Автоматизация процесса диагностики производительности и ее оптимизации в 1С: Предприятие 8.x
Почему так тяжело расследовать и устанавливать причины просадки производительности в 1С 8
Я работаю в компании, которая занимается вопросами оптимизации производительности и масштабируемости СУБД уже почти 20 лет. В своей практике мы сталкивались с разными ИТ-системами: по масштабу, по платформам приложения, по СУБД. Используя различные программные средства, постепенно выкристаллизовалась методика поиска узких мест любой системы. И дальше встал вопрос об автоматизации не только процесса анализа проблем, но и поддержки производительности. Для этого был создан мощный инструмент, благодаря которому поиск, например, неоптимального запроса и причины его неоптимальности сократился с нескольких дней (это вполне типичный срок поиска проблем у многих команд поддержки и оптимизации баз данных) до нескольких минут. И, как следствие, процессы оптимизации тоже были ускорены в разы.
Продукт, который помогает нам решать большинство проблем производительности, называется PerfExpert. В рамках данной статьи я хочу рассказать не про его функционал, это вы можете посмотреть и самостоятельно, а сосредоточиться на методах/подходах поиска и анализа причин снижения производительности ИТ-систем.
Акцент будет сделан на системы, работающие на платформе 1С:Предприятие 8, потому как для неё в PerfExpert встроено множество дополнительных модулей, плагинов и отдельных продуктов, чтобы тесно интегрироваться с этой платформой, получать данные контекста запросов, пользователей 1С, модули и формы.
Основной проблемой в оптимизации производительности является сложность локализации неоптимального функционала (запросов), и дальнейшая возможность воспроизвести его на тестовой среде.
Это обусловлено несколькими причинами.
Причина 1. Трудность сопоставления сессии SQL и пользовательской сессии 1С
Сервера приложений, как правило, не держат сессию SQL за пользователем, а используют пул подключений. В трассировках СУБД хранится информация об ID сессии и времени, когда запрос выполнялся. В большинстве случае, если сама система при переключении соединений не логирует соответствие, то сопоставить сессию SQL и пользователя 1С весьма не просто, а чаще всего – невозможно. Потенциально это можно попробовать сделать по времени и длительности запроса.
Разберем один из возможных сценариев расследования инцидента, связанного с медленной работой одной из процедур 1С у пользователя.
Пользователь обращается в поддержку, сообщает о проблеме и просит оперативно подключиться к расследованию. Предположим, что обстоятельства сложились благоприятно – специалист службы сопровождения на рабочем месте и у него есть ресурсы для подключения к задаче. Задача срочная, пользователь системы не может сформировать документы – проведение каждого отдельного документа длится в среднем минуту. У специалиста есть в арсенале инструменты: профайлер SQL, консоль администрирования 1С, журнал регистрации 1С и отладчик. Журнал регистрации 1С в 99% случаев оказывается бесполезным, если не ведется постоянная и непрерывная запись соответствий (хотя бы) имени пользователя 1С, номера сеанса, SPID и временных рамок, в течение которых пользователь удерживал этот SPID, так как в ЖР не содержится информация о SPID, только номер сеанса. Отладчиком пользоваться нельзя – работа идет в живой базе с бизнес-данными, да и отладка серверная скорее всего выключена. Есть еще технологический журнал, который определенно полезен, но с ним нужно работать крайне осторожно – правильно настраивать сбор логов, чтобы дополнительная нагрузка на систему позволила дальше «комфортно» работать пользователям, а размер логов не отъел все свободное место. И по окончании сбора еще придется повозиться с обработкой гигабайтных логов от каждого rphost и сопоставить информацию с другими источниками. Для этих целей, конечно, существуют инструменты, например, в составе подсистемы «Инструменты разработчика» и bash-скрипты, но нужно понимать, что для некоторых высоконагруженных систем размер технологического журнала может увеличиваться по 10-15 Гб в минуту, и собирать и анализировать такой журнал продолжительное время станет накладно, соответственно, данные журнала будут содержать эпизодические проблемы, без глубокой ретроспективы.
Как вариант, в первую очередь, можно будет запустить полную трассу и попросить пользователя повторить операцию. Когда пользователь запустит проведение, открываем консоль администрирования, ищем пользователя и устанавливаем какой SPID (или серия из нескольких SPID) принадлежит пользователю в процессе выполнения проведения.
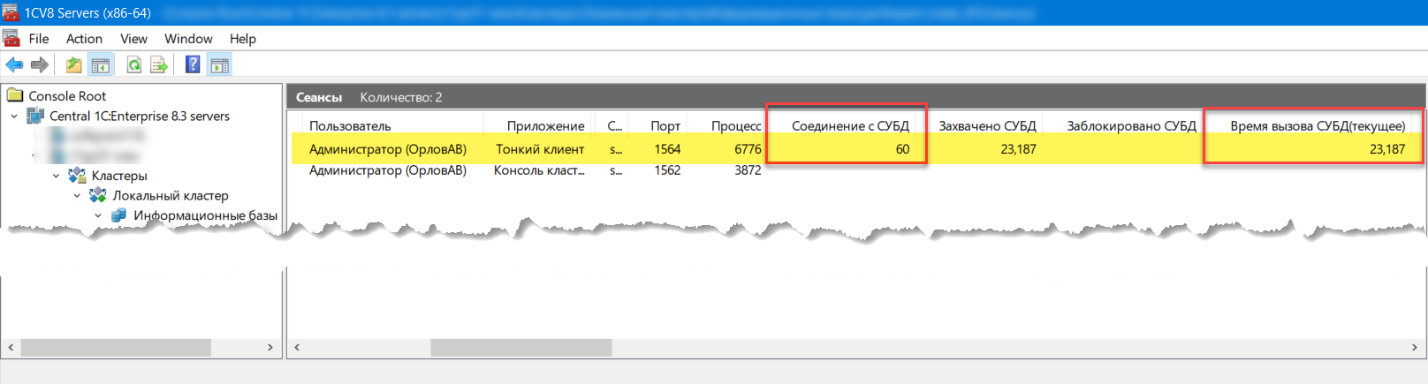
В консоли администрирования специалист обнаруживает, что условному пользователю «Администратор (ОрловАВ)» на протяжении всего времени выполнения процедуры принадлежит SPID 60, время вызова СУБД все время растет, значит время выполнения операции обусловлено скорее всего временем выполнения запроса.
Потратив немалое количество времени (профайлер запускается в продуктивной базе, где еще параллельно работает тысяча-другая пользователей), мы находим интересующий нас запрос по примерно известным времени начала выполнения операции и SPID запроса, полученных на предыдущих шагах. В окне SQL Server Profiler, на скриншоте ниже, представлен результат, который удалось получить:
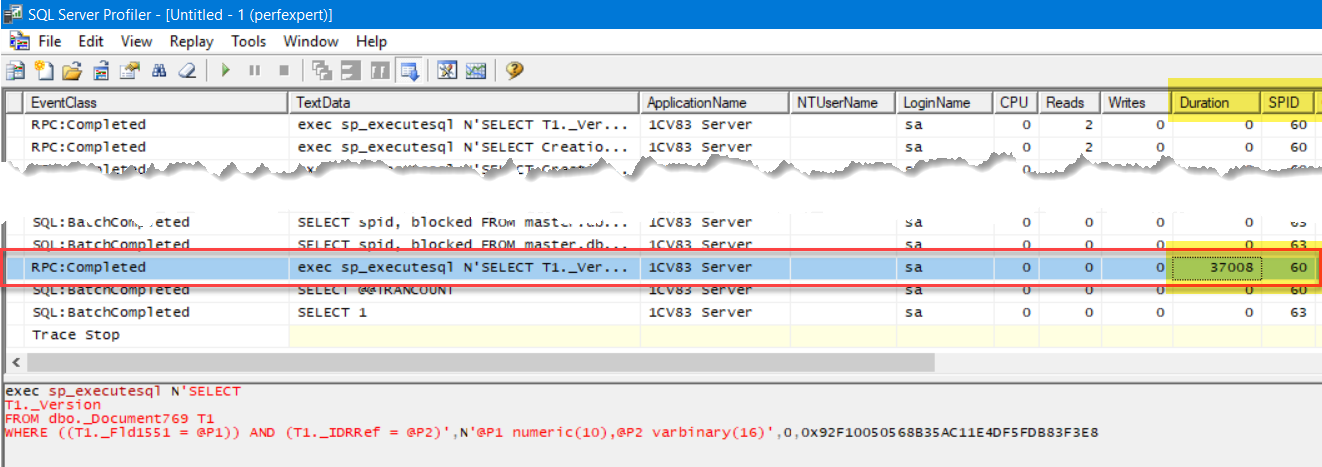
С этим запросом уже можно работать. И несмотря на это, еще остаются не ясны причины такого поведения. Опытный аналитик обратит внимание на соотношение значений CPU/Duration и увидит, что у запроса нулевое потребление CPU (запрос фактически простаивает) и, скорее всего, пойдет перезапускать операцию повторно и мониторить наличие блокировок на сервере. В любом случае, цель достигнута – мы связали вручную активность на стороне 1С и сервере SQL (хорошо, что специалист службы сопровождения был на месте!).
Причина 2. Воспроизведение запроса с временными таблицами на стенде
Идентифицированный в трассе неоптимальный запрос в большинстве случаев сложно воспроизвести, т.к. нет состава временных таблиц, использованных в объединениях. А, как мы все знаем и помним, 1С:Предприятие очень активно использует работу с tempDB и создает временные таблицы в огромном количестве.
Далее представлено подробное описание двух сценариев воспроизведения запроса с временными таблицами на тестовом стенде для его дальнейшей оптимизации при помощи штатных инструментов.
Сценарий 1
Нам известны действия конкретного пользователя/роботов в 1С для воспроизведения запроса. Пусть это будет отчет «Доходы от реализации товаров, услуг».
Используемые инструменты:
- Обработка для чтения журнала регистрации.
- Консоль Администрирования 1С.
- Клиент 1С для формирования отчёта.
- Profiler MSSQL для записи трассы.
- Microsoft SQL Server Management Studio
Последовательность действий:
1. Подготавливаем журнал регистрации для сбора информации по выполняемым отчётам.
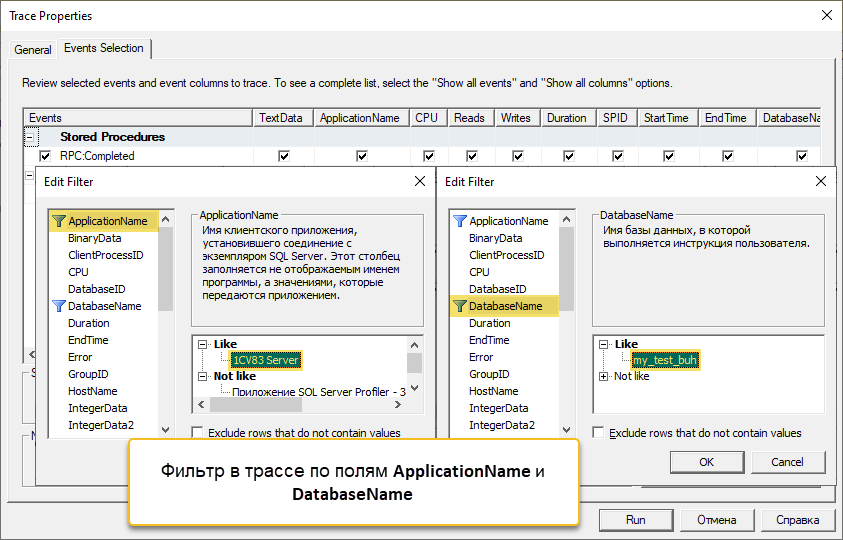
2. Запускаем трассу через SQL Server Profiler на сервере СУБД и настраиваем фильтр трассы по полям ApplicationName и DatabaseName, чтобы уменьшить количество событий, которые будут попадать в трассу. Запросы из других баз данных и приложений не будут собираться.
3. Открываем консоль Администрирования на закладке «Сеансы» для поиска нужного сеанса фонового задания.

4. Запускаем отчёт в клиенте 1С.
5. Во время формирования отчёта, в консоли Администрирования 1С нужно поймать выполнение фонового задания от имени нашего пользователя 1С. В рабочей базе данных от имени нашего пользователя может выполняться множество других фоновых заданий. Поэтому, чтобы найти нужный номер сеанса и соединения с СУБД требуются события из журнала регистрации.

6. Ждем завершения формирования отчёта в клиенте 1С и останавливаем трассу в SQL Server Profiler.

7. Ищем в журнале регистрации фоновое задание с формированием отчета по регистрам налогового учёта от имени пользователя 1С. Находим номер сеанса (189) и сопоставляет его с данным из консоли Администрирования 1С. Таким образом мы получаем соединение с сервером СУБД (114) для поиска нужного запроса в трассе.

8. По номеру соединения с СУБД (114) в трассе находим нужный нам запрос. Видим, что в нем осуществляется выборка из временной таблицы. Чтобы воспроизвести запрос на тестевом сервере, нужно найти тексты запросов по созданию и наполнению временной таблицы.

9. Находим создание и заполнение временных таблицы «#tt11» с помощью поиска в колонке «TextData» в полученной трассе.
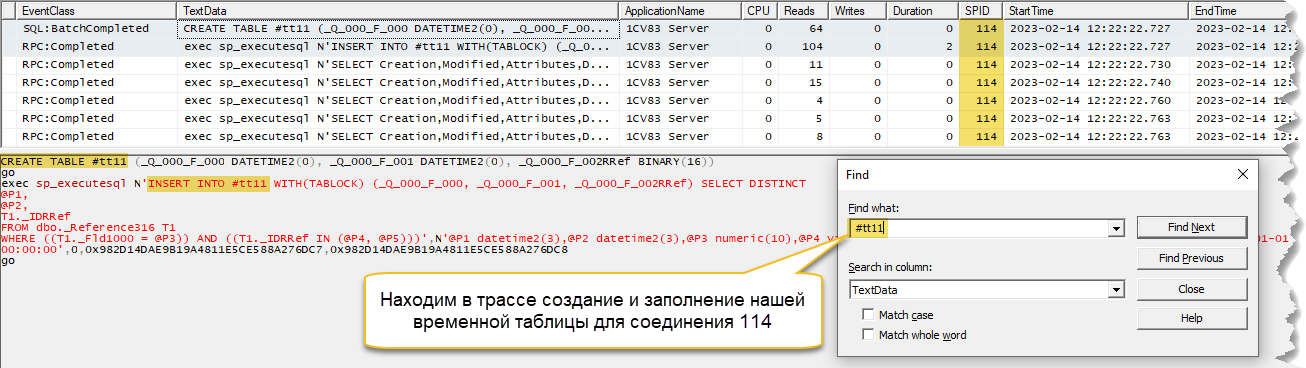
10. Создаем и заполняем временную таблицу. В этом же соединении воспроизводим наш запрос на тестовом стенде. В результате получаем актуальный план выполнения для возможности оптимизировать запрос.

Справедливости ради, замечу, что есть еще различные инструменты по воспроизведению запросов в 1С, например, консоль запросов, которая поддерживает работу с временными таблицами. То есть, запрос можно открыть в консоли с сохранением работоспособности всех параметров и временных таблиц и даже вывести содержимое созданной временной таблицы. Но есть нюанс. Запрос нужно еще идентифицировать, сопоставив код SQL из профайлера с кодом 1С, что далеко не так очевидно и просто в работающей системе.
Сценарий 2
Нам известен только полный текст sql-запроса и то, что в нем используются временные таблицы (#tt)
Используемые инструменты:
- Любой текстовый редактор, например Notepad++.
- Microsoft SQL Server Management Studio
Последовательность действий:
1. Открываем Microsoft SQL Server Management Studio и вставляем сохранённый текст запроса.
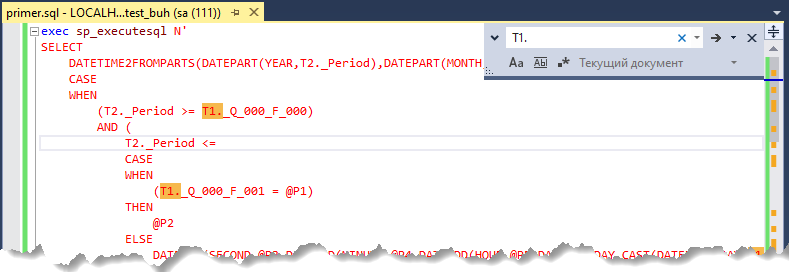
2. Находим псевдоним временной таблицы. В нашем примере запроса присутствует таблица #tt53 с псевдонимом T1.

3. С помощью поиска (Ctrl + F) в Microsoft SQL Server Management Studio находим поля нашей временной таблиц по псевдониму T1. Результаты поиска подсвечены желтым цветом.
4. Поле временной таблицы _Q_000_F_000 соответствует полю _Period реальной таблицы _InfoRg21994 (псевдоним T2). Находим в нашей базе таблицу _InfoRg21994 и проверяем тип данных для поля _Period.
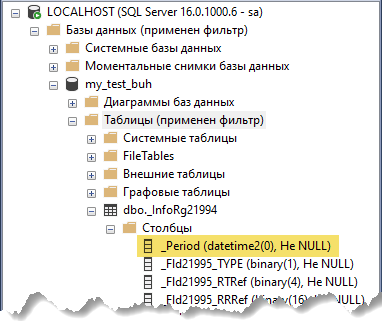
Во временной таблице нам нужно создать поле _Q_000_F_000 с типом данных datetime2(0).
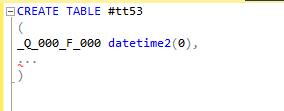
5. Проверяем следующее поле временной таблицы. Поле _Q_000_F_001 соответствует переменной @P1. В переменной @P1 используется тип данных datetime2(3).

Добавляем новое поле _Q_000_F_001 с типом данных datetime2(3) в скрипт создания временной таблицы.
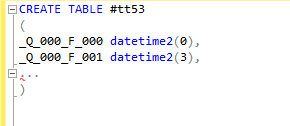
6. Проверяем следующее поле временной таблицы. Поле _Q_000_F_002Rref встречается несколько раз. В первых двух случаях осуществляется проверка, что поле не равно 0. Таких образом проверяется, какие значения будут иметь поля _Fld21995_TYPE и _Fld21995_RTRef. Поле временной таблицы _Q_000_F_002Rref соответствует полю _Fld21995_RRRef реальной таблицы _InfoRg21994 (псевдоним T2).

Поле _Fld21995_RRRef в таблице имеет тип данных binary(16).

Добавляем поле _Q_000_F_002Rref с типом данных binary(16) в скрипт и создаем временную таблицу.

7. Теперь временную таблицу нужно наполнить данными. При наличии плана выполнения можно посмотреть, сколько строк возвращает соединение к временной таблице. В результате было получено две строки из двух. Следовательно, во временной таблице должно быть всего 2 строки.

Если план выполнения отсутствует, то временную таблицу следует заполнять последовательно различным набором данных. Например, можно начать с одной строки, затем добавить 5, потом 10 и так далее. После каждой вставки новых данных следует проверить выполнение запроса. Добавлением данных в тестовой базе необходимо добиться воспроизведения длительности и количества логических чтений, как в исходном варианте (в рабочей базе).
8. Заполнение временной таблицы данными.
Поле _Q_000_F_001 во временной таблице ссылается на параметры @P2, @P7 и @P13. Все три параметра имеют одно и то же значение – ‘2001-01-01 00:00:00’.

Поле _Q_000_F_000 содержит данные из реальной таблицы _InfoRg21994, поле _Period.
Поле _Q_000_F_002Rref содержит данные из реальной таблицы _InfoRg21994, поле _Fld21995_RRRef.

9. Создаем и заполняем временную таблицу. В этом же соединении воспроизводим наш запрос на тестовом стенде. В результате получаем актуальный план выполнения для возможности оптимизировать запрос.
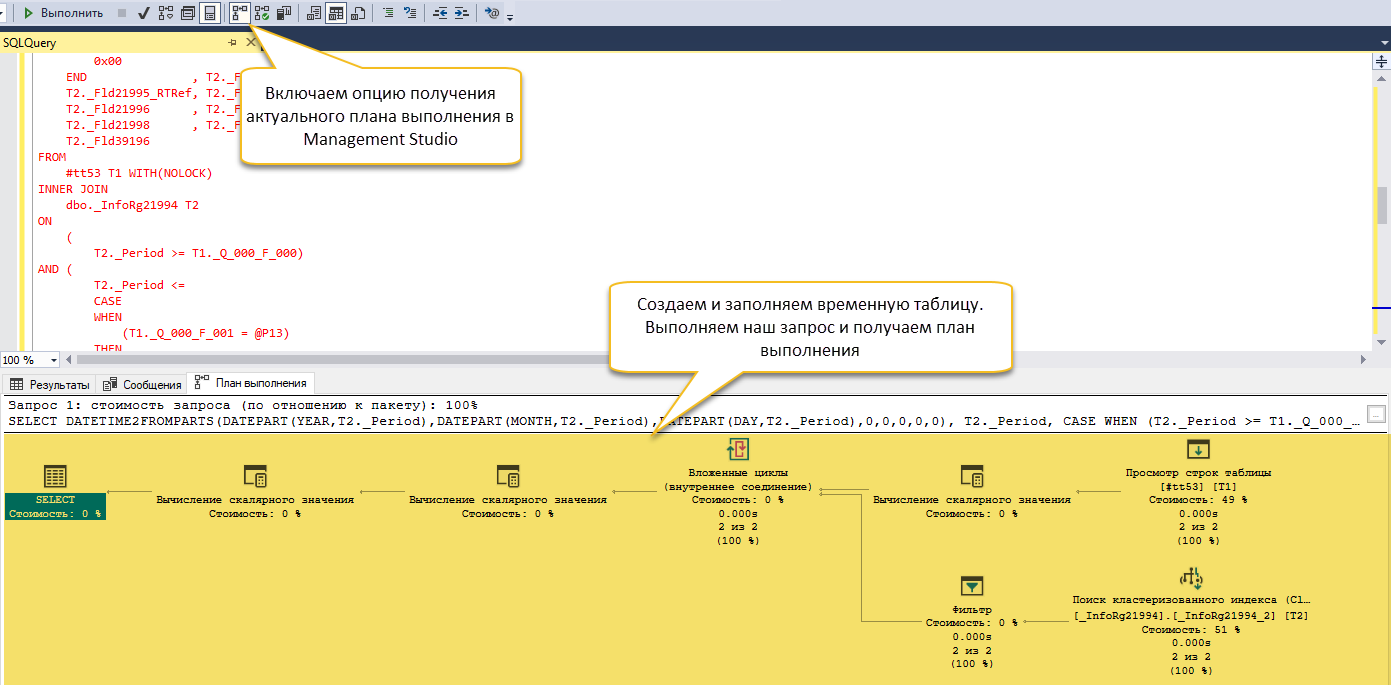
Как видно, воспроизведение запроса для его оптимизации — процедура довольно муторная, затяжная по времени и часто с непредсказуемым результатом.
Причина 3. Трудность оценки вклада запроса/группы запросов в общую нагрузку
Из одного и того же функционального участка приложения запрос может динамически создаваться во множестве вариантов. Из этого возникают две проблемы. Первая – эти запросы сложно сгруппировать и понять их вклад в общую нагрузку на систему. Вторая – имея информацию о форме вызова, бывает сложно воспроизвести запрос, не обладая детальной информацией о действиях пользователя. Расписывать детально тут смысла не вижу, всё и так понятно.
Общий вывод – не хватает автоматизированной системы локализации и воспроизведения неоптимальных конструкций в СУБД, всегда это рутинный процесс, к тому же, не поддающийся нормальному планированию.
Как мы автоматизировали процесс диагностики и повышения производительности серверов и баз данных
На рынке представлено множество систем мониторинга от разных вендоров. Если сравнивать функционально сопоставимые продукты, то все они плюс/минус позволяют накапливать определённую статистику, в различных разрезах, с какой-то степенью детализацией. Но! Основная проблема, описанная выше, всё равно остаётся, так как, зачастую, бывает непросто найти в себе силы, терпение и достаточное количество времени, чтобы разобрать проблему и установить причинно-следственные связи.
В основе работы мониторинга PerfExpert применены два метода, которые смело можно назвать инновационными. По крайней мере, я не встречал ранее продуктов, где подобные механизмы применялись для целей анализа и оптимизации запросов.
Первый метод является комбинацией технологии мониторинга производительности (множество разных счетчиков, в том числе нетиповых, от сервисов и серверов) и проксирования (перехвата) сетевого трафика.
Во втором методе добавляется перехват и логирование пользовательских экранных форм. При правильной реализации они дают минимальную добавочную нагрузку, не более 1% от ресурсов исследуемых серверов.
Вернемся к обозначенным выше причинам и как они решаются в PerfExpert.
Сопоставление сессии SQL и пользователя 1С
Кроме неудобства и длительности процесса ручного сопоставлений сессии sql (SPID) и сеанса 1С существует еще проблема изменения SPID в рамках одного сеанса. Это добавляет ещё сложностей в сопоставлении активности на стороне SQL и сервера 1С.
Поэтому мониторинг должен не только показывать соответствие сессий 1С и SQL, но и уметь не потерять SPID у сеанса 1С. Ниже на рисунках с рабочим окном PerfExpert очень хорошо видно, как мониторинг, во-первых, сопоставляет сессию 1С у пользователя со SPID, а, во-вторых, видно, что у пользователя в рамках жизни одной сессии 1С меняется SPID. То есть, одному сеансу 1С соответствуют пул соединений sql.

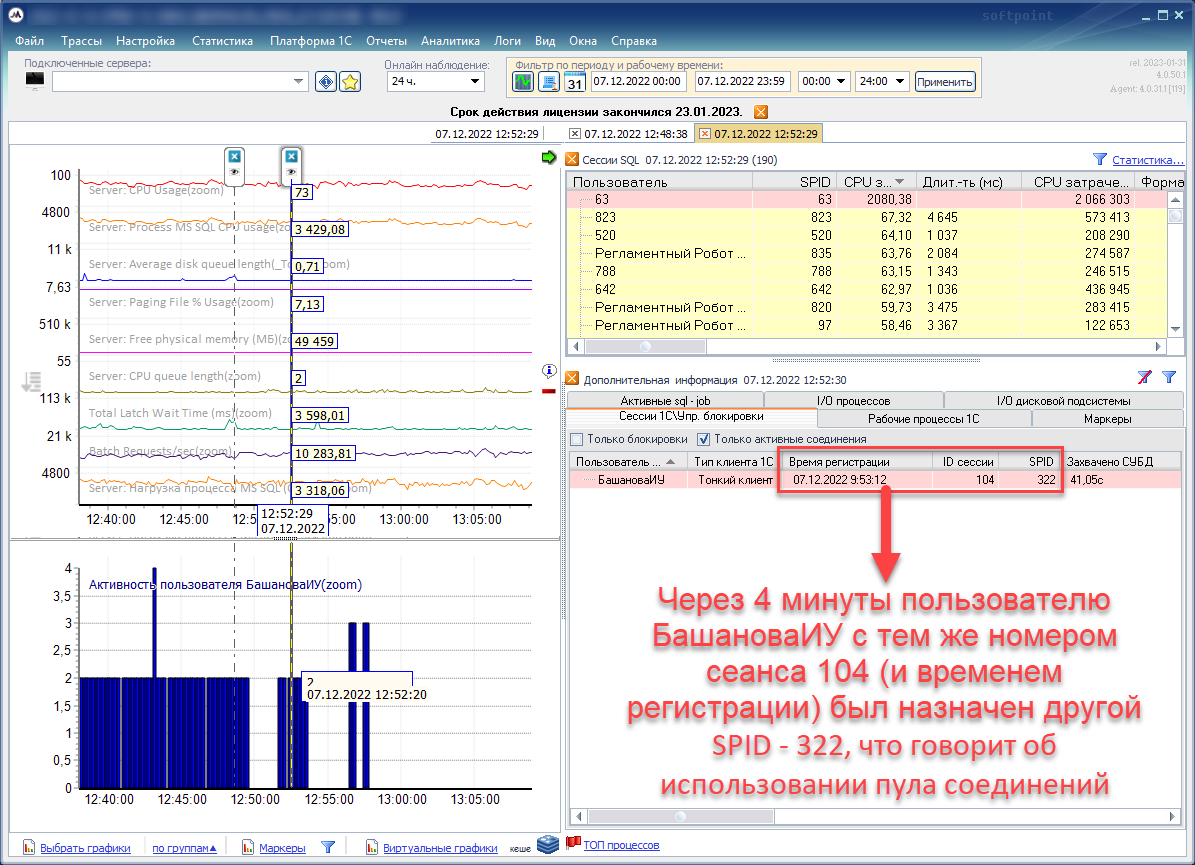
Таким образом мониторинг позволяет очень точно отслеживать и сопоставлять деятельность пользователя 1С (или фоновых процессов) и запросов на уровне SQL. Например, можно отфильтровать все процессы по определенному SPID или пользователю, и не потерять в огромном списке сессий SQL нужные.
Состав временных таблиц в запросе и его воспроизведение на стенде
Все запросы, поступающие на сервер СУБД, мониторинг PerfExpert, с целью сделать удобным их анализ, распределяет по так называемым трассам – Duration, Reads, Locks, DeadLocks, Exception.
Каждая запись трассы содержит полный запрос, который можно открыть, посмотреть его план и оценить методы оптимизации.

Мониторинг позволяет достаточно быстро получить список временных таблиц с полями, используемых в запросе .
Группировка запросов по типу и различные параметры в запросе.
Как правило проблемный запрос (я имею в виду sql-запрос) не является лишь ОДНИМ запросом, который мешает жить. Один запрос – это один инцидент. Запросов много, от разных пользователей, фоновых заданий и т.д. Просто это могут быть очень похожие запросы, которые можно сгруппировать по сигнатуре, и отличающиеся, например, лишь параметрами.
Для объединения запросов в группы необходимо избавиться в тексте запроса от всех строковых литералов, констант, значений параметров, временных таблиц и других незначимых частей, без которых суть и логика запроса не поменяется. В PerfExpert это сделано путем прогона запроса через ряд регулярных выражений, которые по сигнатурам почистят текст и оставляют только каркас.

На скриншоте выше в нижней табличной части выведена сгруппированная статистика по запросам. Запросы предварительно очищены и им присвоен уникальный хеш-номер по алгоритму MD5. Выбрав такую группу в нижней табличной части (на рисунке это строка №6, подсвеченная курсором), в верхней табличной части отобразятся все её запросы, которые могут содержать разные параметры, имена временных таблиц и т.п.
Действия пользователей, которые привели к деградации производительности
Очень часто бывают ситуации, когда функциональность с плохой производительностью сложно воспроизвести. Какой-либо отчет в большинстве случаев ведет себя абсолютно предсказуемо и правильно, но именно комбинация каких-то параметров на форме формирует запрос, который приводит к значительной деградации производительности. В случае с 1С:Предприятие 8.х, мониторинг PerfExpert собирает временные срезы, используя API по соответствию идентификаторов процесса в SQL к процессу в сервере приложения. Он перехватывает открытие экранных форм в приложении и отдельно логирует их названия. В некоторых случаях есть возможность даже снимать скриншоты или видео.


Но, разумеется, основное требование к системе мониторинга – это не нагружать подключенные к ней серверы и не становится причиной снижения их производительности. Поэтому сначала собирается статистика по пользователям, формам и только потом на основании этого, понимая, что именно конкретный функционал и поведение конкретного пользователя приводит к последствиям, можно начинать собирать видеоконтент, который в дальнейшем поможет тестировщикам и программистам легко воспроизвести инциденты по обращениям пользователей.
Предположим ситуацию, когда выполнение отчета «Расчет прибыли по партиям» у пользователя Иванова приводит к появлению специфических запросов с неоптимальными планами выполнения и появлению избыточной нагрузки на систему. Имеет смысл снимать и фиксировать скриншоты или видео только при превышении некоторого порогового значения. И потом из самой системы мониторинга можно удобно просмотреть статистику по инцидентам. Это позволяет селективно хранить только необходимую информацию, не раздувая объем хранилища и не приводя к дополнительной нагрузке на терминальные сервера. Разумеется, в этом случае подключение дополнительных компонент мониторинга должно пройти проверки на безопасность, а пользователи должны быть проинформированы что информация окна приложения 1С (не экрана компьютера!) будет предоставлена ИТ службе для анализа возникающих проблем.
Краткое описание алгоритма логирования видеоконтента по интересующему нас функционалу:
- На основании технологии перехвата экранных форм приложения 1С происходит сопоставление данных пользовательских интерфейсов к выполняемым SQL запросам.
- На основании данных мониторинга определяется пользователь и экранная форма, которая приводит к нагрузке.
- При открытии интересуемой формы, или последовательности форм на основании определённого параметра начинается вестись запись. Триггер срабатывает либо на каждое, либо на каждое N-е открытие формы.
- При этом опционально пользователь может получить информацию о записи скриншотов экрана или видео.
- Видео с помощью сервиса интеграции складывается в базу данных мониторинга.
В дальнейшем программист или тестировщик сможет достаточно легко и удобно просмотреть последовательность действия пользователя и состав заполненных реквизитов.
Выводы и заключения
Спасибо, что дочитали статью, точнее — почти дочитали :).
Основная мысль, которую я хотел донести – это то, что задача оптимизации производительности высоконагруженной системы сама по себе является целым направлением в ИТ-отрасли, причём узконаправленным. Некоторые компании могут позволить содержать себе отдельный штат сотрудников, которые будут заниматься только этой задачей, но в большинстве организаций служба поддержки занимается одновременно всем. Соответственно компетенций хватает не всегда. Мы много лет совершенствуем наш мониторинг и пытаемся облегчить тяжелые будни системных администраторов, администраторов баз данных, разработчиков. Ведь если ИТ-специалист будет знать «Что исправить/почему возникла проблема?», то есть локализует проблему, то это уже больше половины решения. Потому что вопрос «Как исправить?» решается после этого, зачастую, автоматически.
Мониторинг PerfExpert позволяет на порядки ускорить процессы диагностики и поиска причин снижения быстродействия серверов и баз данных, выделить самые актуальные проблемные запросы в работающей системе и их качественно залогировать для последующего анализа. И, самое главное, может помочь оптимизировать запросы либо средствами sql, либо указать на недочёты со стороны кода приложения.