Записки оптимизатора 1С (ч.13). Что не так в журнале регистрации 1С в формате SQLite?
Хочу вернуться к старой проблеме с хранением журнала регистрации 1С в формате SQLite. История стара как мир, но мы нет-нет, а продолжаем с ней сталкиваться, поскольку очень часто большие информационные системы работают далеко не на самых свежих версиях платформы 1С, а администраторы системы не уследили за форматом хранения журнала регистрации (ЖР).
Формат журнала регистрации в виде файла *.lgd, представляющего собой отдельную БД SQLite, появился в платформе 8.3.5 еще в 2014 году и существовал до платформы 8.3.22 (2022 год). Точнее, до последнего времени существовало два варианта хранения журнала – обычный последовательный и SQLite, на выбор пользователя. А начиная с 8.3.22, в платформе была исключена возможность конвертации журнала в формат SQLite и его дальнейшая поддержка.
Соответственно, если у вас версия платформы в этом промежутке, то есть ненулевая вероятность, что ЖР хранится в формате SQLite. Чем это плохо и что с ним не так?
Наглядно посмотрим к чему может приводить ЖР в формате SQLite в многопользовательской нагруженной системе и выясним как администраторам и разработчикам понять, что проблема просадки производительности связана с чтением ЖР.
Вообще, вот так просто, по разным счетчикам производительности проблема не особо очевидна, и многие действительно не понимают в чем же дело. Как и любая другая проблема производительности внешне она выглядит совершенно типично – пользователи не могут работать и активно жалуются на зависания в поддержку. При этом специалисты чего-то такого страшного в мониторинге как на сервере приложений, так и на сервере СУБД могут и не увидеть. Ну немножко повышена очередь к диску, повышен уровень количества транзакций. Но опять же не критично. Процессор в норме, память в достатке.
Рассмотрим реальный пример. Серверы 1С и SQL расположены на одной машине, хотя на самом деле – это не важно. Поддержка регулярно получает валы заявок. Не понимает природу проблемы, перегружает сервер, срубает какие-то фоновые задания, но эффект кратковременный.
Для анализа будем использовать нашу палочку-выручалочку – мониторинг Perfexpert.
Посмотрим сначала на недельный срез по основным системным счетчикам. На самом нижнем выведен график чтения файла журнала регистрации *.lgd процессом rmngr.exe.
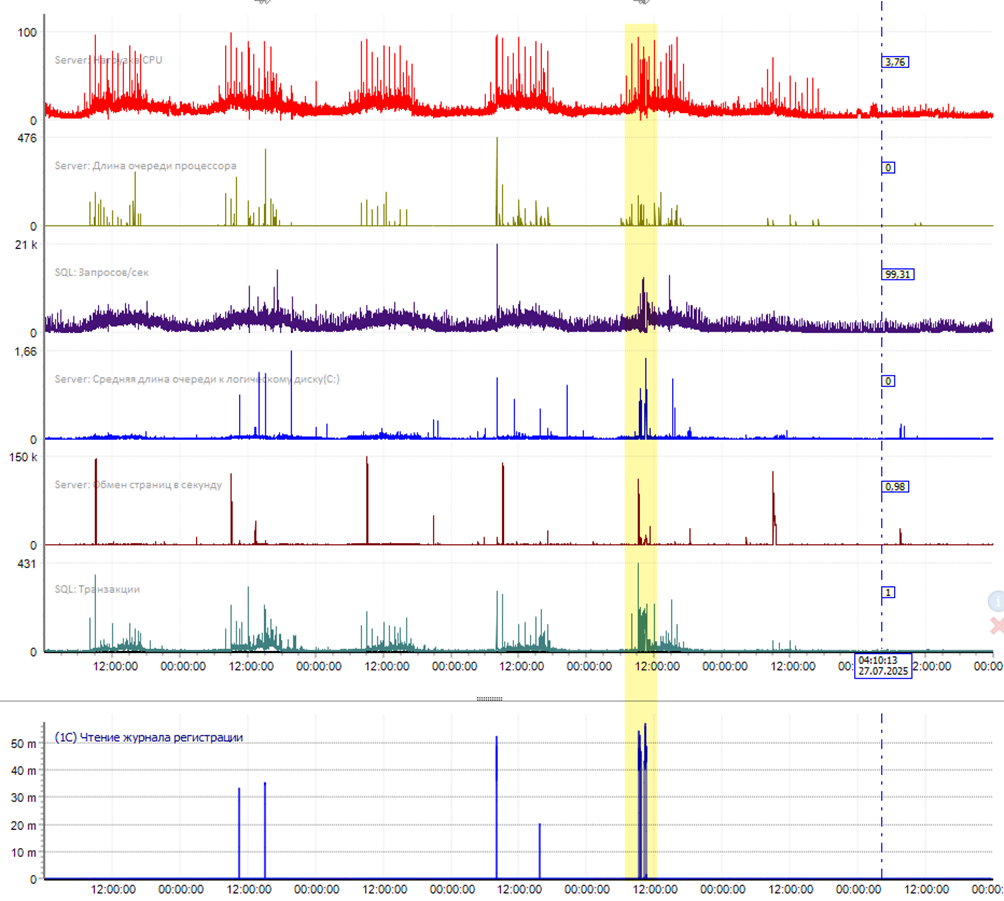
Если бы поддержка с самого начала знала о возможном негативном влиянии журнала регистрации, то обязательно увидела бы, эти синие пики, которые полностью приходятся на волны заявок с жалобами пользователей на сильные зависания системы. И сделали бы правильный вывод. Но такого графика у поддержки может и не быть (есть в штатном функционале Perfexpert) и нужно ориентироваться на другие, косвенные данные.
Приблизим последние два пика (желтая область на рисунке выше), как более затяжные и заметные и посмотрим, что же там:
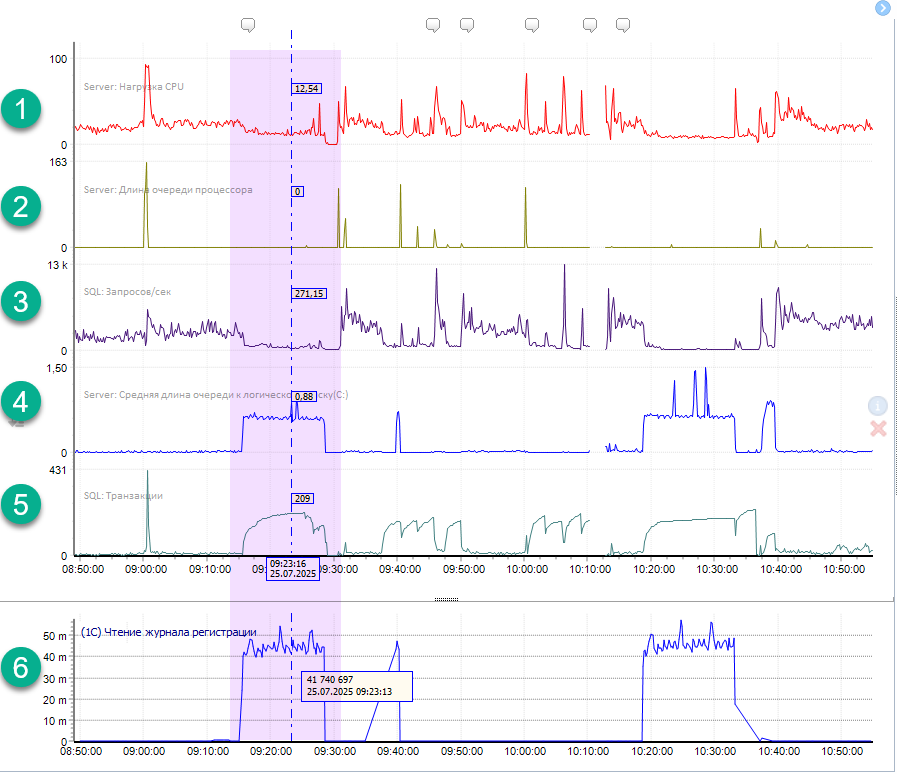
После увеличения пиков оказалось не два, а три. Разберем только первый.
Начнем смотреть системные счетчики. Наша цель – быстро понять и обнаружить признаки, указывающие на возможные проблемы с журналом регистрации. Графики пронумерованы от 1 до 6, чтобы легче ориентироваться по тексту.
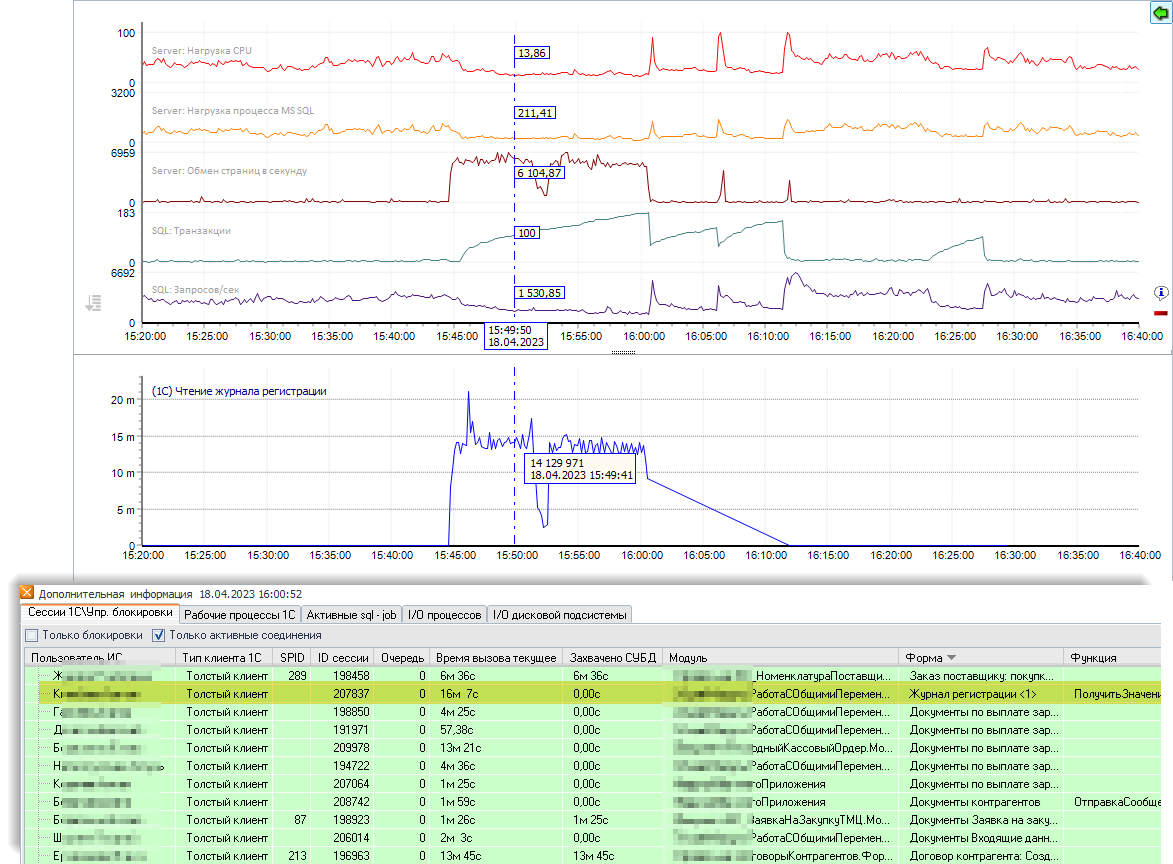
Берем пик на графике чтения ЖР (№6) и смотрим, как на всём протяжении чтения файла *.lgd менялись остальные счетчики:
- Запросов/сек (график №3) – количество упало с нескольких тысяч до сотен и даже десятков запросов в секунду. Т.е. фактически до нуля. Это очень важный маркер, запомним его.
Можно сделать ошибочный вывод, что сервер SQL подзавис, не пропускает через себя запросы и является той самой причиной. Но это не так. Идем дальше. - CPU (график №1). Поскольку в этом примере оба сервера (SQL и 1С) расположены на одной машине, то падение нагрузки не особо ярко бросается в глаза. Но оно есть, запросы со стороны сервера 1С практически перестают поступать на сервер SQL.
- Транзакций /сек (график №5). На сервере SQL фактически копится очередь из выполненных транзакций, которые он не может передать обратно серверу 1С.
- Длина очереди на диске (график №4). Файл *.lgd хранится на диске <С> , поэтому очередь смотрим на нем. Она совсем немного возросла, но пик совпадает с чтением ЖР (график №6). Поэтому нужно тоже обращать внимание на этот счетчик.
Теперь смотрим на вспомогательные панели мониторинга Perfexpert, где расположена информация о сессиях 1С, SQL и другая дополнительная информация. Нас интересует закладка «I/O дисковой подсистемы»:
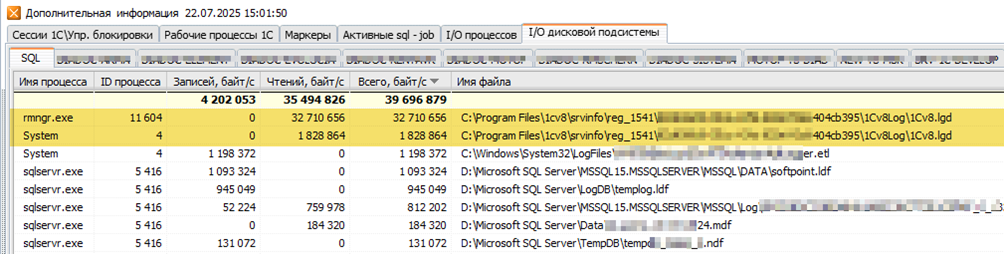
По нагрузке на диск мы видим, что больше всего операций чтения/записей выполняет процесс rmngr.exe с файлом 1cv8.lgd – журналом регистрации 1С.
А переключившись в этой же панели на закладку «Сессии 1С \ Упр. блокировки» мы видим в сессиях 1С пользователя «*** Руслан(DEV)», который как раз и работает в этот момент с журналом регистрации. Вероятно, один из разработчиков. Всё совпадает:

Подведём итоги по счетчикам. Каждый из них по отдельности (графики 1–5) ничего не говорит. И только лишь вкупе они указывают на признаки, говорящие о проблемах с журналом регистрации. Если вы можете построить свой счетчик с чтениями к файлу *.LGD, тогда будет намного легче идентифицировать проблему.
Ниже приведу еще парочку примеров со счетчиками из других систем, когда возникала проблема с журналом регистрации формата SQLite, и были те же признаки: падение кол-ва запросов в секунду на сервере СУБД, рост кол-ва транзакций, снижение нагрузки CPU. И каждый раз счетчик «Чтение журнала транзакций» подтверждает это:
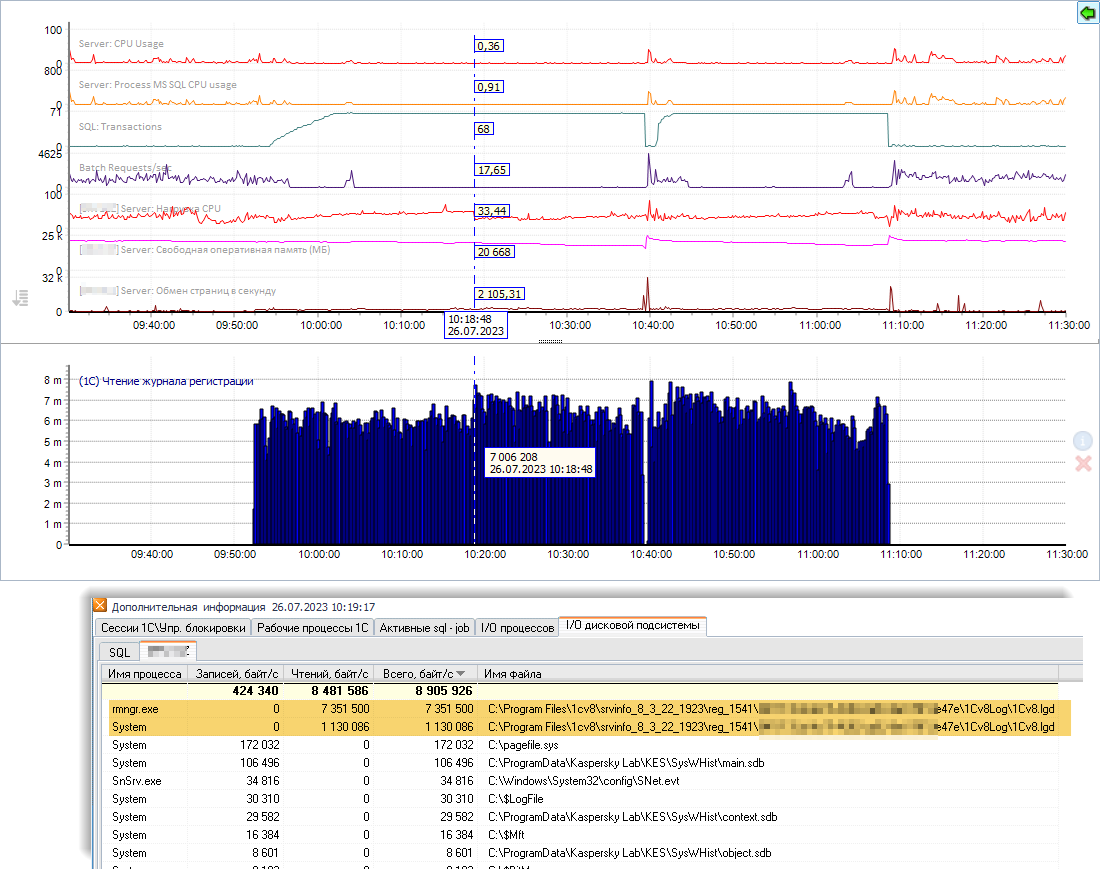
Интересно знать почему так происходит?
Кому нет, можно не читать дальше и просто принять за аксиому, что для нагруженных и многопользовательских ИТ-систем журнал регистрации в формате SQLite – это зло и нужно оперативно перейти на обычный последовательный формат журнала. А кому интересно, предлагаю чуть-чуть поковырять SQLite и смоделировать ситуацию с чтением ЖР.
Что такое ЖР? Это лог изменений, которые делают пользователи. Чем больше система, тем больше изменений. Размер журнала может быть большим и очень большим – сотни и даже тысячи гигабайт.
А что такое чтение данных из файла базы данных *.LGD? Это запрос с различными отборами по таблицам. Чем шире условия фильтрации (типа «покажи мне действия Иванова за весь период с начала времен»), тем хуже последствия. Запросы на чтение (!) выполняются долго, а остальные пользователи не могут в этот момент ничего в журнал записать.
В формате SQLite ЖР состоит из 16 таблиц. Все таблицы в ЖР хорошо нормализованы. Основной является таблица EventLog, в которой два десятка колонок.
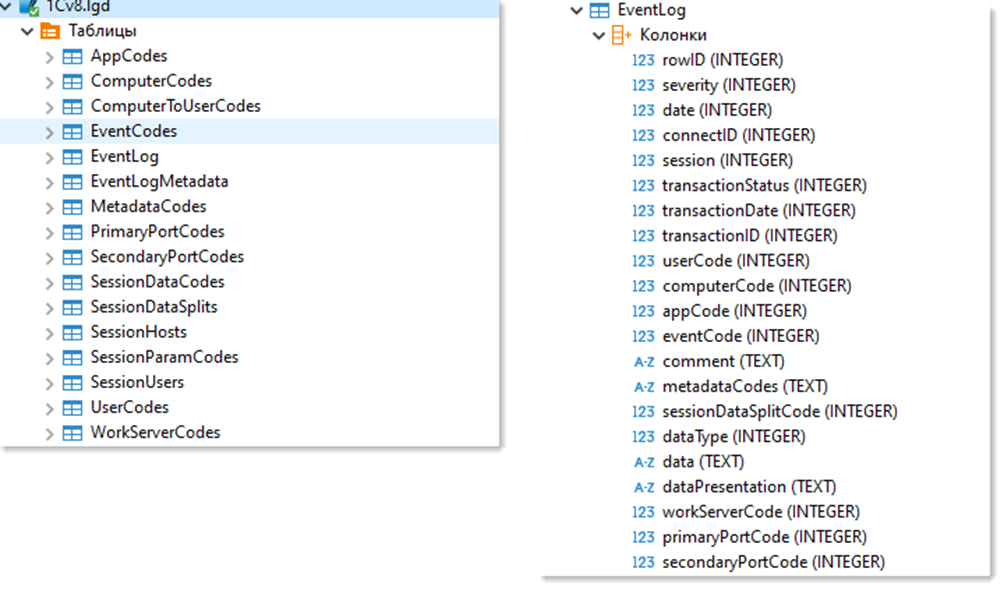
Для моделирования это избыточно и не удобно. Поэтому, чтобы показать суть проблемы, мы создадим в базе SQLite всего одну таблицу из трех колонок, заполним её и будем одновременно читать из нее и писать. Этого достаточно.
[ID] – инкрементальный индекс;
[date] – дата, для колонки создадим индекс (но не сразу);
[text] – просто текстовая строка, единая для всех записей.
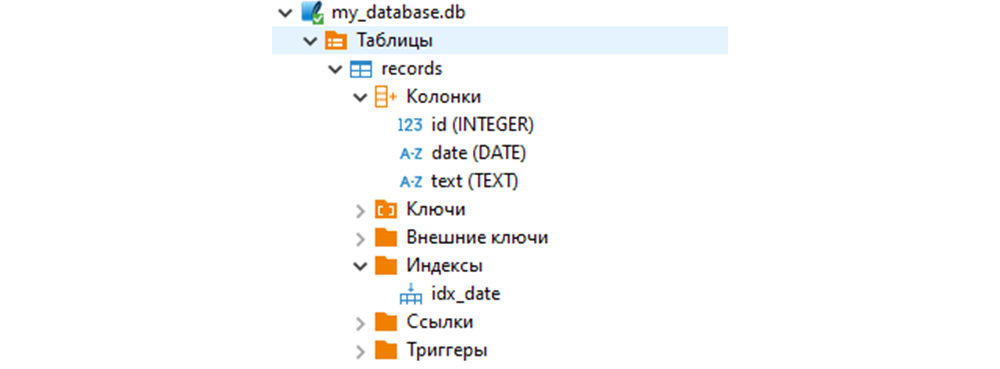
Заполним таблицу так: один миллион строк на каждый день августа 2025. Количество дней – 31, итого получим 31 миллион строк.
Cкрипт на Python для заполнения таблицы
import sqlite3
import datetime
# import random
# import string
def create_and_populate_table(db_name='my_database.db'):
# Подключаемся к базе данных (или создаём новую)
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
# Создаём таблицу
cursor.execute('''
CREATE TABLE IF NOT EXISTS records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
date DATE NOT NULL,
text TEXT NOT NULL
);
''')
# # Создаём индекс
# cursor.execute('''
# CREATE INDEX idx_date ON records (date);
# ''')
conn.commit()
# Получаем текущую дату и определяем первый день месяца
today = datetime.date.today()
first_day = today.replace(day=1)
# Определяем последний день текущего месяца
if today.month == 12:
last_day = today.replace(year=today.year + 1, month=1, day=1) - datetime.timedelta(days=1)
else:
last_day = today.replace(month=today.month + 1, day=1) - datetime.timedelta(days=1)
# Cтроковая константа (можно изменить на нужную вам)
text_content = "Текстовая константа для всех записей"
# Подготовка пакетной вставки
batch_size = 10000 # Количество записей для вставки за один раз
total_records_per_day = 1000000 # Количество записей для заполнения одного календарного дня
batch_count = total_records_per_day // batch_size
# Заполняем таблицу данными за каждый день месяца
current_date = first_day
while current_date <= last_day:
print(f"Обрабатывается дата: {current_date}")
for _ in range(batch_count):
# Создаём список кортежей для массовой вставки
data = [(current_date, text_content) for _ in range(batch_size)]
# Выполняем массовую вставку
cursor.executemany('INSERT INTO records (date, text) VALUES (?, ?)', data)
# Коммитим изменения после обработки каждого дня
conn.commit()
current_date += datetime.timedelta(days=1)
# Закрываем соединение
conn.close()
print("Таблица успешно создана и заполнена")
if __name__ == "__main__":
create_and_populate_table()Code language: Python (python)Теперь открываем DBeaver и в двух сессиях начинаем выполнять запросы на чтение и вставку данных.
Чтение делаем в диапазоне 02.08.25 – 22.08.25. Этот запрос запускаем первым:
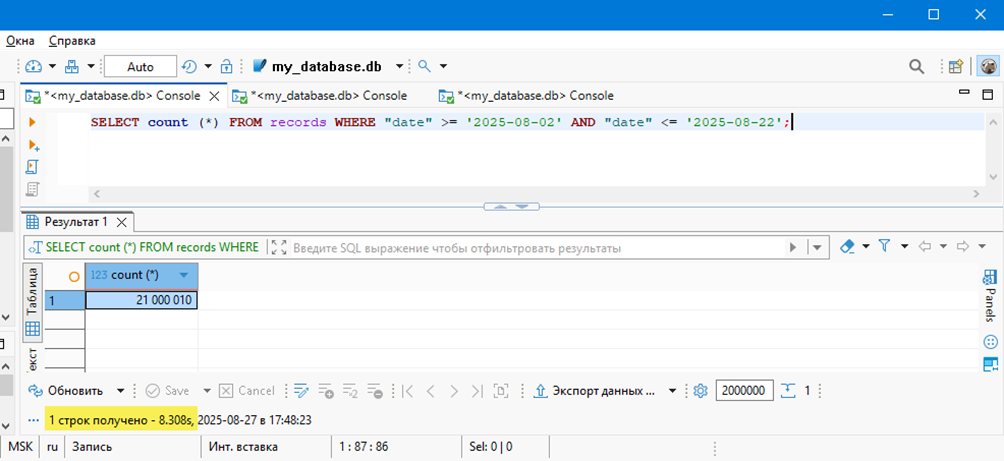
Элементарный запрос, возвращает кол-во строк за заданный интервал дат. На рисунке выше запрос выполнился за 8,308 сек. и индекса на колонке [date] не было. Специально, чтобы было долго и можно запустить вручную вторую сессию. С индексом этот же запрос выполняется за 1,1 сек.
Вставку делаем за пределами диапазона чтения, чтобы в надежде😊 не попасть в «возможное пространство блокировок», наложенное чтением. Например, 25.09.2025 – новая дата, которой нет в исходной таблице. Но общая длительность вставки всё равно почти совпадает с длительностью предыдущего запроса:
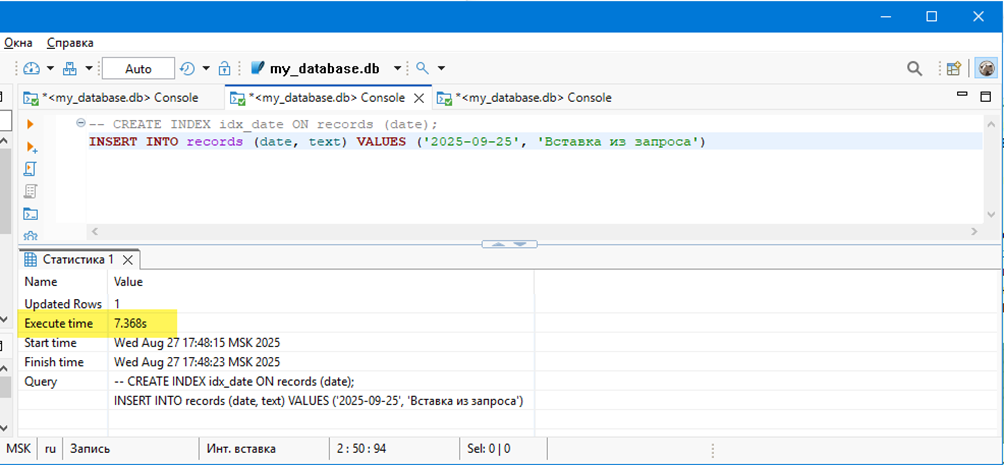
Таким образом, пока не выполнится запрос на чтение
<strong>SELECT</strong> <strong>count</strong> (*) <strong>FROM</strong> records <strong>WHERE</strong> "date" >= '2025-08-02' <strong>AND</strong> "date" <= '2025-08-22';Code language: HTML, XML (xml)второй запрос на изменение ожидает на блокировке SHARED lock и ждет освобождения блокировки или таймаута.
<strong>INSERT</strong> <strong>INTO</strong> records (<strong>date</strong>, <strong>text</strong>) <strong>VALUES</strong> ('2025-08-25', 'Вставка из запроса')Code language: HTML, XML (xml)Получается SQLite слабо приспособлена для высокоинтенсивной параллельной работы со стороны пользователей, т.к. ЖР очень часто меняется, а любое долгое чтение из журнала просто парализует работу всей системы, поскольку остальные пользователи в этот период не могут зафиксировать свои изменения в ЖР. Особенно ярко это будет проявляться на большом размере ЖР (сотни гигабайт), когда какой-то пользователь получает данные журнала с минимальными фильтрами, например, за большой период времени и его запрос (SELECT) будет выполняться гарантированно долго.
Сама идея хранить лог пользовательский действий в базе данных, а не в текстовом файле прекрасна. Индексация, быстрый поиск, фильтрация. А файл – это всегда последовательная запись. И чтение из файла(ов) – это долго, т.к. поиск идет среди неиндексированных данных плюс парсинг и т.п. Но оказалось, что SQLite категорически не подходит для задачи интенсивной многопользовательской работы, т.к. при чтении накладывает избыточные блокировки.
Выводы
- Весь этот текст написан для того, чтобы еще раз обратить внимание читателей на то, что если у вас релиз платформы 1С в промежутке 8.3.5 – 8.3.22, то обязательно проверьте формат хранения ЖР и лучше переведите его в последовательный, как и рекомендует вендор. В противном случае вы можете получать проблемы с производительностью системы, если кто-то из пользователей работает с журналом регистрации.
- Задумка использовать базу данных для хранения журнала регистрации хорошая, но, к сожалению, SQLite как есть не подходит для этого. Вероятно, с базой SQLite можно поработать в части каких-то настроек, но как есть она не подходит для интенсивной многопользовательской работы. Возможно, стоило бы рассмотреть другие форматы хранения, например в виде отдельного инстанса PostgreSQL. Тут свои сложности, но навскидку видится перспективным вариантом.
- Наш мониторинг Perfexpert работает с обычным последовательным форматом журнала регистрации, но он не тянет все данные, т.к. по большей части они не нужны и избыточны, а берет только те события, которые потенциально могут быть полезны при расследовании проблем производительности. То есть, отбирается информация по сеансам 1С, которая уже есть в мониторинге и как фильтр накладывается на ЖР. Так сохраняется баланс достаточности данных в системе мониторинга и размером базы мониторинга. Подробно об этом писали в прошлом году в статье «Эффективное использование журнала регистрации и технологического журнала 1С в решении вопросов производительности».
Ссылки на остальные части Записок оптимизатора 1С:
- Записки оптимизатора 1С (ч.1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
- Записки оптимизатора 1С (ч.2). Полнотекстовый индекс или как быстро искать по подстроке
- Записки оптимизатора 1С (ч.3). Распределенные взаимоблокировки в 1С системах
- Записки оптимизатора 1С (ч.4). Параллелизм в 1С, настройки, ожидания CXPACKET
- Записки оптимизатора 1С (ч.5). Ускорение RLS-запросов в 1С системах
- Записки оптимизатора 1С (ч.6). Логические блокировки MS SQL Server в 1С: Предприятие
- Записки оптимизатора 1С (ч.7). «Нелогичные» блокировки MS SQL для систем 1С предприятия
- Записки оптимизатора 1С (ч.8). Нагрузка на диски сервера БД при работе с 1С. Пора ли делать апгрейд?
- Записки оптимизатора 1С (ч.9). Влияние сетевых интерфейсов на производительность высоконагруженных ИТ-систем
- Записки оптимизатора 1С (ч.10): Как понять, что процессор — основная боль на вашем сервере MS SQL Server?
- Записки оптимизатора 1С (ч.11). Не всегда очевидные проблемы производительности на серверах 1С
- Записки оптимизатора 1С (ч.12). СрезПоследних в 1C: Предприятие на PostgreSQL. Почему же так долго?
- Записки оптимизатора 1С (ч.13). Что не так в журнале регистрации 1С в формате SQLite?
- Записки оптимизатора 1С (ч.14.1). Любите свою базу данных и не забывайте обслуживать
- Записки оптимизатора 1С (ч.14.2). Пересчет индексов на SSD–дисках. Делаем или игнорируем?
- Записки оптимизатора 1С (ч.14.3). Отличия в обслуживании статистик в MS SQL и в PostgreSQL