты «писатель-писатель» (update-update) и блокировки: Такие конфликты в СУБД обычно решаются с помощью механизмов блокировок (pessimistic concurrency control). Несколько транзакций, пытающихся изменить одну и ту же запись, выстраиваются в очередь. Альтернативы (например, оптимистичный контроль с компенсирующими действиями) существуют, но блокировки – наиболее распространенный и универсальный механизм.
Зеркальный протокол в РВК: Все запросы к СУБД проходят через прокси-сервис. Запросы на чтение направляются на привязанный к сессии сервер. Запросы на запись отправляются асинхронно и одновременно (зеркально) на все серверы кластера.
Центральный протокол в РВК: Если парсер прокси-сервиса определяет, что SQL-запрос на изменение может привести к разным результатам на разных серверах (например, из-за генерации GUID или автоинкремента), он перенаправляет этот запрос на условно-центральный сервер. После его выполнения, с помощью репликационных механизмов (например, триггеров лога), изменения отправляются асинхронно на остальные серверы.
Логический эксперимент 1: пересортица и рассинхронизация на неявных транзакциях
Рассмотрим логический эксперимент рассинхронизации на примере неявных транзакций.
Неявная транзакция – это когда в клиентском SQL явно не объявлены BEGIN и COMMIT, но СУБД все равно выполняет одиночный оператор как транзакцию. Например, одиночный INSERT/UPDATE без явного BEGIN TRANSACTION.
Зеркальный протокол
Предположим, у нас четыре сервера s1, s2, s3, s4, и мы используем зеркальный протокол.
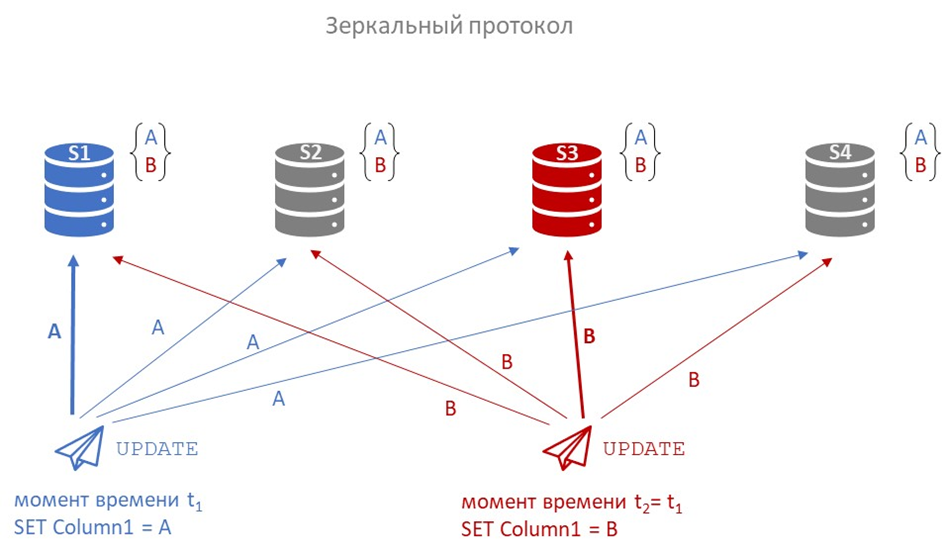
На серверах s1 и s3 «одновременно» запускаются два update одной и той же строки: на s1 устанавливается значение A, а на s3 – значение B.
Поскольку протокол зеркальный, то каждый из запросов зеркально транслируется на все остальные сервера. Дальше вопрос: какое значение окажется на каждом сервере?
Проблема: Порядок отправки пакетов не гарантирует порядка их доставки и применения. В итоге на разных серверах финальное значение строки может оказаться и A, и B. Нарушение единой хронологии применения изменений приводит к распределенному конфликту и рассинхронизации данных. Происходить это может по разным причинам, даже в рамках одной локальной сети. Задержка на микросекунды при отправке, чуть более долгая обработка входящих пакетов на одном из серверов одним из ядер CPU и т.п. То есть это проблема не «сети вообще», а скорее вопрос системы репликации. Итого при конкурентных записях без единого порядка (или без единого координатора записи) реплики могут разойтись.
Центральный протокол
Казалось бы, центральный протокол имеет в своем составе координатора – центральный сервер. Но и здесь будет похожая ситуация для неявных транзакций, идущих параллельно (одновременно).
На самом центральном сервере транзакции выполняются в строгой последовательности (Сессия Х и Сессия X’ на рисунке), но затем пакеты изменений, отправленные на серверы S1, S2 и S3, могут прийти в разном порядке и возникнет аналогичная ситуация с рассинхронизацией.
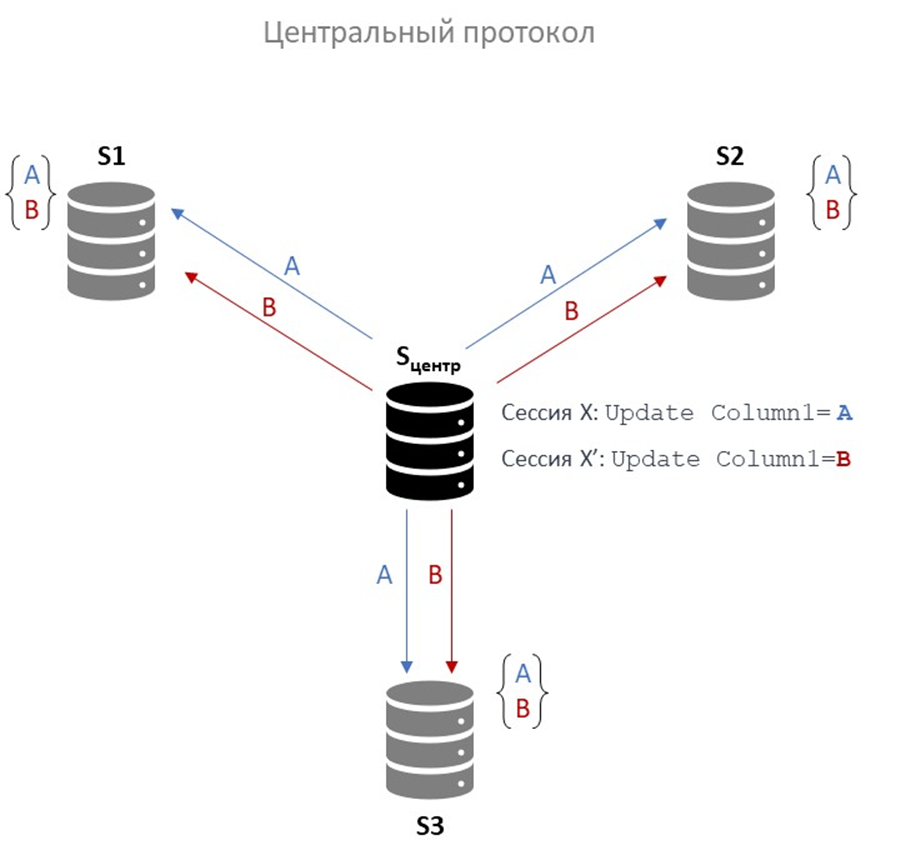
Если центральный сервер единственный источник правды, и он рассылает изменения всем репликам, то стандартный способ избежать расхождения – это обеспечить, чтобы реплики применяли изменения в одном и том же порядке, обычно в порядке лога. Если же изменения доставляются/применяются без гарантии порядка (или параллельно без барьеров), расхождение вполне вероятно.
Эти конфликты неизбежны, когда система стремится к высокому параллелизму, но не обеспечивает единую хронологию для пересекающихся операций. Единственное надёжное решение, которое я пока вижу – это использовать двухфазный протокол вместе со стандартными блокировочными механизмами СУБД. Тогда конкурирующие процессы будут выстраиваться в единую очередь, теряя часть параллелизма, но получая гарантию одинаковой хронологии и синхронности данных.
Конечно, при таком подходе могут возникать распределённые взаимоблокировки (deadlocks). Однако при грамотном проектировании ИТ-системы уровень блокировок остаётся низким, а параллелизм приемлемым.
Логический эксперимент 2: ДФ протокол как решение пересортицы через deadlock
Рассмотрим ту же ситуацию, но теперь в рамках двухфазного протокола. Дальше внимательно, следим за руками.
Есть два сервера S1 и S2.
На сервере S1 запускается распределённая транзакция Tran A S1:
BEGIN;
UPDATE Table1 SET Column1 = 'A' WHERE RowId = 1;
COMMIT;Code language: SQL (Structured Query Language) (sql)В рамках ДФ протокола этот запрос автоматически реплицируется на сервер S2 как Tran A S2.
Одновременно на сервере S2 запускается другая транзакция Tran B S2:
BEGIN;
UPDATE Table1 SET Column1 = 'B' WHERE RowId = 1;
COMMIT;Code language: SQL (Structured Query Language) (sql)Она, в свою очередь, реплицируется на сервер S1 как Tran B S1.
Поскольку у нас двухфазный коммит, то каждая транзакция состоит из двух этапов/фаз – двух сетевых запросов в рамках распределенной транзакции.
Сервер S1 (исходная транзакция):
- Process Tran A S1 [1] — BEGIN; UPDATE Table1 SET Column1 = ‘A’ WHERE RowId = 1
- Process Tran A S1 [2] — COMMIT;
Сервер S2 (исходная транзакция):
- Process Tran B S2 [1] — BEGIN; UPDATE Table1 SET Column1 = ‘B’ WHERE RowId = 1
- Process Tran B S2 [2] — COMMIT;
Сервер S1 (реплика транзакции от S2):
- Process Tran B S1 [1] — BEGIN; UPDATE Table1 SET Column1 = ‘B’ WHERE RowId = 1
- Process Tran B S1 [2] — COMMIT;
Сервер S2 (реплика транзакции от S1):
- Process Tran A S2 [1] — BEGIN; UPDATE Table1 SET Column1 = ‘A’ WHERE RowId = 1
- Process Tran A S2 [2] — COMMIT;
Общая хронология сетевых событий может выглядеть, например, так:
Process Tran A S1 [1]
Process Tran B S2 [1]
Process Tran A S2 [1]
Process Tran B S1 [1]
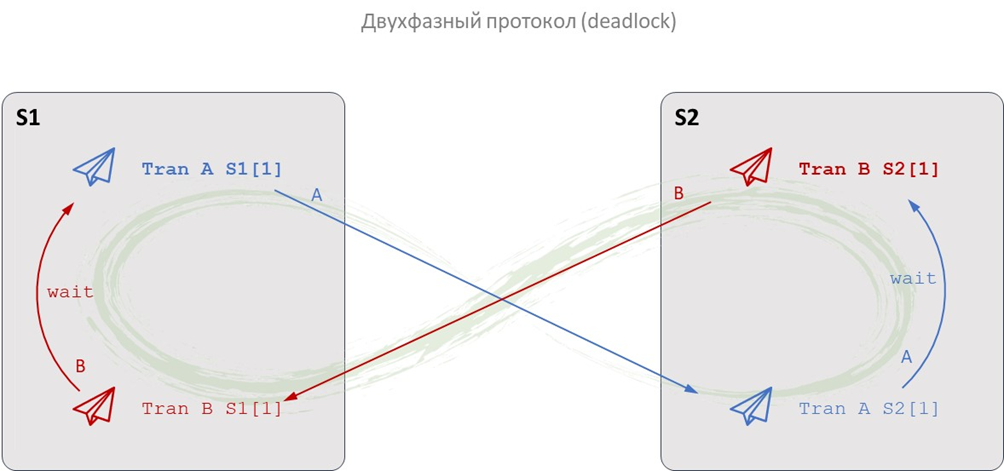
Поскольку Tran A S1 и Tran A S2 – это части одной распределённой транзакции, они не завершатся, пока не будут согласованы все участники. То же верно для Tran B S2 и Tran B S1.
В результате:
Tran B S1 на сервере S1 ждёт освобождения строки, заблокированной Tran A S1,
Tran A S2 на сервере S2 ждёт освобождения строки, заблокированной Tran B S2.
Получаем классический распределённый deadlock: каждый процесс ждёт завершения другого. Ожидать они будут пока ресурс не освободится, а освободится он только в случае завершения или отката транзакции. То есть процессы в случае бесконечного таймаута будут ждать друг друга бесконечно долго и никогда не смогут перейти ко второй фазе COMMIT. Решается это откатом одной из распределенных транзакций (например, по таймауту или с помощью специального сервиса распределённых взаимоблокировок).
Теперь самое главное. Я хочу сформулировать две гипотезы.
Гипотеза 1
В рамках распределенной двухфазной транзакции нарушение хронологии конфликтующих объектов (возникновение «пересортицы») с высокой вероятностью приводит к взаимоблокировке или таймауту, что требует отката одной из транзакций. После этого остаются только те транзакции, в которых хронология не нарушена.
Гипотеза 2 (более важная)
При тотальном использовании ДФ протокола и сверке состава транзакций на идентичность в конце можно гарантировать единую хронологическую последовательность для всех конфликтующих операций. Как следствие, достигается синхронизация данных без снижения уровня параллелизма – он практически остаётся таким же, как в односерверной системе (несмотря на сетевые задержки и необходимость глобальной координации).
Может показаться, что вторая гипотеза очень спорная, особенно в части не снижения параллелизма. Поэтому перейду к обоснованию. Для этого используем модель восстановления базы данных из бэкапа.
Процесс восстановления БД из дифференциального бэкапа и журнала транзакций полностью детерминирован: при повторном воспроизведении мы всегда получаем один и тот же результат. Это возможно благодаря строгой хронологии транзакций и последовательному их применению.
Теоретически можно восстанавливать данные в нескольких потоках, но тогда нужно сначала проанализировать зависимости между операциями: конфликтующие изменения (затрагивающие одни и те же записи) должны применяться строго последовательно, а независимые могут идти параллельно.
В многопоточной распределённой системе ситуация сложнее: связанные изменения могут, во-первых, приходить на разные серверы в разном порядке, а, во-вторых, еще и применяться в разной последовательности без механизма общего порядка.
Как обеспечить единую хронологию, не жертвуя параллелизмом? Рассмотрим проблему от частного к общему. Некоторые вводные:
- Для простоты будем считать, что каждая запись в таблице имеет уникальный идентификатор – первичный ключ, уникальный индекс или даже хеш от всех полей. Это необходимо для корректной работы логической репликации. Случаи с полностью идентичными строками пока не рассматриваются.
- Если две транзакции затрагивают непересекающиеся множества записей, их можно выполнять в любом порядке – результат будет одинаковым:
БД + Tran1(X,Y,Z) + Tran2(A,B,C) = БД + Tran2(A,B,C) + Tran1(X,Y,Z)Но если транзакции пересекаются по записям (например, обе меняют строку Z), порядок важен:БД + Tran1(X,Y,Z) + Tran2(A,B,Z) ≠ БД + Tran2(A,B,Z) + Tran1(X,Y,Z)
Следовательно, если оставить только транзакции, конфликтующие по записям, они должны быть выполнены на всех серверах в строго одинаковой последовательности.
Именно это и выполняет ДФ протокол в связке с локальными блокировками СУБД: он превращает локальные блокировки в глобальные, распределённые. Таким образом, система гарантирует, что конфликтующие операции будут сериализованы одинаково на всех узлах.
Однако возможны и другие источники рассогласования, например, расхождение в составе самих транзакций. Поэтому в конце каждой распределённой транзакции необходимо проводить сверку состава: если набор операций не идентичен на всех участниках, такую транзакцию следует откатить.
Итого:
При тотальном использовании ДФ протокола, который глобализирует блокировки и обеспечивает атомарность, и при обязательной сверке состава транзакций на всех узлах перед фиксацией (для отлова неконфликтующих расхождений), можно гарантировать синхронность данных в распределенной БД на момент завершения каждой транзакции, но не обязательно актуальность (linearizability) в реальном времени для читателей на разных узлах, если не используется строгая изоляция (как Serializable) и специальные схемы чтения.
Конфликт генерации уникальных значений в распределённой системе: IDENTITY (MS SQL Server), SEQUENCE (PostgreSQL), недетерминированные данные
Еще одним типом конфликтов в распределенной среде при использовании зеркально-параллельного протокола (когда один и тот же INSERT отправляется одновременно на все узлы кластера) является корректная генерация уникальных значений, например, автоинкрементных (IDENTITY в MS SQL Server) или последовательностей (SEQUENCE в PostgreSQL).
Генерация уникальных значений на одном сервере
На одиночном сервере СУБД не вычисляет MAX(id) + 1 при вставке новой записи. Вместо этого СУБД использует внутренний механизм резервирования диапазонов значений в памяти. При выполнении INSERT с автоинкрементом СУБД немедленно резервирует следующее значение из счётчика и блокирует доступ к нему на время транзакции. Если транзакция впоследствии откатывается, зарезервированное значение не возвращается, что приводит к «дыркам» в последовательности. Это считается нормальным поведением и не нарушает главную цель генератора: не выдать одно и то же значение дважды в рамках одного генератора.
Маленький нюанс, чтобы не было ложной уверенности: ни IDENTITY, ни SEQUENCE сами по себе не делают колонку уникальной. Уникальность обеспечивает UNIQUE/PRIMARY KEY. Если кто-то явно вставит значение руками, можно получить дубликат, если нет ограничения.
Проблема генерации уникальных значений в распределённой системе с зеркальным протоколом (без централизации)
Теперь представим, что два клиента одновременно выполняют вставку новых документов в таблицу с автоинкрементным полем, используя зеркальный протокол:
На момент начала обеих операций максимальное значение номера документа DocNo=500.
- TranX выполняет INSERT на сервере S1 и получает DocNo = 501 (локально сгенерированный IDENTITY/SEQUENCE).
- Одновременно TranY выполняет INSERT на сервере S3 и тоже резервирует DocNo=501 (потому что локальный счётчик на S3 тоже видит максимум как 500 и ничего не знает про S1).
- Далее зеркальный протокол TranX реплицирует на S3 тот же самый INSERT без зафиксированного значения DocNo и на сервере S3 генератор пытается вставить 502.
- Аналогично TranY реплицируется на S1 и пытается вставить DocNo=502 на S1.
В результате один и тот же документ получает разные DocNo на разных узлах, потому что DocNo генерится локально на каждом узле:
- На S1: документы с номерами 501 (TranX) и 502 (TranY).
- На S3: документы с номерами 501 (TranY) и 502 (TranX).
Хотя сами данные вставлены, состав изменений различается: порядок и/или привязка значений к конкретным транзакциям не совпадают. При сверке по хеш-суммам дифференциальных изменений это будет обнаружено как несоответствие, и обе транзакции будут откачены.
Повторные попытки могут пройти либо успешно (если временная рассинхронизация разрешилась), либо снова вызвать конфликт. Это создаёт нестабильность и непредсказуемое поведение.
Внимательный читатель может спросить: а почему в этом случае не происходит распределённой взаимоблокировки, как в случае с UPDATE одной и той же строки? Потому что это конфликт не «писатель–писатель», а конфликт «читатель–писатель». При генерации IDENTITY или NEXTVAL(sequence) СУБД не читает строку из таблицы, а обращается к метаданным счётчика, который защищён собственной внутренней блокировкой. Эта блокировка локальна для узла и не распространяется на другие серверы. Поэтому две транзакции на разных узлах не блокируют друг друга – они просто независимо резервируют одно и то же значение.
Следовательно, deadlock не возникает, но возникает семантический конфликт уникальности, который проявляется только на этапе сверки или при нарушении ограничения UNIQUE.
Чтобы избежать подобных конфликтов, необходимо перенаправлять все запросы, затрагивающие IDENTITY, SEQUENCE или другие автоинкрементные механизмы, через централизованный протокол:
- Прокси-сервис анализирует SQL-запрос на этапе парсинга.
- Если обнаруживается ссылка на автоинкрементное поле или NEXTVAL(…), запрос направляется только на условно-центральный сервер.
- После выполнения там фиксируются точные значения, которые были присвоены записям.
- Эти значения (а не сам SQL-запрос) реплицируются на остальные узлы в виде детерминированных INSERT с явными значениями.
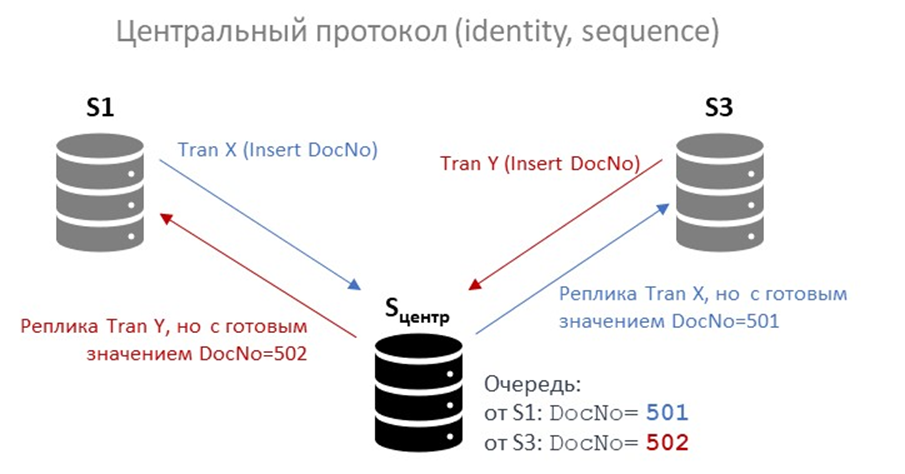
Такой подход полностью исключает рассогласование.
Проблема конфликта недетерминированных значений (GUID, серверные timestamp) в распределенной системе с зеркальным протоколом
Аналогичная проблема возникает с недетерминированными выражениями, такими как:
- NEWID() / UUID() – генерация GUID.
- GETDATE() / NOW() – текущая метка времени.
Если такой запрос выполняется зеркально на всех узлах, то значения будут различаться, например, из-за микросекундных задержек или разных часовых поясов. Это гарантированно приведёт к несовпадению хеш-сумм и откату транзакции.
Возможные решения:
- Централизованный протокол – как и в случае с IDENTITY.
- Генерация на стороне приложения. Например, 1С генерирует GUID до отправки запроса, что делает его детерминированным.
- Подмена на лету при помощи прокси-сервиса с парсером – заменяет NEWID() на конкретное значение, полученное от центрального узла, и подставляет его во все реплицируемые пакеты.
Все три подхода допустимы, но требуют явного управления недетерминизмом на уровне архитектуры.
Выводы
Для реализации РВК с высоким уровнем производительности и параллелизма, обладающего при этом синхронностью данных и высоким уровнем управляемости, как оказалось необходимы строго определенные алгоритмы взаимодействия и вариантов их реализации совсем немного. Важнейшим из них является двухфазный протокол взаимодействия со сверкой состава распределенных транзакций.
Предложение сообществу
В ходе изложения я сформулировал две ключевые гипотезы, лежащие в основе предлагаемой архитектуры распределённой СУБД с тотальным применением двухфазного протокола.
Гипотеза нарушения хронологии в ДФ протоколе:
В рамках распределённой двухфазной транзакции при возникновении «пересортицы» (то есть нарушения хронологического порядка конфликтующих операций типа «писатель-писатель») всегда возникает распределённый deadlock. После его разрешения, например, откатом одной из транзакций, в системе остаются только те транзакции, в которых хронология не нарушена.
Гипотеза синхронности:
При тотальном использовании ДФ протокола и обязательной сверке состава транзакции на всех узлах перед фиксацией можно гарантировать единую хронологическую последовательность для всех конфликтующих операций. Как следствие, достигается полная синхронность данных во всех узлах кластера без снижения уровня параллелизма – он остаётся таким же, как в односерверной СУБД.
Эти гипотезы пока не доказаны формально. Поэтому обращаюсь к сообществу.
Если вы можете предложить логический или практический эксперимент, который опровергает хотя бы одну из этих гипотез, буду очень признателен. Если вы способны математически оформить доказательство, готов рассмотреть финансовое вознаграждение за такую работу.
Отдельная, но не менее важная инженерная задача – гарантированное отслеживание события завершения транзакции, как явной (BEGIN/COMMIT), так и неявной.
Сейчас это реализуется через proxy-перехват SQL-запросов. Почему? Потому что:
- На уровне триггеров (например, AFTER INSERT) невозможно надёжно определить, завершилась ли транзакция – триггеры срабатывают до коммита, и откат всё ещё возможен.
- На уровне парсинга SQL-потока легко что-то пропустить: по одному SQL-тексту не всегда надежно восстановить границы транзакции, особенно если клиент управляет транзакциями нестандартно.
- Штатные средства PostgreSQL или MS SQL не предоставляют механизма, который позволял бы вызвать пользовательскую процедуру точно в момент COMMIT, с доступом ко всем локальным данным транзакции (включая временные таблицы, переменные сессии и контекст изменений).
Если я ошибаюсь, то прошу поправить. Но если такой функционал действительно отсутствует, то готов оплатить разработку расширения для PostgreSQL, которое обеспечит вызов заданной хранимой процедуры после успешного завершения любой транзакции (явной или неявной), с полным доступом к её внутреннему контексту, включая список изменённых строк, значения переменных и метаданные сессии.
P.S.
Раз за разом анализируя логические эксперименты, связанные с межсерверным взаимодействием в рамках двухфазного зеркального протокола, я неизменно ловил себя на ощущении, что где-то это уже видел. И действительно, всё это напоминает известные парадоксы и эксперименты из квантовой механики. Особенно бросается в глаза сходство с транзакционной интерпретацией квантовой механики (Transactional Interpretation), предложенной Джоном Крамером.
И если рассмотреть двухщелевой эксперимент с точки зрения транзакционной модели, то она вполне его объясняет. Межсерверное взаимодействие можно представить как взаимодействие мультивселенных (многомировая интерпретация), а информационно распределенные конфликты заменить на интерференционное взаимодействие. Проводя определенные логические эксперименты, представив нашу реальность как некоторую матрицу, получаются определенные выводы и аналогии.
Не могу подтвердить научную корректность такой замены или то, что из нее можно выводить физические следствия приминительно к РВК. Это лишь способ думать и искать новые вопросы, а не физическая модель, которую я готов защищать как теорию. Если получится аккуратно поставить и провести эксперименты в этой области, я опишу аналогии и ход рассуждений отдельно, в самостоятельной статье.
——
Все публикации из рубрики «Мысли вслух»: